During the American election campaigns in 2016 fake news was the new big thing, with Russia being accused of orchestrating an intelligence campaign to influence the outcome of the presidential election. Regardless of what Russia did or did not do, spreading the message efficiently requires both that traditional media pick it up to grant it credibility, and that people share it on social media platforms to get as much coverage as possible. Machine learning can play many roles in this, and we will look at an obvious use case, which is pretty much the same way recommendations work on Netflix or Amazon – by use of feature-based labelling.
Any “news” article will have several features. Examples of features are:
- Language style (using a readability metric)
- Length of article (word count)
- Use of celebrities (none, light, medium, heavy)
- Visual intensity (none, light, medium, heavy)
- Shock factor (none, light, medium, heavy)
Let us say we consider a news article successful if it receives more than 100k shares on Facebook, or if it is quoted on CNN. So, our news articles can be SUCCESSFUL or NOT SUCCESSFUL depending on these criteria.
One simple but often efficient way we can use machine learning to understand what makes an article successful is to use existing data to train a decision surface. Say we have a collection of 200 news articles, and that we can check whether they are successful or not (they are labelled). This is our training set. Based on that, we can use statistics to find out which features will help us predict which label to apply to which data point. If we boil this down to two factors (language style and word count), we can create a scatter plot of these articles. By analyzing our set of training data, we seek to learn how we can exploit the factors to make our fake news spread. We have plotted our training data in a scatter plot to inspect it visually.

What we learn from simply looking at the plot is that the article should be fairly short, and intermediately difficult in readability (seems to be somewhere between 60 and 80 on the Flesch index, corresponding to articles that can be read by high school graduates).
Using a classification algorithm like the Naïve Bayesian classification algorithm, we can generate a decision surface based on our data.
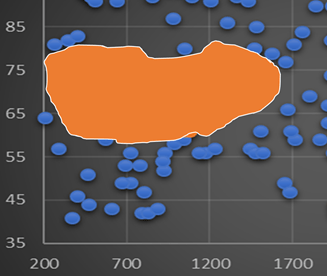
Everything that falls into the red region will be predicted as successful. Giving up on the ability to plot the features in a single scatter plot, we can feed the algorithm with our full feature set, allowing it to figure out more factors we should care about when creating our fake news campaign.
This shows that the same methods used to drive recommendation engines, can also be used to learn how to best influence people – useful both in marketing, and in trying to “rig elections”. By the way, this simple labeling of data using classifiers like above is one arm of machine learning, known as supervised learning. The data set used in this post was randomly generated – so it didn’t really teach you how to create efficient fake news articles – but it did show you how you can find out.