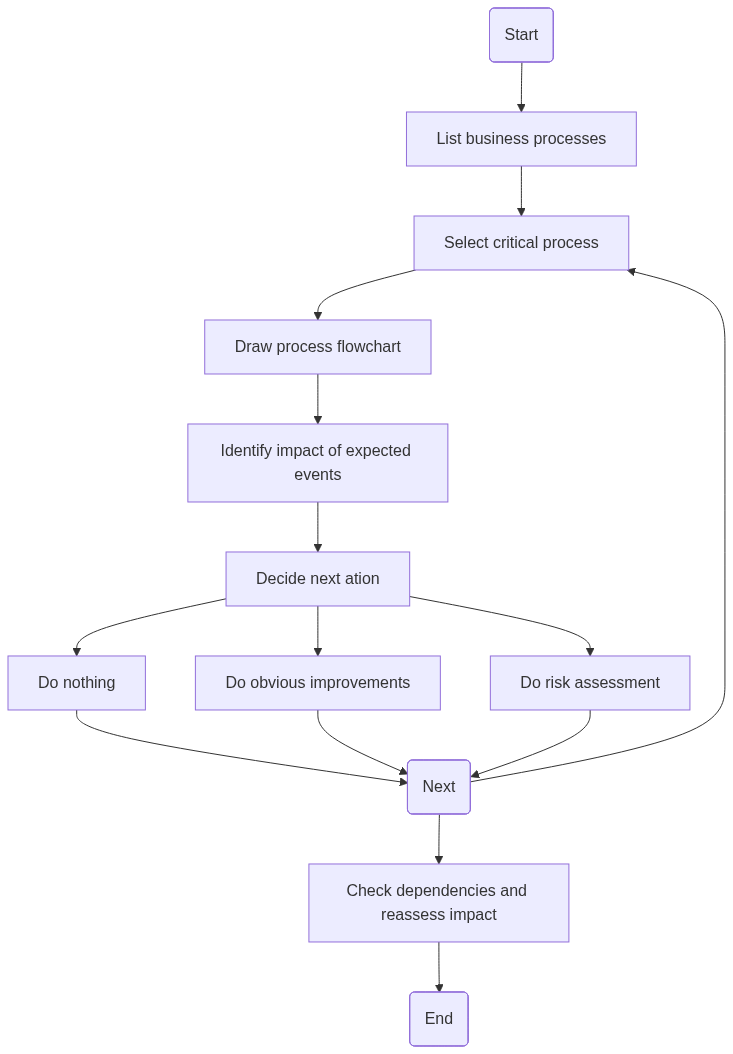
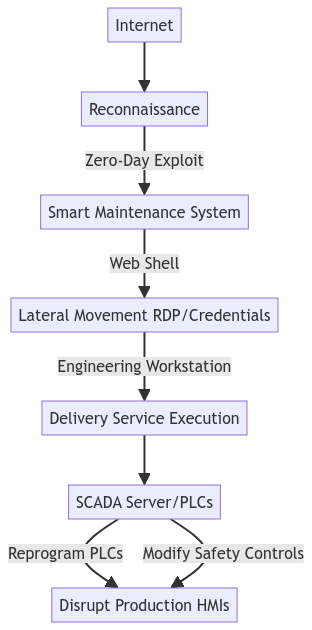
Your ability to get out on the other side of a cyber attack in one piece, depends a lot on your preparations. Preparing to handle an attacker that breaches your initial defences will include a number of activities:
- Building a defendable architecture
- Creating a way to detect attacks
- Having a plan for what to do when bad things happen
- Exercising that plan
Many organizations do a good job at bilding a reasonable defendable architecture, and also have some detection capabilities. Some have an incident response plan that they have never exercised – because planning and executing good exercises is hard work and taks time! But without exercises you don’t really know your plan, and you don’t know if the plan is actionable. Exercising is what makes your defendable architecture defended.
Speeding up exercise planning with AI
At work we have helped companies exercise for a long time, and the last couple of years we have had success using AI to significantly speed up exercise preparations and make them better. AI is also very helpful in war gaming exercises to generate realistic artefacts on the fly during an exercise. For now, let’s focus on how we can use AI to create good scenarios faster.
- We can use the AI to suggest scenarios and learning paths
- We can use the AI to generate artefacts to support the exercise – including deep fake videos, phishing emails, voice recordings, etc.
- We can use the Ai to match exercise content to actual descriptions of response plans and architectures
All of this can expose relatively sensitive data to the AI provider. Would you be OK with that? If the scenario is completely generic, nor harm done. But what if you want an exercise built on your actual architecture, real vulnerabilities and your actual response plans? Uploading all of that to a third-party company may not be what your CISO considers acceptable.
Please have your say on this in my one-question anonymous poll here: https://cryptpad.fr/form/#/2/form/view/NvaPgVGmKqoyx2Idfu9h4Jz3pYQs8fF8JrngIPw9ID8/.
– Help me understand what you would accept using!
A cloud first approach – easy and fast but is it acceptable?
As a test on how well an AI based app can support scenario development, I created a vibe coded prototype using Firebase services and Gemini. This app takes your description of a scenario, and can ingest response plans, network drawings, risk assessment reports etc., and generate a scenario in phases, with supporting artefacts like logs, emails, etc.
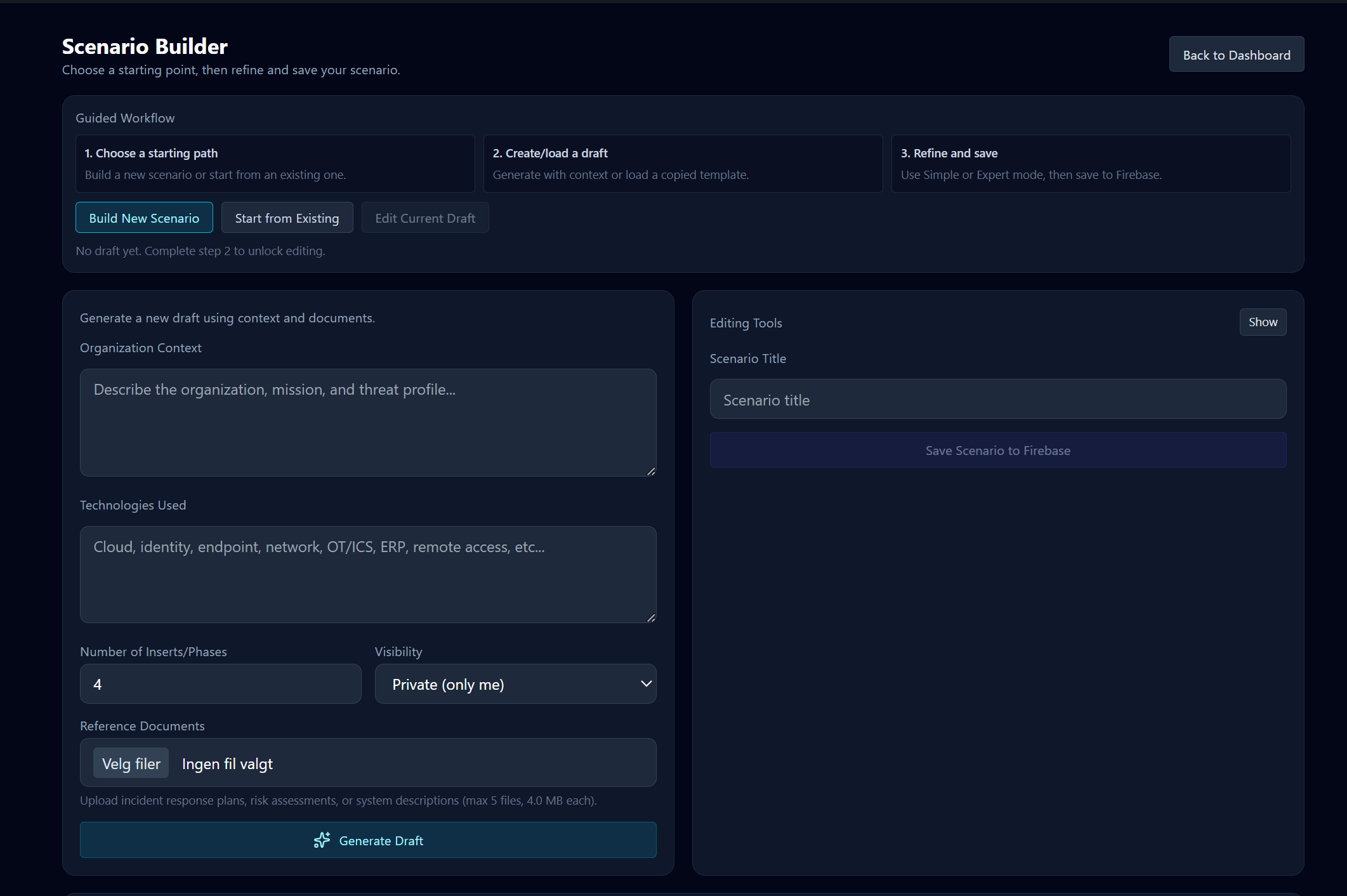
Technically this platform reduces the time to develop a great tabletop exercise from weeks to less than an hour. That is pretty amazing – but at the same time:
- Documents are uploaded to a cloud bucket for analysis
- Inference is done with a third-party AI service – how the data it is fed is used is quite hard to track and explain
- The scenario itself will contain details about the scenario that can reveal real architectural concepts, vulnerabilities, key dependencies, etc. This is stored in a cloud database.
- Access to the scenario during the exercise is protected by authentication – but is that good enough?
It isn’t obvious that using a cloud service for this use case is irresponsible – but proper security planning and transparency is very important!
This platform supports executing the exercise within the platform – including a built-in chat, AI advisor for various roles participating, generating a hotwash report – all very useful features in an exercise. But it is also possible to use AI systems to generate the exercise and to download it in more traditional formats, such as PowerPoint for local use. Then the files and data in the cloud can be deleted after generation and the time it is available to possible threat actors is significantly reduced.

PPT generated by AI in cloud system – is that better?
Less data in the cloud – less risky?
We can of course build AI supported processes with less cloud integration too.
- A local service using an external AI service. That avoids storing a lot of sensitive data in a cloud environment but still exposes sensitive data to a third-party AI service.
- A local service including local AI inference to generate scenarios. This avoids the cloud risk (but the model and local software can still be poisoned/malicious).
As an example – here’s another take on the “tabletop support application” where the user is able to choose between local and cloud based AI models.
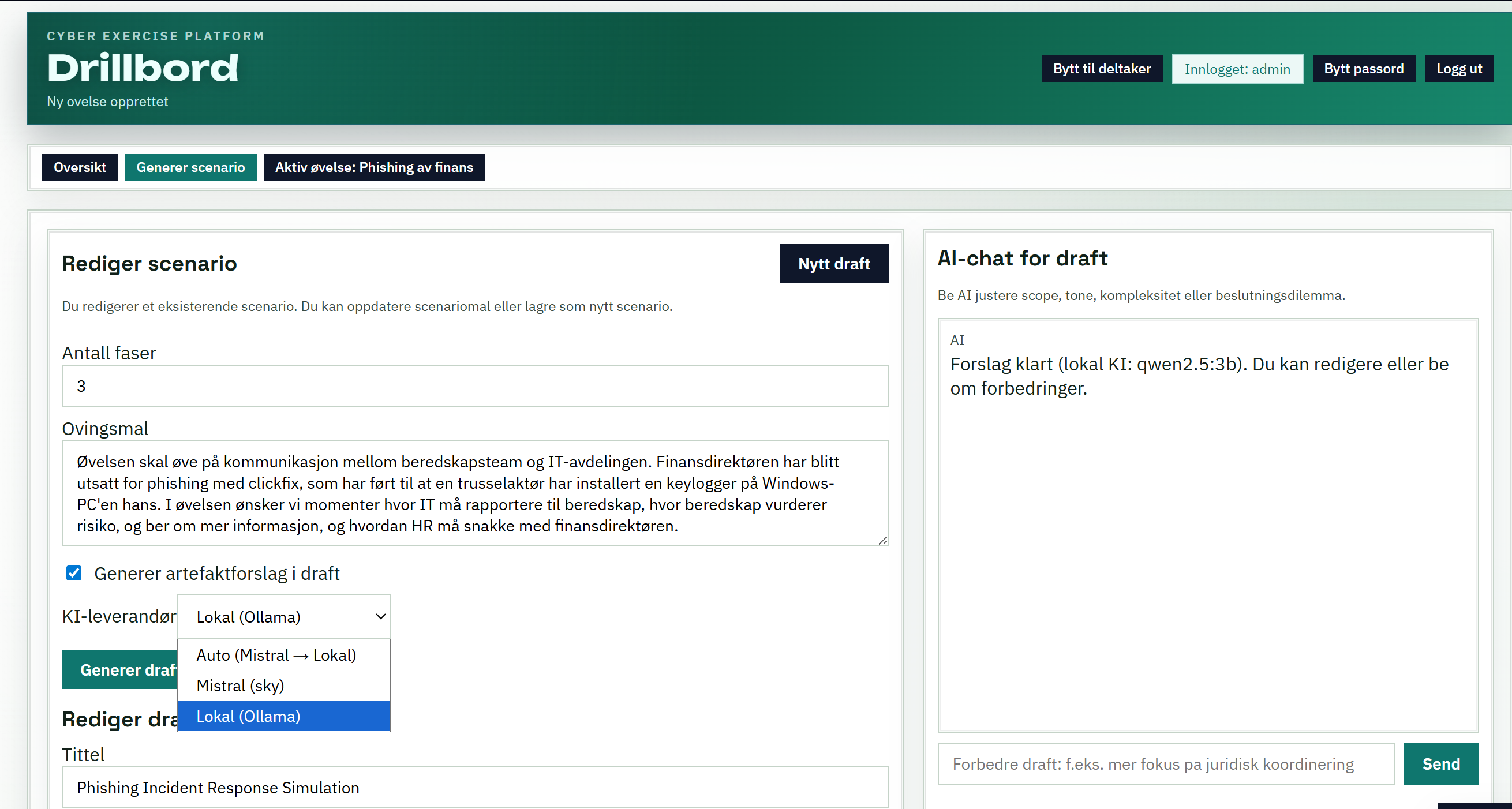
Threat modeling our options
As a threat actor, how would you try to exploit these tabletop applications? This is not a deep-dive but some considerations worth looking at.
- Cloud native application
- Try to get access to the cloud environment (identity breach)
- Get access to detailed data (files, chat logs from actual exercises, scenario details)
- Use data to plan attack on company
- On-prem app with cloud based AI provider
- Get access to the AI platform (identity breach)
- Locate logs that help you gain insight on data shared with the AI
- Look for file storage on AI platform, or auth mechanisms allowing access to SharePoint, etc
- Use data to plan an attack on the company
- On-prem app with local AI provider
- Attack the application itself
The actual risk exposure from the AI provider depends on the settings in the AI platform. The ability to control your data usage varies across platforms, subscription tiers, and what you actually configure.
In summary, no matter where you store your data, you need to take measures to protect them. This is also achievable using cloud services but it doesn’t happen automatically. The key control layers for data protection in the cloud itself would be identity, encryption and access control – all configurable by the cloud consumer. That said, running the exercise platform entirely locally can be a valid security strategy, depending on the threats you worry about. Using local model can even bring you the benefits of AI as an exercise partner in air gapped enviornments.
And will AI make your exercises better? Not automatically but it definitely can support the exercise team creating better, more realistic and dynamic exercise scenarios!
Endnote: tech that enables organizations to exercise will improve cyber resilience – even with slightly expanded technical attack surface. Plans without execution are useless.
– Me.
Technologies used for the experiments mentioned in this post
- AI Models at runtime
- Gemini Flash 2.5
- Gemini Pro 3.1
- Mistral-small-latest
- Mistral-medium-latest
- Qwen-2.5-3b
- AI models used to generate code for these prototype platforms
- Mistral Vibe (CLI coding agent from Mistral)
- GIthub Copilot with
- GPT-5.3-Codex
- Claude Sonnet 4.6
- AI providers
- Microsoft/Github (used in VSCode)
- Google Gemini (used in Gemini chat + in code)
- Mistral (used in Mistral Vibe + in code)
- Ollama (used to run local AI model in code)
- Cloud technologies
- Google Firebase with Firestore, Firebase Auth, Firebase Storage)
- Google AI Studio (Gemini API access)
- Mistral AI Studio (Mistral API access)
- Github for code repositories (private)
- Technology stack for apps
- Typescript/Vite/Fastify
- Playwright e2e tests
- Sqlite
![{
"@context": "https://schema.org",
"@type": "BlogPosting",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://safecontrols.blog/2026/01/01/supply-chain-security-transform-your-suppliers-from-swiss-cheese-to-fortress-in-12-months/"
},
"headline": "Supply Chain Security: Transform Your Suppliers from Swiss Cheese to Fortress in 12 Months",
"description": "A practical three-step guide to improving supplier cybersecurity posture, covering effective communication, posture assessment, and a 12-month strategic roadmap.",
"image": "https://safecontrols.blog/wp-content/uploads/2026/01/secure-trucking.png",
"author": {
"@type": "Person",
"name": "Håkon Olsen",
"url": "https://safecontrols.blog/author/hols3n/",
"jobTitle": "Risk Management & Cybersecurity Expert"
},
"publisher": {
"@type": "Organization",
"name": "safecontrols",
"logo": {
"@type": "ImageObject",
"url": "https://defaultcustomheadersdata.files.wordpress.com/2016/07/blur.jpg"
}
},
"datePublished": "2026-01-01",
"dateModified": "2026-01-01",
"keywords": "Supply Chain Security, Cybersecurity, Third-party Risk Management, NIS2, Information Security, Supplier Roadmap",
"articleSection": "Infosec",
"abstract": "Using suppliers with poor security posture is a major business risk. This article outlines a 12-month transformation plan to help suppliers implement critical security controls like 2FA, immutable backups, and network segmentation through a structured roadmap."
}
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "How can I help a supplier improve their cybersecurity posture?",
"acceptedAnswer": {
"@type": "Answer",
"text": "You can help suppliers through a three-step process: 1) Discuss why security matters to your business reliability, 2) Help them perform a light-touch posture assessment (covering technology, processes, and people), and 3) Collaborative creation of a 12-month security roadmap."
}
},
{
"@type": "Question",
"name": "What are the most critical security controls for small suppliers?",
"acceptedAnswer": {
"@type": "Answer",
"text": "A essential shortlist of security controls includes keeping devices updated, using two-factor authentication (2FA) on all internet-exposed services, maintaining regular immutable backups, segmenting internal networks, and ensuring users do not have administrative access for daily tasks."
}
},
{
"@type": "Question",
"name": "How long does it take to transform a supplier's security from weak to strong?",
"acceptedAnswer": {
"@type": "Answer",
"text": "A comprehensive transformation typically takes 12 months. The first 3 months should focus on closing critical technical gaps, the next 3 months on process and work-flow changes like network segmentation, and the final 6 months on accountability and competence building."
}
},
{
"@type": "Question",
"name": "What cybersecurity frameworks are recommended for supplier assessments?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Effective starting points include the ICT Security Principles of NSM (Norway), NIST CSF, ISO 27001, or the NCSC Cyber Essentials."
}
}
]
}](https://safecontrols.blog/wp-content/uploads/2026/01/secure-trucking.png?w=1024)