Sounds like a crazy idea, right? Research, however, has shown that about half of professional machine operators do not think safety functions are necessary. You know, things like panel limit switches, torque limiters and emergency stop buttons. Who would need that, right? This number comes from a report issued in Germany about 10 years ago, but I am not very optimistic in improvements in these numbers since then. The report can be found here: http://www.dguv.de/ifa/Publikationen/Reports-Download/BGIA-Reports-2005-bis-2006/Report-Manipulation-von-Schutzeinrichtungen/index.jsp (in German).
Machine safety is important for both users and bystanders. Manipulations of safety functions are common – and the risk increase is typically unknown to users and others. How can we avoid putting our people at risk due to degraded safety of our machinery?
Researchers have found that the safety functions of machines are frequently manipulated. This is typically done because workers perceive the manipulation as necessary to perform work, or to improve productivity. Everyone from machine builders, to purchasers to operrators should take this into account, to avoid accidents from happening. Consider for example a limit switch. A machine built to conform to the machinery directive (with CE marking) has to satisfy safety standards. Perhaps has a SIL 2 requirement been assigned to the limit switch because operation without it is deemed dangerous and a 100-fold risk reduction is necessary for operation to be acceptable. This means, if the limit switch is put out of function, the risk of operation is 100 times higher than the designer has intended!
What can we do about this? We need to design machine such that safety functions become part of the work flow – not an obstacle to it. If workers have nothing to gain in their own perception from manipulating the machine, they are not likely to do it either. This boils down to something we are aware of, but are not good enough at taking into account in design processes; usability testing is essential not only to make sure operators are happy with the ergonomics – it is also essential for the safety of the people using the machine!
Functional safety work usually involves a lot of people, and multiple organizations. One key success factor for design and operation of safety instrumented systems is the competence of the people involved in the safety lifecycle. In practice, when activities have been omitted, or the quality of the work is not acceptable, this is discovered in the functional safety assessment towards the end of the project, or worse, it is not discovered at all. The result of too low quality is lower integrity of the SIS as a barrier, and thus higher risk to people, assets and environment – without the asset owner being aware of this! Obviously a bad situation.
Knowing how to do your job is important in all phases of the safety lifecycle. Functional safety audits can be an important tool for verification – and for motivating organization’s to maintain good competence mangement systems for all relevant roles.
Competence management is a key part of functional safety management. In spite of this, many companies have less than desirable track records in this field. This may be due to ignorance, or maybe because some organizations view a «SIL» as a marketing designation rather than a real risk reduction measure. Either way – such a situation is unacceptable. One key tool for ensuring everybody involved understands what their responsibilities are, and makes an effort to learn what they need to know to actually secure the necessary system level integrity, is the use of functional safety audits. An auditing program should be available in all functional safety projects, with at least the following aspects:
A procedure for functional safety audits should exist
An internal auditing program should exist within each company involved in the safety lifecycle
Vendor auditing should be used to make sure suppliers are complying with functional safety requirements
All auditing programs should include aspects related to document control, management of change and competence management
Constructive auditing can be an invaluable part of building a positive organizational culture – where quality becomes as important to every function involved in the value chain – from the sales rep to the R&D engineer.
One day statements like “please take the chapter on competence out of the management plan, we don’t want any difficult questions about systems we do not have” may seem like an impossible absurdity.
Risk based asset management frameworks force us to be systematic in our approach. Multiple layers of defense are commonly applied to mitigate risks down to what we see as an acceptable level. In many cases it will feel like each layer of defense is a layer of inconvenience.
Do we maximize the number of spikes (or layers of protection) to feel safe?
The ALARP principle is often used to evaluate if a certain defense layer is worth the investment. This type of analysis tends to be CAPEX focused. Very cumbersome operations tend to make people invent bypasses that are more convenient. In addition to investment cost, maybe we should also include the effect of the mitigation solution on convenience and how humans react to it, in addition to cost? If people bypass the intended operating procedure – the result of the new risk mitigation investment could be an increase in the overall risk.
Human factors researchers have taken interest in cyber security. This is good, because we need to think about most attacks in terms of both technology and psychology on both sides of the fence. Phishing emails is the most common initial attack strategy used in targeted attacks. It is therefore important to make your people able to avoid such deception.
Understanding the difference between gold and trash is the main way to avoid phishing
A recent paper in the August issue of “Human Factors” by Proctor and Chen discusses decision making in detection of phishing. A key factor found by researchers is that a mismatch between cues in a phishing email and the expectations the recipients have is crucial to detecting a phishing attempt. Such cues are typically technology related such as strange URL’s, errors in corporate identity, slight misuse of terminology. It may this be questioned if awareness training by itself is an effective mitigation element – people need to know their domains well too, as well as what to expect of URL’s and technology solutions from emails and web sites.
Make sure your people do not feel like a hot kettle with nowhere to let the steam out – that can lead to broken designs – and if your line of work is designing safety critical systems, broken designs usually means a greater chance of loss of life, polluting the environment and large financial losses.
Having a way to control the internal steam pressure of your team members may be utopia – but you should still look for ways to avoid disasters, together with your people.
We all know that the quality of our work varies – with a large number of factors. If we are overworked or really worried about something in our personal lives – quality of our work will most likely suffer. If you are responsible for the functional safety in a large project, human error can be disastrous, not only for the project, but for the people working in the plant when it has become operational. Whether it is yourself, or an entire team that you are responsible for, you need to be aware of key performance shaping factors. These factors are described in detail in human reliability analysis, such as developed by Idaho National Labs for the nuclear industry: http://www.nrc.gov/reading-rm/doc-collections/nuregs/contract/cr6883/cr6883.pdf. These techniques can lend some terminology and thinking that is useful in the project itself, to help manage the risk of significant human errors in the project phase. Remember – misunderstanding the risk factors and barrier elements themselves may lead to insufficient barriers against major accident hazards in a real plant! The factors in the SPAR-H methodology described in the linked document are:
Available time
Stress/stressors
Complexity
Experience/training
Procedures
Ergonomics/HMI
Fitness for duty.
Work processes
These factors have been defined for typical process operators’ actions in a nuclear power plant but they are also relevant for other types of tasks. Functional safety work typically has a high degree of complexity. The experience and training of people involved in the safety lifecycle tend to vary a lot, and procedures and work processes are not always clear to everyone involved. All of this falls under “management of functional safety” and project managers should think about what creates great quality when planning and managing the project. In many projects, time is quite limited, and the term “schedule impact” is a rather frightening concept to many project managers. This can lead to tasks being perceived as less important simply because the schedule is prioritized over quality. For safety critical tasks, this should not be allowed to happen.
Some factors from your project members’ personal lives may have severe impact on performance. People working on the project team can be stressed or not “fit for duty” due to a number of challenges that are not only work related. How can we deal with this? Project managers need to know their teams beyond their tasks and work backgrounds. You need to create an environment of trust, such that you have a greater chance of catching such performance limiting factors originating from outside the organization. For many people these factors may not be something that is seen as “bad” such as divorce, alcohol abuse or depressions, it may simply be challenges in making daily life work. People tend to want balance in life – with room for work, family, friends, hobbies, etc., etc. Working in a high-stakes project may itself be a threat to a balanced life. By knowing your people you can help them find the necessary balance that will also improve their performance at work. Flexible work-hours, part-time telecommuting and close follow-up with real feedback to every member on your team can help.
We consider human factors and the effect of the work environment as well as external performance shaping factors for operators. We should also strive for people to perform at their best when their work is to design the very systems used by the operators after commissioning.
Defining process safety should be quite straightforward. However, what people mean with this term can vary quite a lot, and what to include in the term depends a lot on the understanding people have of the anatomy of severe accidents. Personally, I have met the following different understandings of the topic:
Process safety is what is governed by API 521 (basically steel strength and dimensioning of pressure relief valves)
Process safety is the technical measures taken to stop an accident from occurring
Process safety is the sum of organizational and technical systems involved in mitigating risk of major accidents
The first statement is obviously too narrow – especially as we know that more than half of accidents are down to human factors! Definition number 2 is a traditional view, and slightly more mature as it includes both the safety instrumented system and alarm management (to a certain extent). The last definition is maybe the most “modern”, and includes organizational culture, safety leadership as well as the technologies included in the first and second definitions.
How people understand the term “process safety” tends to mature over time – from a strictly technical view to a more holistic view including both individual and organizational factors, as well as the technologies and how they are used in a system. A walk up this staircase from the technology focused to a more holistic view can take a long time but conscious reflection can help speed the path to improved performance and risk management.
A complete understanding of barrier systems, which is really what risk management is about, requires an understanding of which factors are influencing accident risk, and what can be done to mitigate the risk. This requires that the asset owner thinks not only about “proof testing”, “compliance” or “asset management”, but also about:
Leadership
Barrier integrity
Maintenance
Monitoring
Design
Competence management
Permit to work system
Dynamics of plant and controls in normal and degraded modes
Etc, etc, etc.
In other words – to keep risk under control you need to take the full complexity of your operations into account. A purely technical view on process safety is thus simply not good enough.
People frequently (heh, heh) define risk as the product of consequences and probabilities of uncertain or stochastic events:
RISK = CONSEQUENCE x PROBABILITY
This has led to a range of risk metrics and ways to compare risk with acceptance criteria. For technical safety risk, there is typically an acceptable frequency defined per consequence category. In a risk analysis, catastrophic events may for example be acceptable with a frequency no higher than one event per one million years. Recently, cyber security risk assessments have become more common also for operators of technical systems, such as waste water treatment plants, intelligent homes or oil and gas production rigs. Obviously, cyber threats are real and intruders can hit you just as hard as a random hardware failure – such as the steel mill in Germany that was hit by an advanced cyber attack originating on an external network. Asset owners have slowly come to realize this – and some of them are trying to use their established risk management frameworks also for cyber threats – only to discover that is really hard to do that. Why is this not a good approach?
Consider the following event scenario: intruder manages to steer your update call to a rogue patch server by a fake internal DNS server, pushing a corrupt Windows patch to your system, thereby gaining admin access to your engineering workstations… how do you assess the frequency of this scenario? Once every 1 million years? Weekly? Obviously, applying the concept of “frequency” as a measure of probability is not the best of ideas in this domain. This has led many people to think “probabilities cannot be used for cyber risks”. This again begs the question – if you do not know if a scenario is likely or extremely unlikely to occur – how do you decide how to allocate your resources when designing counter measures?
What if an attacker can take control over all your port cranes? When deciding which counter-measures to take, you would most likely like to know if such an attack is highly credible or merely a remote probability (all puns intended.. J )! (Photo taken in the harbor of Hamburg, May 2015).
A more reasonable concept is maybe to consider how “credible” a scenario is – rather than a frequency of occurrence. This is also how academics tend to look at the topic; we can rank threat scenarios according to how credible they are. An interesting thing that separates risks related to targeted cyber attacks from typical technical risk analysis is that the credibility (or probability) of an attack taking place is not independent of the consequence of this event; the reason the attack occurs is that somebody wants to hurt you. They may be more motivated if the consequences are worse for you! Things to consider when deciding if an attack or a threat is credible are:
Who is the attacker?
What is the motivation of the attacker?
Does the attacker have the necessary resources (money, people, technical equipment, etc)?
Does the attacker have a positive cost-benefit relationship (as seen from the bad guy’s point of view)?
Does the attacker have the necessary skills or access to the necessary skills to perform the attack?
Armed with this, you should be able to form a reasonably well informed estimate of the probability – or credibility – of an identified attack such as the one above.
I will be taking more about this at the next ESREL conference, together with colleagues from LR! Maybe I’ll see you in Zürich in September?
Everybody knows that you need to maintain your stuff to make sure it is in top condition; a colloquial way of saying that maintenance is a necessary component of any highly reliable system. In practice, there are three quite common approaches to maintenance of technical systems:
If it ain’t broke don’t fix it
Periodic inspection and maintenance
Risk based maintenance
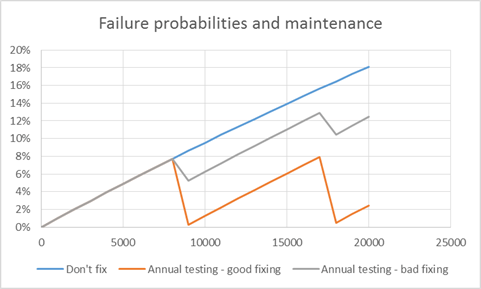
The first policy is the most commonly applied in private life. The only reason this is at all possible is a combination of high labor cost, relatively cheap mass production of many things, and that insurance companies allow you to do it by paying for stuff that “accidentally” breaks. For reliability, this policy is clearly the least reasonable, and it will negatively affect the reliability of your system. The following picture shows an example of the degradation that may occur when following this policy – taken from a walk in the Danish countryside.
The second policy is maybe the most commonly applied in industry – and for conscious car owners. You take your car to the mechanic once per year, or perhaps every 25000 km, for oil change and a check-up. You test the most important things, and follow up if necessary. This ensures your reliability is not negatively affected by lack of maintenance – but still the work has to be performed with high quality. Maintenance done right reduces probability of severe failures, done wrong it is outright dangerous.
Risk based maintenance uses available data to judge the risk level for your equipment – by using a combination of information gained from inspections and direct measurements. When you actively monitor the risk of failures and plan maintenance activities in accordance with real risks, you can prolong the useful life of your system while maintaining the necessary reliability.
When assessing the reliability of critical systems you should thus include both the philosophy of maintenance and the ability of the organization to execute the maintenance plan in a good way in your assessment. A simple illustration of this is shown in the below picture.
The source of bad security in an IT system is software. Vulnerabilities exist primarily because of two things:
design flaws
Implementation errors – that is, programming mistakes
The tools we have for fighting such vulnerabilities all belong in the “quality assurance” box. However, no matter how good we are at coding and all that comes with it, software will always ship with hidden bugs. Whenever such a bug is discovered and it is a security vulnerability, it is only a question of time before exploit code becomes available. The software vendor rushes to stuff the hole and push a patch to the users. This helps only if users actually update their systems.
The average time from a patch is released until it is installed in businesses is 6 months. That’s like not changing locks before half a year after known thieves got away with your front door key.
Procurement is easy – getting exactly what you need is not. I have previously discussed the challenges related to follow-up of suppliers of SIL rated equipment on this blog, but that was from the perspective of an organization. This time, let’s look at what this means for you, if you are either the purchaser or the package engineer responsible for the deliverable. Basically there are three challenges related to communication in procurement of SIL rated equipment – or procurement of anything for that matter;
The purchaser does not understand what the project needs
The customer does not understand what the purchaser needs
The package engineer does not know that the purchaser does not know what the project needs, and therefore he or she does also not know that the supplier does not know what the project actually needs
This, of course, is recipe for a lot of quarreling and time wasted on finger pointing and the blame game. All of this is expensive, frustrating and useless. What can we do to avoid this problem in the first place? First, everybody needs to know a few basic things about SIL. The standards used in industry are quite heavy reading, and when guidelines for your industry are available, it is a good idea to use them. For the oil and gas industry, the Norwegian Oil & Gas Association’s Guideline No. 070 is a very good starting point. To distill it down to a bare minimum, the following concepts should be known to all purchasers and package engineers:
Why does a safety integrity level requirement exist for the function your equipment is a part of?
What is a safety integrity level (SIL) in terms of:
Quantitative requirements (PFD quota for the equipment)
When this is known, communication between purchaser and supplier becomes much easier. It also becomes easier for the package engineer and the purchaser to discuss follow-up of the vendors and what requirements should be put in the purchase order, as well as in the request for proposal. Most projects will develop a lot of functional safety documents. Two of the most important ones in the purchasing process are:
Safety Requirement Specification (SRS): In this document you find a description of the function your component is a part of, and the SIL requirements to the function. You will also find allocated PFD quotas to each component in the function – this is an important number to use in the purchasing process.
A “Vendor guideline for Safety Analysis Reports” or a “Safety Manual Guideline” describing the project’s documentation requirements for SIL rated equipment
So, what can you do to bring things into this nice and orderly state? If you are a purchaser, take a brief SIL primer, or preferably, ask your company’s functional safety person to give you a quick introduction. Then talk to your package engineer about this things when setting out the ITT. If you are a package engineer, invite your purchaser for a coffee, to discuss the needs of the project in terms of these things. If the purchaser does not understand the terminology, be patient and explain. And remember that not everybody has the right background; the engineer may fail to understand some technical details of the purchasing function, and the purchaser may not understand the inner workings of your compressor – but aiming for a common platform to discuss requirements and follow-up of vendors will make life easier for both of you.