
I have not been feeling well the last few days, and taken some sick days. The upside of that is time on the coach researching stuff on my laptop without needing to be “productive”. Yesterday I did a dive into the History file in Edge, looking at how URL’s and browser history is saved. Today I decided to continue that expedition a bit, to look into the downloads history, as well as search terms typed into the address bar.
Downloads – when did they happen?
Sometimes you would like to investigate which files have been downloaded on a computer. A natural way to do this is to look in the downloads folder of the user. However, if the files have been deleted from that folder, it may not be so easy to figure out what has happened. A typical malware infection could be to trick someone into downloading a malicious file and then executing it.
If we again turn to the History file of Edge, we can check out the downloads table. It has a lot of fields, but some of the interesting ones are:
- id
- target_path
- start_time
- tab_url
Immediately interesting property for forensics investigations is that we can check with start_time when the download occurred. We also have access to the URL of the download, from tab_url, as well as where it was linked from.
To test how well this works, I am going to download a file to a non-standard location.
select id, tab_url, target_path, datetime(start_time/1000000 + (strftime('%s','1601-01-01')),'unixepoch','localtime') from downloads;The result is:
6|https://snabelen.no/deck/@eselet/111257537583580387|C:\Users\hakdo\Documents\temp\HubSpot 2023 Sustainability Report_FINAL.pdf|2023-10-18 20:55:16This means that I downloaded the file from a Mastodon post link, but this is not the origin of the file.

It seems we are able to get the actual download URL from the downloads_url_chain table. This table seems to have the same id as the downloads table.
sqlite> select id, tab_url from downloads where id=6;
6|https://snabelen.no/deck/@eselet/111257537583580387
sqlite> select * from downloads_url_chains where id=6;
6|0|https://www.hubspot.com/hubfs/HubSpot%202023%20Sustainability%20Report_FINAL.pdfThen we have the full download link.
In other words, we can based on these tables get:
- When the download occurred
- Where it was stored on the computer
- What page the link was clicked on
- What the URL of the downloaded file was
That is quite useful!
Searches typed into the address bar
The next topic we look at is the table keyword_search_terms. This seems to be the keywords typed into the address bar of the Edge browser to search for things. The schema shows two column names of particular interest: url_id, term. The url_id only gives us the ID from the urls table, so we need to use an inner join here to find the actual search string. Here’s an example:
sqlite> select term, url_id, url from keyword_search_terms inner join urls on urls.id=keyword_search_terms.url_id order by id desc limit 1;The result is:
site:hubspot.com filetype:pdf|801|https://www.bing.com/search?q=site%3Ahubspot.com+filetype%3Apdf&cvid=1357bb7a2e544bb2bda6d557120ccf8c&gs_lcrp=EgZjaHJvbWUyBggAEEUYOTIGCAEQRRg60gEJMjIzNjdqMGo5qAIAsAIA&FORM=ANAB01&PC=ACTSGoing through someone’s search terms is of course quite invasive, and we should only do that when properly justified and with a sound legal basis. Here are some situations where I think this could be helpful and acceptable:
- There has been an insider incident, and you are investigating the workstation used by the insider. Probably still will require that the end user is informed, perhaps also concent, depending on the legal requirements at your location
- An endpoint was compromised through a malicious download, and the link to the download came from a search engine. The attacker may have used malicious search engine optimization to plant malicious links on a search engine page
Here’s a potential case where you may want to have a look at the search terms. A user downloaded a malicious document and executed it. When investigating, you found out that the link came from a search engine result page. You would like to check the searches done that led to this page, as the malware may have been targeting specific searches to your business or business sector.
For the sake of the example I now changed the default search engine in Edge from Bing to Duckduckgo. Then I did a search and downloaded a PDF file directly from the search results. Using an SQL search to find the latest download we get:
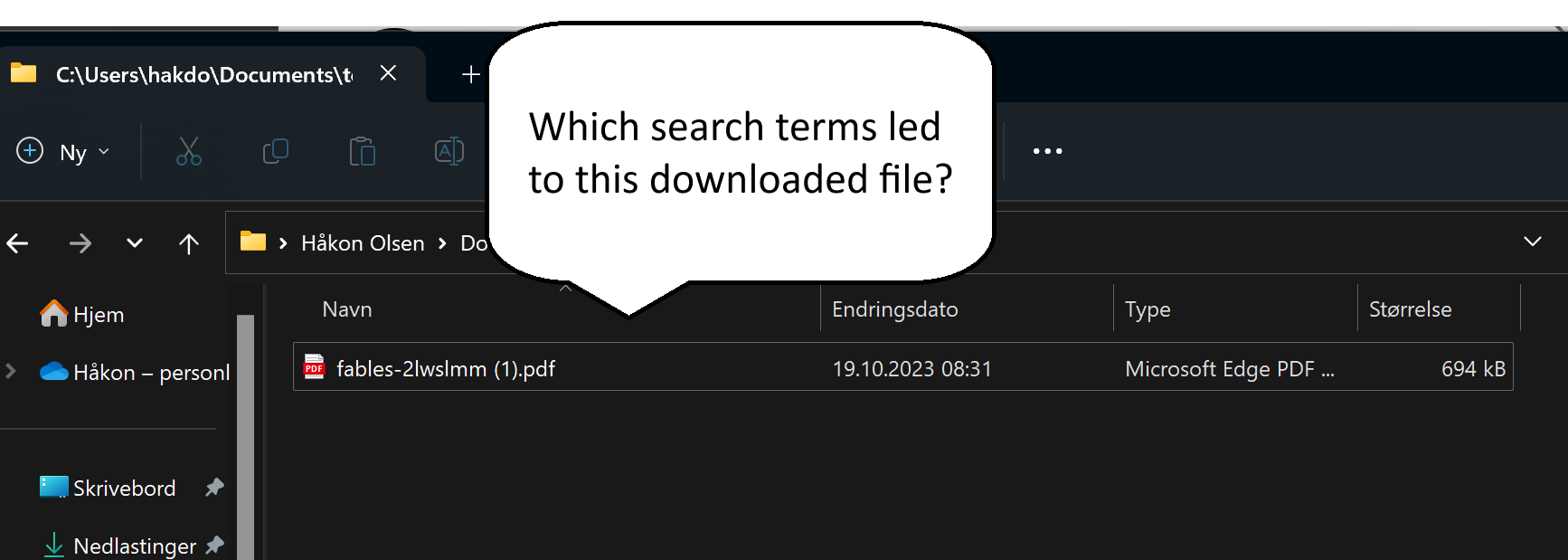
sqlite> select id, tab_url, target_path, referrer from downloads order by id desc limit 1;8|https://duckduckgo.com/?q=evil+donkey+filetype%3Apdf&ia=web|C:\Users\hakdo\Documents\temp\fables-2lwslmm (1).pdf|https://duckduckgo.com/Then we may want to know where this file came from, and again we turn to the downloads_url_chains table:
select * from downloads_url_chains where id=8;8|0|https://cpb-us-w2.wpmucdn.com/blogs.egusd.net/dist/e/211/files/2012/07/fables-2lwslmm.pdfNow we know already here what has been downloaded. We can also see from the query string above what the search terms were (“evil donkey” and “filetype:pdf”). If we have reason to believe that the attacker has poisoned results relating to evil donkey searches, we may want to look at the searches done by the user.
sqlite> select * from keyword_search_terms where term like '%donkey%';
5|819|evil donkey filetype:pdf|evil donkey filetype:pdf
5|820|evil donkey filetype:pdf|evil donkey filetype:pdfThat is one specific search – if searching for “evil donkeys” is something that this company could be expected to do, but would in general be very unusual (I suspect it its), this could be an initial delivery vector using malicious SEO.
Note that the default behavior in Edge is to open a PDF directly in the browser, not to download it. In this case, the search engine URL would not show up as referrer in the downloads record, but the direct link to the document on the Internet.
The second column in the result above is a reference to the ID in the urls table, so more information about the search performed (including time it was executed) can be found there. For example, if we want to know exactly when the user searched for evil donkeys, we can ask the urls table for this information.
select datetime(last_visit_time/1000000 + (strftime('%s','1601-01-01')),'unixepoch','localtime') from urls where id=819;The answer is that this search was executed at:
2023-10-19 08:31:28I hope you enjoyed that little browser History file dissection – I know a lot more about how Edge manages browser history data now at least.

[…] You may also want to read part 2 of this post – Edge history forensics – part 2 (downloads and search). […]
LikeLike