
There is one post on this blog that consistently receives traffic from search engines; namely this post on the effect of uncertainty on PFD calculations in reliability engineering: https://safecontrols.wordpress.com/2015/07/21/uncertainty-and-effect-of-proof-test-intervals-on-failure-probabilities-of-critical-safety-functions/

It is interesting to see the effect on the dynamic probability of failure on demand from a theoretical perspective. Consider now instead the problem of collecting operational data and adjusting the test intervals to optimize uptime while keeping within the PFD constraints given by the SIL requirement. To do this in a robust manner, one must take the uncertainty in the data into account. We are seeking to solve this problem:
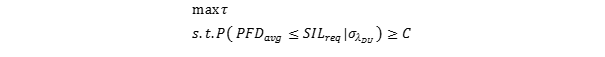
In other words; maximize the test interval while keeping the upper confidence bound on the average value of the PFD above the set value C, given that the standard deviation of the rate of dangerous undetected failures is known. To make things more practical, we consider a simple SIL loop where the PFD value is dominated by the final element. We make the simplification, for the sake of the calculation, that a single component is the loop. Let us then assume we have 20 valves of the same type that have operated over an aggregated 400 000 hours, and we have a theoretical failure rate of 10-6 per hour for these valves. We have not had any real demand trips, and the original test frequency was once per year. Testing has revealed that one valve had a dangerous failure in its first year of operation. Can we use this to extend the test interval without increasing the risk to our assets?
A naïve estimate the failure rate based on our observations indicate a failure rate of 1.25 x 10-6, which is obviously better than the a posteriori estimate from the design data. However, the design data is based on a larger data set and should not be disregarded if we wish to be reasonably sure about our decisions. So, the expected mean time to failure would be somewhere between 114 years and 913 years – a significant difference. SINTEF has released a report that gives a simplified approach to updating the failure rate. This approach requires you to define a conservative estimate of the failure rate based on the a priori data – often chosen to be the double of the original failure rate: λDU_CE = 2 λDU. Uncertainty parameters are then calculated based on the Gamma distribution as

Then the combined (updated) failure rate estimate is given as
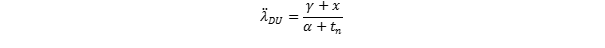
where is the number of dangerous failures observed, and is the aggregate operational time. Using this on our example gives us

What is going on here – the combined failure rate is higher than the a priori? The expected number of failures in 400.000 hours with an a priori MTTF of 1 million hours is clearly less than 1 – and we had one failure. So the estimate is sound. SINTEF’s methodology will give you lots more details, including credibility intervals for the Bayesian updates.
So – now to the test intervals – if the new combined failure rate is accepted – we should probably test more often, right? It depends, SINTEF argues that it is important to be conservative when updating test intervals to make sure insufficient data do not lead us astray. They propose the following simple rule:
If the new failure rate is less than half of the original failure rate, and the upper 90% confidence bound on the new failure rate is lower than the a priori failure rate, the test interval can be doubled.
If the failure rate is more than double the original failure rate, and the lower 90% confidence bound on the new failure rate is higher than the a priori failure rate, the test interval can be halved (e.g. from one year to every 6 months).
This means that in our case – the test interval stays the way it is.
