The way we write, deploy and maintain software has changed greatly over the years, from waterfall to agile, from monoliths to microservices, from the basement server room to the cloud. Yet, many organizations haven’t changed their security engineering practices – leading to vulnerabilities, data breaches and lots of unpleasantness. This blog post is a summary of my thoughts on how security should be integrated from user story through coding and testing and up and away into the cyber clouds. I’ve developed my thinking around this as my work in the area has moved from industrial control systems and safety critical software to cloud native applications in the “internet economy”.
What is the source of a vulnerability?
At the outset of this discussion, let’s clarify two common terms, as they are used by me. In very unacademic terms:
- Vulnerability: a flaw in the way a system is designed and operated, that allows an adversary to perform actions that are not intended to be available by the system owner.
- A threat: actions performed on an asset in the system by an adversary in order to achieve an outcome that he or she is not supposed to be able to do.
The primary objective of security engineering is to stop adversaries from being able to achieve their evil deeds. Most often, evilness is possible because of system flaws. How these flaws end up in the system, is important to understand when we want to make life harder for the adversary. Vulnerabilities are flaws, but not all flaws are vulnerabilities. Fortunately, quality management helps reduce defects whether they can be exploited by evil hackers or not. Let’s look at three types of vulnerabilities we should work to abolish:
- Bugs: coding errors, implementation flaws. The design and architecture is sound, but the implementation is not. A typical example of this is a SQL injection vulnerability in a web app.
- Design flaws: errors in architecture and how the system is planned to work. A flawed plan that is implemented perfectly can be very vulnerable. A typical example of this is a broken authorization scheme.
- Operational flaws: the system makes it hard for users to do things correctly, making it easier to trick privileged users to perform actions they should not. An example would be a confusing permission system, where an adversary uses social engineering of customer support to gain privilege escalation.
Security touchpoints in a DevOps lifecycle
Traditionally there has been a lot of discussion on a secure development lifecycle. But our concern is removing vulnerabilities from the system as a whole, so we should follow the system from infancy through operations. The following touchpoints do not make up a blueprint, it is an overview of security aspects in different system phases.
- Dev and test environment:
- Dev environment helpers
- Pipeline security automation
- CI/CD security configuration
- Metrics and build acceptance
- Rigor vs agility
- User roles and stories
- Rights management
- Architecture: data flow diagram
- Threat modeling
- Mitigation planning
- Validation requirements
- Sprint planning
- User story reviews
- Threat model refinement
- Security validation testing
- Coding
- Secure coding practices
- Logging for detection
- Abuse case injection
- Pipeline security testing
- Dependency checks
- Static analysis
- Mitigation testing
- Unit and integration testing
- Detectability
- Dynamic analysis
- Build configuration auditing
- Security debt management
- Vulnerability prioritization
- Workload planning
- Compatibility blockers
- Runtime monitoring
- Feedback from ops
- Production vulnerability identification
- Hot fixes are normal
- Incident response feedback
Dev environment aspects
If an adversary takes control of the development environment, he or she can likely inject malicious code in a project. Securing that environment becomes important. The first principle should be: do not use production data, configurations or servers in development. Make sure those are properly separated.
The developer workstation should also be properly hardened, as should any cloud accounts used during development, such as Github, or a cloud based build pipeline. Two-factor auth, patching, no working on admin accounts, encrypt network traffic.
The CI/CD pipeline should be configured securely. No hard-coded secrets, limit who can access them. Control who can change the build config.
During early phases of a project it is tempting to be relaxed with testing, dependency vulnerabilities and so on. This can quickly turn into technical debt – first in one service, then in many, and at the end there is no way to refinance your security debt at lower interest rates. Technical debt compounds like credit card debt – so manage it carefully from the beginning. To help with this, create acceptable build thresholds, and a policy on lifetime of accepted poor metrics. Take metrics from testing tools and let them guide: complexity, code coverage, number of vulnerabilities with CVSS above X, etc. Don’t select too many KPI’s, but don’t allow the ones you track to slip.
One could argue that strict policies and acceptance criteria will hurt agility and slow a project down. Truth is that lack of rigor will come back to bite us, but at the same time too much will indeed slow us down or even turn our agility into a stale bureaucracy. Finding the right balance is important, and this should be informed by context. A system processing large amounts of sensitive personal information requires more formalism and governance than a system where a breach would have less severe consequences. One size does not fit all.
User roles and stories
Most systems have diffent types of users with different needs – and different access rights. Hackers love developers who don’t plan in terms of user roles and stories – the things each user would need to do with the system, because lack of planning often leads to much more liberal permissions “just in case”. User roles and stories should thus be a primary security tool. Consider a simple app for approval of travel expenses in a company. This app has two primary user types:
- Travelling salesmen who need reimbursements
- Bosses who will approve or reject reimbursement claims
In addition to this, someone must be able of adding and removing users, granting access to the right travelling salesmen for a given boss, etc. The system also needs an Administrator, with other words.
Let’s take the travelling salesman and look at “user stories” that this role would generate:
- I need to enter my expenses into a report
- I need to attach documentation such as receipts to this report
- I need to be able of sending the report to the boss for approval
- I want to see the approval status of my expense report
- I need to recieve a notification if my report is not approved
- I need to be able of correcting any mistakes based on the rejection
Based on this, it is clear that the permissions of the “travelling salesman” role only needs to give write access to some operations, for data relating to this specific user, and needs read rights on the status of the approval. This goes directly into our authorization concept for the app, and already here generates testable security annotations:
- A travelling salesman should not be able to read the expense report of another travelling salesman
- A travellign salesman should not be able of approving expense reports, including his own
These negative unit tests could already go into the design as “security annotations” for the user stories.
In addition to user stories, we have abusers and abuse stories. This is about the type of adversaries, and what they would like to do, that we don’t want them to be able of achieving. Let’s take as an example a hacker hired by a competitor to perform industrial espionage. We have the adversary role “industrial espionage”. Here are some abuse cases we can define that relate to motivation of a player rather than technical vulnerabilities:
- I want to access all travel reports to map where the sales personnel of the firm are going to see clients
- I want to see the financial data approved to gauge the size of their travel budget, which would give me information on the size of their operation
- I’d like to find names of people from their clients they have taken out to dinner, so we know who they are talking to at potential client companies
- I’d like to get user names and personal data that allow med to gauge if some of the employees could be recurited as insiders or poached to come work for us instead
How is this hypothetical information useful for someone designing an app to use for expense reporting? By knowing the motivations of the adversaries we can better gauge the credibility that a certain type of vulnerability will be attempted exploited. Remember: Vulnerabilities are not the same as threats – and we have limited resources, so the vulnerabilities that would help attackers achieve their goals are more important to remove than those that cannot easily help the adversary.
Vulnerabilities are not the same as threats – and we have limited resources, so the vulnerabilities that would help attackers achieve their goals are more important to remove than those that cannot easily help the adversary.
Tweet
Architecture and data flow diagrams
Coming back to the sources of vulnerabilities, we want to avoid vulnerabilities of three kinds; software bugs, software design flaws, and flaws in operating procedures. Bugs are implementation errors, and the way we try to avoid them is by managing competence, workload and stress level, and by use of automated security testing such as static analysis and similar tools. Experience from software reliability engineering shows that about 50% of software flaws are implementation erorrs – the rest would then be design flaws. These are designs and architectures that do not implement the intentions of the designer. Static analysis cannot help us here, because there may be no coding errors such as lack of exception handling or lack of input validation – it is just the concept that is wrong; for example giving a user role too many privileges, or allowing a component to talk to a component it shouldn’t have access to. A good tool for identificaiton of such design flaws is threat modeling based on a data flow diagram. Make a diagram of the software data flow, break it down into components on a reasonable level, and consider how an adversary could attack each component and what could be the impact of this. By going through an excercise like this, you will likely identify potential vulnerabilities and weaknesses that you need to handle. The mitigations you introduce may be various security controls – such as blocking internet access for a server that only needs to be available on the internal network. The next question then is – how do you validate that your controls work? Do you order a penetration test form a consulting company? That could work, but it doesn’t scale very well, you want this to work in your pipeline. The primary tools to turn to is unit and integration testing.
We will not discuss the techniques for threat modeling in this post, but there are different techniques that can be applied. Keep it practical, don’t dive too deep into the details – it is better to start with a higher level view on things, and rather refine it as the design is matured. Here are some methods that can be applied in software threat modeling:
- STRIDE: https://docs.microsoft.com/en-us/azure/security/develop/threat-modeling-tool-threats
- Protection poker: https://collaboration.csc.ncsu.edu/laurie/Security/ProtectionPoker/
- Attack trees: https://www.schneier.com/academic/archives/1999/12/attack_trees.html
Often a STRIDE-like approach is a good start, and for the worst case scenarios it can be worthwhile diving into more detail with attack trees. An attack tree is a fault tree applied to adversarial modeling.
After the key threats have been identified, it is time to plan how to deal with that risk. We should apply the defense-in-depth principle, and remeber that a single security control is usually not enough to stop all attacks – because we do not know what all possible attack patterns are. When we have come up with mitigations for the threats we worry about, we need to validate that they actually work. This validation should happen at the lowest possible level – unit tests, integration tests. It is a good idea for the developer to run his or her own tests, but these validations definitely must live in the build pipeline.
Let’s consider a two-factor authentication flow using SMS-based two-factor authentication. This is the authentication for an application used by politicians, and there are skilled threat actors who would like to gain access to individual accounts.
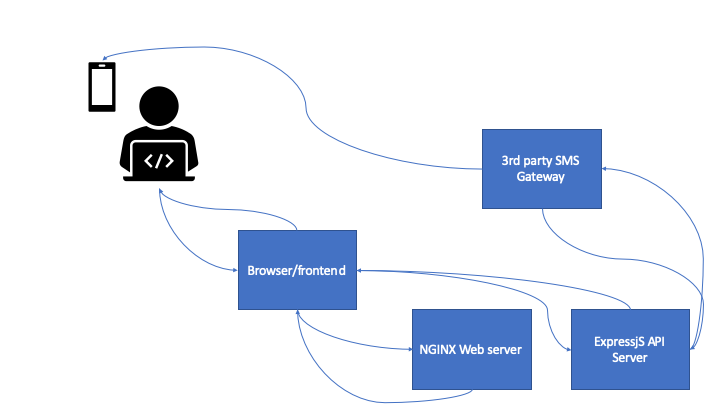
Here’s how the authentication process work:
- User connects to the domain and gets an single-page application loaded in the browser with a login form with username and password
- The user enters credentials, that are sent as a post request to the API server, which validates it with stored credentials (hashed in a safe way) in a database. The API server only accepts requests from the right domain, and the DB server is not internet accessible.
- When the correct credentials have been added, the SPA updates with a 2fa challenge, and the API server sends a post request to a third-party SMS gateway, which sends the token to the user’s cell phone.
- The user enters the code, and if valid, is authenticated. A JWT is returned to the browser and stored in localstorage.
Let’s put on the dark hat and consider how we can take over this process.
- SIM card swapping combined wiht a phishing email to capture the credentials
- SIM card swapping combined with keylogger malware for password capture
- Phishing capturing both password and the second factor from a spoofed login page, and reusing credentials immediately
- Create an evil browser extension and trick the user to install it using social engineering. Use the browser extension to steal the token.
- Compromise a dependency used by the application’s frontend, to allow man-in-the-browser attacks that can steal the JWT after login.
- Compromise a dependency used in the API to give direct access to the API server and the database
- Compromise the 3rd party SMS gateway to capture credentials, use password captured with phishing or some other technique
- Exploit a vulnerability in the API to bypass authentication, either in a dependency or in the code itself.
As we see, the threat is the adversary getting access to a user account. There are many attack patterns that could be used, and only one of them involves only the code written in the application. If we are going to start planning mitigations here, we could first get rid of the two first problems by not using SMS for two-factor authenticaiton but rather relying on an authenticator app, like Google Authenticator. Test: no requests to the SMS gateway.
Phishing: avoid direct post requests from a phishing domain to the API server by only allowing CORS requests from our own domain. Send a verification email when a login is detected from an unknown machine. Tests: check that CORS from other domains fail, and check that an email is sent when a new login occurs.
Browser extensions: capture metadata/fingerprint data and detect token reuse across multiple machines. Test: same token in different browsers/machines should lead to detection and logout.
Compromised dependencies is a particularly difficult attack vector to deal with as the vulnerability is typically unknown. This is in practice a zero-day. For token theft, the mitigation of using meta-data is valid. In addition it is good practice to have a process for acceptance of third-party libraries beyond checking for “known vulnerabilities”. Compromise of the third-party SMS gateway is also difficult to deal with in the software project, but should be part of a supply chain risk management program – but this problem is solved by removing the third-party.
Exploit a vulnerability in the app’s API: perform static analysis and dependency analysis to minimize known vulnerabilities. Test: no high-risk vulnerabilities detected with static analysis or dependency checks.
We see that in spite of having many risk reduction controls in place, we do not cover everything that we know, and there are guaranteed to be attack vectors in use that we do not know about.
Sprint planning – keeping the threat model alive
Sometimes “secure development” methodologies receive criticims for “being slow”. Too much analysis, the sprint stops, productivity drops. This is obviously not good, so the question is rather “how can we make security a natural part of the sprint”? One answer to that, at least a partial one, is to have a threat model based on the overall architecture. When it is time for sprint planning, there are three essential pieces that should be revisited:
- The user stories or story points we are addressing; do they introduce threats or points of attack not already accounted for?
- Is the threat model we created still representative for what we are planning to implement? Take a look at the data flow diagram and see if anything has changed – if it has, evaluate if the threat model needs to be updated too.
- Finally: for the threats relevant to the issues in the sprint backlog, do we have validation for the planned security controls?
Simply discussing these three issues would often be enough to see if there are more “known uknowns” that we need to take care of, and will allow us to update the backlog and test plan with the appropriate annotations and issues.
Coding: the mother of bugs after the design flaws have been agreed upon
The threat modeling as discussed above has as its main purpose to uncover “design flaws”. While writing code, it is perfectly possible to implement a flawed plan in a flawless manner. That is why we should really invest a lot of effort in creating a plan that makes sense. The other half of vulnerabilities are bugs – coding errors. As long as people are still writing code, and not some very smart AI, errors in code will be related to human factors – or human error, as it is popularly called. This often points the finger of blame at a single individual (the developer), but since none of us are working in vacuum, there are many factors that influence these bugs. Let us try to classify these errors (leaning heavily on human factors research) – broadly there are 3 classes of human error:
- Slips: errors made due to lack of attention, a mishap. Think of this like a typo; you know how to spell a word but you make a small mistake, perhaps because your mind is elsewhere or because the keyboard you are typing on is unfamiliar.
- Competence gaps: you don’t really know how to do the thing you are trying to do, and this lack of knowledge and practice leads you to make the wrong choice. Think of an inexperienced vehicle driver on a slippery road in the dark of the night.
- Malicious error injection: an insider writes bad code on purpose to hurt the company – for example because he or she is being blackmailed.
Let’s leave the evil programmer aside and focus on how to minimize bugs that are created due to other factors. Starting with “slips” – which factors would influence us to make such errors? Here are some:
- Not enough practice to make the action to take “natural”
- High levels of stress
- Lack of sleep
- Task overload: too many things going on at once
- Outside disturbances (noise, people talking to you about other things)
It is not obvious that the typical open office plan favored by IT firms is the optimal layout for programmers. Workload management, work-life balance and physical working environment are important factors for avoiding such “random bugs” – and therefore also important for the security of your software.
These are mostly “trying to do the right thing but doing it wrong” type of errors. Let’s now turn to the lack of competence side of the equation. Developers have often been trained in complex problem solving – but not necessarily in protecting software from abuse. Secure coding practices, such as how to avoid SQL injection, why you need output escaping and similar types of practical application secuity knowledge, is often not gained by studying computer science. It is also likely that a more self-taught individual would have skipped over such challenges, as the natural focus is on “solving the problem at hand”. This is why a secure coding practice must deliberately be created within an organization, and training and resources provided to teams to make it work. A good baseline should include:
- How to protect aginst OWASP Top 10 type vulnerabilities
- Secrets management: how to protect secrets in development and production
- Detectability of cyber threats: application logging practices
An organization with a plan for this and appropriate training to make sure everyone’s on the same page, will stand a much better chance of avoiding the “competence gap” type errors.
Security testing in the build pipeline
OK, so you have planned your software, created a threat model, commited code. The CI/CD build pipeline triggers. What’s there to stop bad code from reaching your production environment? Let’s consider the potential locations of exploitable bugs in our product:
- My code
- The libraries used in that code
- The environment where my software runs (typically a container in today’s world)
Obviously, if we are trying to push something with known critical errors in either of those locations to production, our pipeline should not accept that. Starting with our own code, a standard test that can uncover many bugs is “static analysis”. Depending on the rules you use, this can be a very good security control but it has limitations. Typically it will find a hardcoded password written as
var password = 'very_secret_password";but it may not find this password if it isn’t a little bit smart:
var tempstring = 'something_that_may_be_just_a_string";and yet it may throw an alert on
var password = getsecret();just because the word “password” is in there. So using the right rules, and tuning them, is important to make this work. Static analysis should be a minimum test to always include.
The next part is our dependencies. Using libraries with known vulnerabilities is a common problem that makes life easy for the adversary. This is why you should always scan the code for external libraries and check if there are known vulnerabilitie sin them. Commercial vendors of such tools often refer to it as “software component analysis”. The primary function is to list all dependencies, check them against databases of known vulnerabilities, and create alerts accordingly. And break the build process based on threshold limits.
Also the enviornment we run on should be secure. When building a container image, make sure it does not contain known vulnerabilities. Using a scanner tool for this is also a good idea.
While static analysis is primarily a build step, testing for known vulnerabilities whether in code libraries or in the environment, should be done regulary to avoid vulnerabilities discovered after the code is deployed from remaining in production over time. Testing the inventory of dependencies against a database of known vulnerabiltiies regulary would be an effective control for this type of risk.
If a library or a dependency in the environment has been injected with malicious code in the supply chain, a simple scan will not identify it. Supply chain risk management is required to keep this type of threat under control, and there are no known trustworthy methods of automatically identifying maliciously injected code in third-party dependencies in the pipeline. One principle that should be followed with respect to this type of threat, however, is minimization of the attack surface. Avoid very deep dependency trees – like an NPM project 25000 dependencies made by 21000 different contributors. Trusting 21000 strangers in your project can be a hard sell.
Another test that should preferably be part of the pipeline, is dynamic testing where actual payloads are tested against injection points. This will typically uncover other vulnerabilities than static analysis will and is thus a good addition. Note that active scanning can take down infrastructure or cause unforeseen errors, so it is a good idea to test against a staging/test environment, and not against production infrastructure.
Finally – we have the tests that will validate the mitigations identified during threat modeling. Unit tests and integration tests for securtiy controls should be added to the pipeline.
Modern environments are usually defined in YAML files (or other types of config files), not by technicians drawing cables. The benefit of this, is that the configuration can be easily tested. It is therefore a good idea to create acceptance tests for your Dockerfiles, Helm charts and other configuration files, to avoid an insider from altering it, or by mistake setting things up to be vulnerable.
Security debt has a high interest rate
Technical debt is a curious beast: if you fail to address it it will compound and likely ruin your project. The worst kind is security debt: whereas not fixing performance issues, removing dead code and so on compunds like a credit card from your bank, leaving vulnerabilities in the code compunds like interest on money you lent from Raymond Reddington. Manage your debt, or you will go out of business based on a ransomware compaign followed by a GDPR fine and some interesting media coverage…
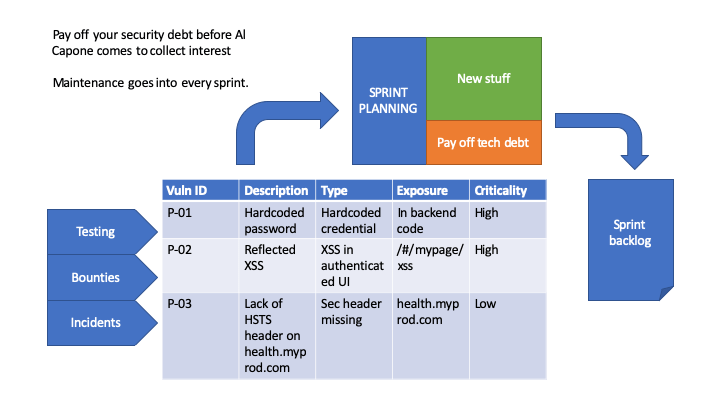
Say you want to plan using a certain percentage of your time in a sprint on fixing technical debt, how do you choose which issues to take? I suggest you create a simple prioritization system:
- Exposed before internal
- Easy to exploit before hard
- High impact before low impact
But no matter what method you use to prioritize, the most important thing is that you work on getting rid of known vulnerbilities as part of “business-as-usual”. To avoid going bankrupt due to overwhelming technical debt. Or being hacked.
Sometimes the action you need to take to get rid of a security hole can create other problems. Like installing an update that is not compatible with your code. When this is the case, you may need to spend more resources on it than a “normal” vulnerability because you need to do code rewrites – and that refactoring may also need you to update your threat model and risk mitigations.
Operations: your code on the battle field
In production your code is exposed to its users, and in part it may also be exposed to the internet as a whole. Dealing with feedback from this jungle should be seen as a key part of your vulnerability management program.
First of all, you will get access to logs and feedback from operations, whether it is performance related, bug detections or security incidents. It is important that you feed this into your issue management system and deal with it throughout sprints. Sometimes you may even have a critical situation requiring you to push a “hotfix” – a change to the code as fast as possible. The good thing about a good pipeline is that your hotfix will still go through basic security testing. Hopefully, your agile security process and your CI/CD pipeline is now working so well in symbiosis that it doesn’t slow your hotfix down. In other words: the “hotfix” you are pushing is just a code commit like all others – you are pushing to production several times a day, so how would this be any different?
Another aspect is feedback from incident response. There are two levels of incident response feedback that we should consider:
- Incident containment/eradication leading to hotfixes.
- Security improvements from the lessons learned stage of incident response
The first part we have already considered. The second part could be improvements to detections, better logging, etc. These should go into the product backlog and be handled during the normal sprints. Don’t let lessons learned end up as a PowerPoint given to a manager – a real lesson learned ends up as a change in your code, your environment, your documentation, or in the incident response procedures themselves.
Key takeaways
This was a long post, here are the key practices to take away from it!
- Remember that vulnerabilities come from poor operational practices, flaws in design/architecture, and from bugs (implementation errors). Linting only helps with bugs.
- Use threat modeling to identity operational and design weaknesses
- All errors are human errors. A good working environment helps reduce vulnerabilities (see performance shaping factors).
- Validate mitigations using unit tests and integration tests.
- Test your code in your pipeline.
- Pay off technical debt religiously.