P
Procurement is easy – getting exactly what you need is not. I have previously discussed the challenges related to follow-up of suppliers of SIL rated equipment on this blog, but that was from the perspective of an organization. This time, let’s look at what this means for you, if you are either the purchaser or the package engineer responsible for the deliverable. Basically there are three challenges related to communication in procurement of SIL rated equipment – or procurement of anything for that matter;
- The purchaser does not understand what the project needs
- The customer does not understand what the purchaser needs
- The package engineer does not know that the purchaser does not know what the project needs, and therefore he or she does also not know that the supplier does not know what the project actually needs
This, of course, is recipe for a lot of quarreling and time wasted on finger pointing and the blame game. All of this is expensive, frustrating and useless. What can we do to avoid this problem in the first place? First, everybody needs to know a few basic things about SIL. The standards used in industry are quite heavy reading, and when guidelines for your industry are available, it is a good idea to use them. For the oil and gas industry, the Norwegian Oil & Gas Association’s Guideline No. 070 is a very good starting point. To distill it down to a bare minimum, the following concepts should be known to all purchasers and package engineers:
- Why does a safety integrity level requirement exist for the function your equipment is a part of?
-
What is a safety integrity level (SIL) in terms of:
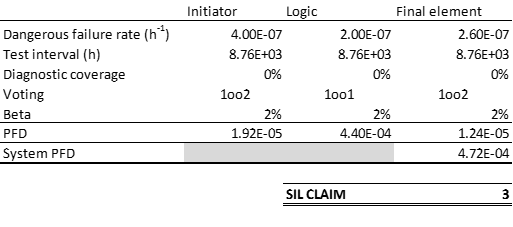
- Quantitative requirements (PFD quota for the equipment)
- Architectural requirements (hardware fault tolerance, safe failure fraction, etc.)
- Software requirements
- Qualitative requirements
- What are the basic documentation requirements?
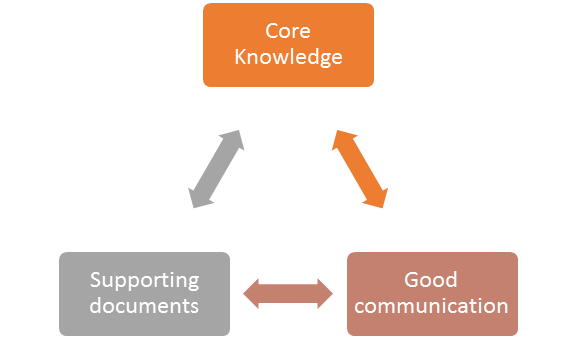
When this is known, communication between purchaser and supplier becomes much easier. It also becomes easier for the package engineer and the purchaser to discuss follow-up of the vendors and what requirements should be put in the purchase order, as well as in the request for proposal. Most projects will develop a lot of functional safety documents. Two of the most important ones in the purchasing process are:
- Safety Requirement Specification (SRS): In this document you find a description of the function your component is a part of, and the SIL requirements to the function. You will also find allocated PFD quotas to each component in the function – this is an important number to use in the purchasing process.
- A “Vendor guideline for Safety Analysis Reports” or a “Safety Manual Guideline” describing the project’s documentation requirements for SIL rated equipment
So, what can you do to bring things into this nice and orderly state? If you are a purchaser, take a brief SIL primer, or preferably, ask your company’s functional safety person to give you a quick introduction. Then talk to your package engineer about this things when setting out the ITT. If you are a package engineer, invite your purchaser for a coffee, to discuss the needs of the project in terms of these things. If the purchaser does not understand the terminology, be patient and explain. And remember that not everybody has the right background; the engineer may fail to understand some technical details of the purchasing function, and the purchaser may not understand the inner workings of your compressor – but aiming for a common platform to discuss requirements and follow-up of vendors will make life easier for both of you.