You have probably (hopefully) been told that open wifi is insecure, and that you should use a virtual private network to encrypt and protect your traffic. Most people don’t do this, perhaps because it seems hard to do?
Opera software now offers free VPN. It is built into the browser on the desktop, and a standalone app on smartphones. It also comes with the ability to block tracking cookies! Those are cookies that track the pages you look at on the web – for commercial purposes (or so they claim). An old but nice nontechnical write-up on tracking cookies is found at geek.com. The difference from back then is that big data and AI have amplified trackers abilities to spy on you and analyze your online life.
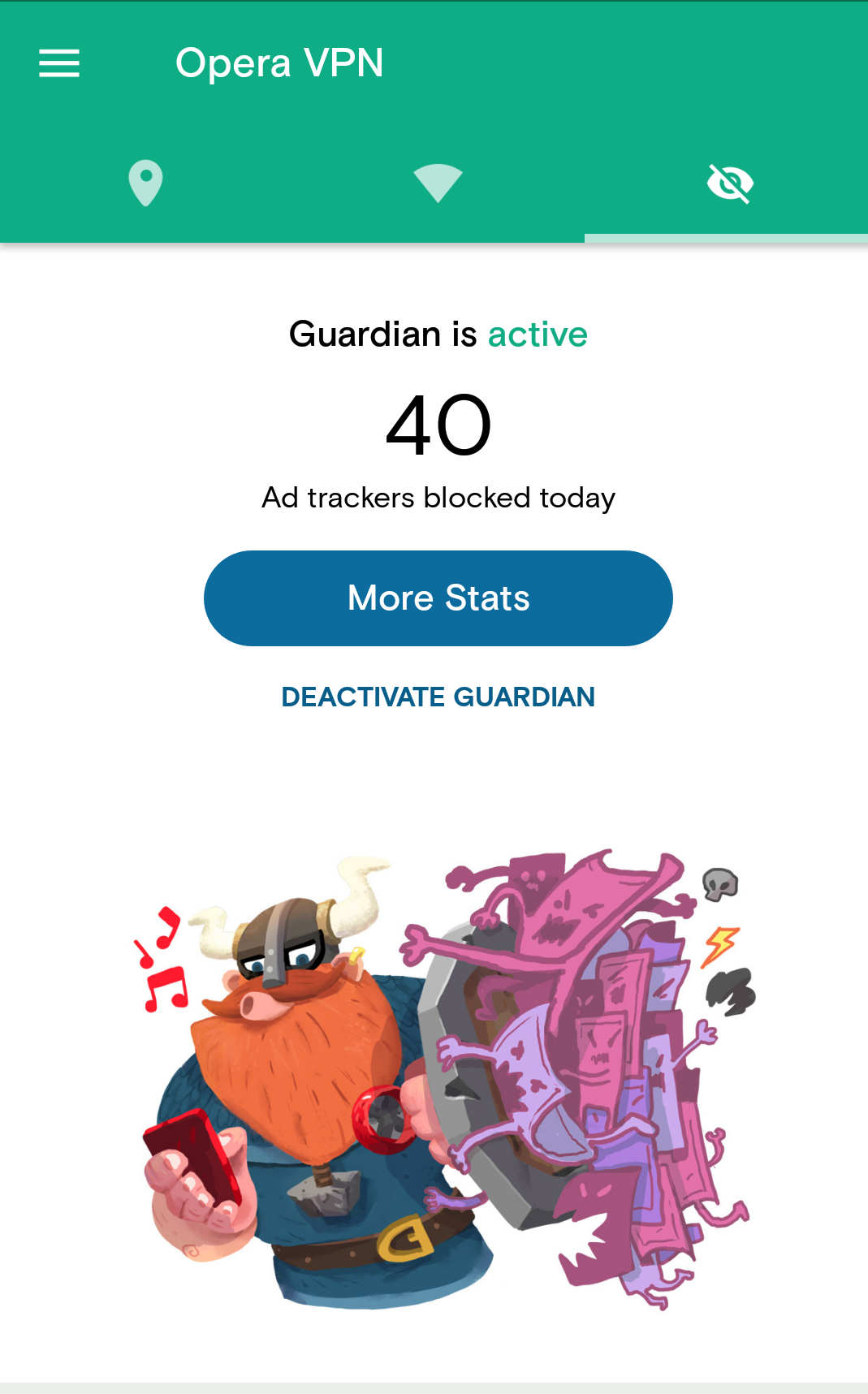
How many trackers are you exposed to by visiting high traffic news sites? Here’s what Opera VPN reported after visiting CNN.com and Bloomberg.com without clicking a single link on those pages.
40 trackers? I have no interest in feeding ad networks with my online habits. I suggest you go ahead and activate VPN and cookie filters on you mobile in addition to your desktop, also when browsing on secure networks!
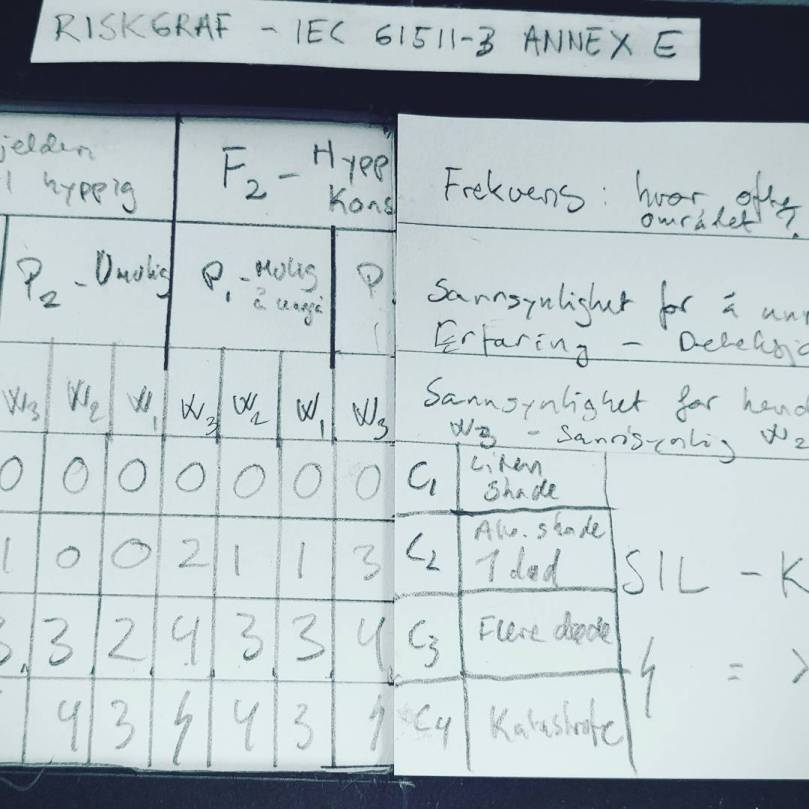
Risk management is a topic with a large number of methods. Within the process industries, semi-quantitative methods are popular, in particular for determining required SIL for safety instrumented functions (automatic shutdowns, etc.). Two common approaches are known as LOPA, which is short for “layers of protection analysis” and Riskgraph. These methods are sometimes treated as “holy” by practicioners, but truth is that they are merely coginitive aids in sorting through our thinking about risks.
In short, our risk assessment process consists of a series of steps here:
Identify risk scenarios
Find out what can reduce the risk that you have in place, like design features and procedures
Determine what the potential consequences of the scenario at hand is, e.g. worker fatalities or a major environmental disaster
Make an estimate of how likely or credible you think it is that the risk scenario should occur
Consider how much you trust the existing barriers to do the job
Determine how trustworthy your new barrier must be for the situation to be acceptable
Several of these bullet points can be very difficult tasks alone, and putting together a risk picture that allows you to make sane decisions is hard work. That’s why we lean on methods, to help us make sense of the mess that discussions about risk typically lead to.
Consequences can be hard to gauge, and one bad situation may lead to a set of different outcomes. Think about the risk of “falling asleep while driving a car”. Both of these are valid consequences that may occur:
You drive off the road and crash in the ditch – moderate to serious injuries
You steer the car into the wrong lane and crash head-on with a truck – instant death
Should you think about both, or pick one of them, or another consequence not on this list? In many “barrier design” cases the designer chooses to design for the worst-case credible consequence. It may be difficult to judge what is really credible, and what is truly the worst-case. And is this approach sound if the worst-case is credible but still quite unlikeley, while at the same time you have relatively likely scenarios with less serious outcomes? If you use a method like LOPA or RiskGraph, you may very well have a statement in your method description to always use the worst-case consequence. A bit of judgment and common sense is still a good idea.
Another difficult topic is probability, or credibility. How likely is it that an initiating event should occur, and what is the initating event in the first place? If you are the driver of the car, is “falling asleep behind the wheel” the initating event? Let’s say it is. You can definitely find statistics on how often people fall asleep behind the wheel. The key question is, is this applicable to the situation at hand? Are data from other countries applicable? Maybe not, if they have different road standards, different requirements for getting a driver’s license, etc. Personal or local factors can also influence the probability. In the case of the driver falling asleep, the probabilities would be influenced by his or her health, stress levels, maintenance of the car, etc. Bottom line is, also the estimate of probability will be a judgment call in most cases. If you are lucky enough to have statistical data to lean on, make sure you validate that the data are representative for your situation.Good method descriptions should also give guidance on how to do these judgment calls.
Most risks you identify already have some risk reducing barrier elements. These can be things like alarms and operating procedures, and other means to reduce the likelihood or consequence of escalation of the scenario. Determining how much you are willing to rely on these other barriers is key to setting a requirement on your safety function of interest – typically a SIL rating. Standards limit how much you can trust certain types of safeguards, but also here there will be some judgment involved. Key questions are:
Are multiple safeguards really independent, such that the same type of failure cannot know out multiple defenses at once?
How much trust can you put in each safeguard?
Are there situations where the safeguards are less trustworthy, e.g. if there are only summer interns available to handle a serious situation that requires experience and leadership?
Risk assessmen methods are helpful but don’t forget that you make a lot of assumptions when you use them. Don’t forget to question your assumptions even if you use a recognized method, especially not if somebody’s life will depend on your decision.
The last 4 years I’ve given guest lectures in process safety at the Norwegian University of Science and Technology for undergrad chemical engineering students – and I’ve promised to do this also this year – this is my annual pro bono event :).
I used to work as a consultant with Lloyd’s Register, and previously I’ve used slides based on their internal course in process safety, that I also used to teach. Now I have a new job at a different firm in a different sector (information security in a devops environment – in otherwords something completely different and not related to process safety or chemical engineering).
Obviously, I need to create some new content for this year’s lectures. I’m looking forward to it, as this is a great opportunity to brush up also on the form of delivery. So, the plan so far is:
Basic principles (no single point of failure, risk-based design thinking, observable risks, usability)
Process accident examples (the fire from ice example from CSB is still great, but perhaps I can find something new to add)
Key safety standards, and some examples on how to use them
ISO 10418 / API RP 14C / NORSOK P-002 (process design and safety)
IEC 61511 (safety instrumented systems and safety integrity levels)
IEC 62443-3-3 (New! Cybersec in process systems, I think this one’s going to be increasingly relevant)
The mother of all accidents: overpressure
Blowdown systems
How to simulate blowdown in a simple process segment
Pressure equalization in compressor trains
New threats to process plants
Cyber attacks
Practices to make your plant less vulnerable
What more do you think undergrad chemical engineering students need to learn about safety in design?
Digital control systems control almost every piece of technology we use, from the thermostat in your fridge to oil refineries and self-driving cars. My answer to this Quora user’s question suggests an iterative process involving:
setting objectives and goals
modeling the plant
designing the control structure
testing and simulation studies
testing on the real plant
maintenance during operations
The important thing here is not to think of it as a linear workflow; you will jump back in the process and redo stuff several times. For some unknown reason, universities tend to focus only on the modeling and simulation study part. The world would be a more reliable place if designers were taught to think about the whole process and the whole lifecycle from the start instead of waiting for experience to sink in.
IEC 61511-1 Ed. 2 is now out, and as I’ve mentioned previously on this blog, with new requirements for cybersecurity analysis for your safety instrumented systems. The new requirement makes it mandatory to perform a security risk and vulnerability assessment for your safety instrumented systems. It specifically requires you to identify threats, to assess impact and likelihood (or credibility), and to plan your mitigation strategy and response to identified threats. The standard allows you to use an overall cybersecurity assessment for your entire control system, provided you cover all relevant threats for the SIS.
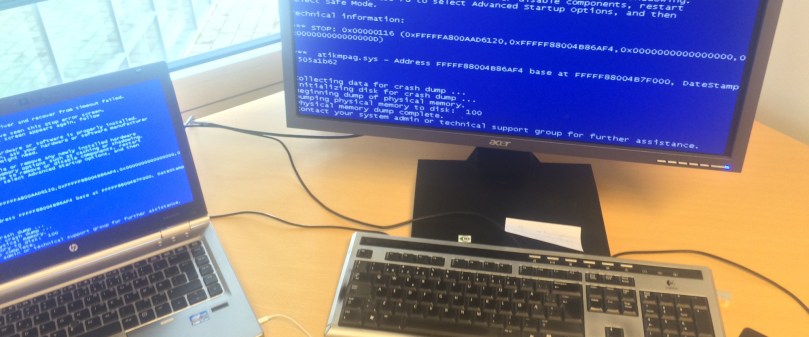
You do not want your SIS to show you the blue screen of death – have you looked into the security integrity of your system?
It is important to tailor the approach to the setting and the need in the network environment where the SIS is operated. It is possible to go into a vulnerability study at great detail, developing attack trees for low-level attack scenarios. From a SIS design point of view this is not very useful – and a more conceptual level assessment based on network topologies, security policies and the risk context of the plant is more appropriate.
At LR I’ve had the pleasure of adapting a more in-depth cybersecurity assessment method to the SIS environment together with some of my great colleagues, and we are looking forward to serving our customers with this as a part of functional safety management.
If you want to be contacted about IEC 61511 security requirements and how to integrate security into your functional safety mangement, please fill out the contact form below.
Modern cities are trying to become greener. One of the major contributors to pollution from cities is transport.
Toll roads – the only way to reduced congestion in cities?
In Norway, there are three main strategies to change people’s behaviors in this respect:
Toll roads into and out of all cities to make it more expensive to drive your own car, in addition to high environmental taxes on buying new cars and on fossil fuel (gasoline costs about NOK 15 per liter, which is equivalent to about US $7/gal.
Subsidized public transport (buses, trains, etc.). Buses in urban areas are modern, run on biofuels, run about every 10 minutes in dense areas, and a bus card valid for one month costs about NOK 700.
Electric cars are not subject to heavy taxation, and they get a free pass on the toll roads. A Model S from Tesla thus costs about the same as a much smaller fossil fuel car from non-premium brands.
In spite of these efforts, traffic is increasing. Primarily, due to a lot of people buying electric cars. The problem is, it still creates congestion. And parking is hard to find. So what do politicians suggest to fix the problem? Primarily two things in Trondheim where I live: make parking even more scarce, and increase toll road prices by at least 50%. I suppose that may work, but is it the only option?
Norway has a skilled workforce. A lot of people work in offices with computers, and there is really limited need to actually be in that office to get your stuff done. I think telecommuting could help reduce congestion, and help the environment in one easy whiff. This, however, requires a lot of companies to change the way they approach collaboration, mangement, and use of technology. A social network can not fully replace coffe machine chit-chat, but it helps (use Yammer, closed Facebook groups, etc.). Use productivity software that allows online collaboration – most office programs allow this today (Microsoft Office and Google Apps perhaps being the biggest players). Managers should also empower their employees to take more decisions than they do in practice today – in many companies the hierarchy is still king – and that does not play well with a semi-virtual workforce. So – what would happen if 50% of commuters would work from home 2 days per week? If we take 1000 commuters as basis for our argument, we know that about 50% drive a car, the rest will use a bicycle, walk or use public transport. Further, we can assume that people will chose random days to work from home, so about the same number of people will work from home every day. Then we are down to about 250 cars per day (on average). This may of course be a bit optimistic, but making people telecommute part of their work weeks can have huge impact on pollution and congestion. Therefore politicians should try to give incentives to both companies and indivduals if they actually choose to implement such a policy:
Reduce tax burdon on employer (e.g. by introducing a pro forma deductible per telecommuter)
Make broadband connections tax deductible for people who choose to telecommute
Cybersecurity is on the list of many organizations’ top priorities nowadays. Obviously, protecting the confidentiality, integrity and availability of business data is a crucial part of any modern enterprise’s risk management activities. However, in many cases, security measures are making simple things difficult, and hard things even harder. When this happens, users tend to find workarounds, often involving using private cloud services, private devices, or connecting via sneakernets to do their business. If this is the case at your company – you should rethink your approach to security.
Feel locked out by your security policy? Are you prevented from doing your job by the IT department?
What can organizations do to maintain security and allowing people to get their work done?
Security measures need to have a sound basis in the threats you are trying to avoid. This means, you should have at least a basic grasp on what kind of threats you are dealing with, and which measures will be effective in dealing with them. Here’s a 6-step list to how you can achieve that.
Perform a cyber security threat identification to list all threats and sort them as “unacceptable” and “acceptable” based on both impact and credibility
Deal with the threats by designing counter-measures; this can be technology, awareness training and response capabilities
Educate your users on the threats and why it is important to avoid letting adversaries in.
The principle of least privilege is sound – but it should not be interpreted as “no access given unless proven beyond doubt that access is needed”. It means – access shall only be given if it is meaningful for that user to have access, and in cases where this increases the attack surface, ensure the user is educated to understand what that means.
Do not overuse filtering techniques for content. That is the same as inviting sneaker nets where you have no control.
Never forget that technology is there to help people get stuff done, not in order to prevent them from doing anything. If a user needs to do something (e.g. to download and test software from the internet), work with the user to find safe ways to do this instead of being an obstacle.
Awareness is important when it comes to cyber security, and this awarenes is often lacking in the control system domain because we are so used to looking for all sorts of other causes of upsets in production or accidents for that matter. I’m going to give a talk on industrial cyber security at a workshop offered by my employer (LR) on Tuesday. I figured I wanted to tell a short story to set the mood – here’s the outline.
The reboot story
Aldo Tomation is responsible for the control systems at the specialist material manufacturing firm Composite Reinforcement Inc. Aldo is passionate about both the finances of the company as well as the health and safety of his coworkers. Because of this, Aldo has shown great focus on production regularity and that all requirements of the European Machinery Directive and the machinery safety standard ISO 13849-1 have been met. Lately he has noticed a certain reduction in the production regularity, and the downtime is always occuring at the same time of the day. Every day, just after 4pm CET, the plant goes down, and then comes back up again shortly after. Aldo thinks that this is very strange, so he studies the machine logs. There he can see that the control system is reobooted just after 4pm every day, and that there are no control system log entries or data entries in the historian before the night shift comes on at 10pm. During the night shift everything works as it should.
Curious about this strange behavior Mr. Tomation talks to the operators. They tell him that every day the HMI screens and controls are locked just after 4pm every day but that they have found a workaraound; they just reboot the system and unplug the network cable just after the reboot – then everything works flawlessly! Aldo is impressed with the creativity shown by the operators to regain control but still puzzled by this strange behavior. He considers calling customer support to complain about the quality of the control system.
Question: If you had been Mr. A. Tomation – would you have considered the possibility of a cyber attack as the reason behind this strange need fo rebooting the control system?
3 Weeks before this strange behavior appeared, the firm had signed an agreement with the Japanese navy to deliver reinforcement fibers for a modernization project they were running on their submarine fleet. This deal had been kept a secret from both parties. Could it still have something to do with the attacks?
What kind of awareness do I hope to give birth to with this story?
If your system is behaving in a strange way – it is worth checking out
Businesses can be targets for attacks that are motivated by geo-politics
Running a whole shift without logs shouldn’t be considered normal – why did the operators not report this as a possible security incident?
I’d love to hear your comments on whether you think this sort of story can be effective in awareness work. I’m going to test it with some clients, and then decide if I think it works.
Sometimes we talk to people who are responsible for operating distributed control systems. These are sometimes linked up to remote access solutions for a variety of reasons. Still, the same people do often not understand that vulnerabilities are still found for mature systems, and they often fail to take the typically simple actions needed to safeguard their systems.
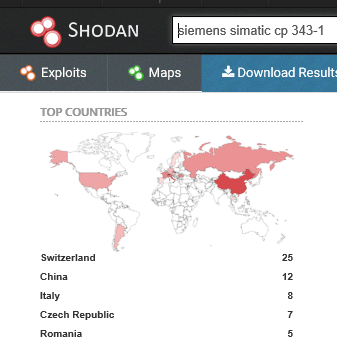
For example, a new vulnerability was recently discovered for the Siemens Simatic CP 343-1 family. Siemens has published a description of the vulnerability, together with a firmware update to fix the problem: see Siemens.com for details.
So, are there any CP 343’s facing the internet? A quick trip to Shodan shows that, yes, indeed, there are lots of them. Everywhere, more or less.
Now, if you did have a look at the Siemens site, you see that the patch was available from release date of the vulnerability, 27 November 2015. What then, is the average update time for patches in a control system environment? There are no patch Tuesdays. In practice, such systems are patched somewhere from monthly to never, with a bias towards never. That means that the bad guys have lots of opportunities for exploiting your systems before a patch is deployed.
This simple example reinforces that we should stick to the basics:
Know the threat landscape and your barriers
Use architectures that protect your vulnerable systems
Do not use remote access where is not needed
Reward good security behaviors and sanction bad attitudes with employees
Create a risk mitigation plan based on the threat landscape and stick to it practice too
Whenever something works beautifully together, like pieces in a complex piece of machinery, it creates satisfaction for everyone involved. When the system consists of people working together on a complex project, we experience this type of satisfaction when there is a situation of flow in the project. Information is treated when it is received and flows without barriers to the next person who needs to perform a task or make decision based on this information. Unfortunately, this is far from reality in most functional safety projects. These projects are typically complex, with a variety of stakeholders and various agendas and levels of competence.
Good project planning and execution across interfaces is necessary to achieve a lean functional safety organization throughout the lifecycle of a safety instrumented system. The opportunities for quality improvements and the banashing of waste are plentiful and many of these opportunities are low-hanging fruits.
This field could benefit greatly from lean thinking and a culture geared towards achieving flow. This, however, requires better functional safety planning, more openness between stakeholders, and a clear picture of how functional safety activities fit with the bigger picture. Lean is all about banishing waste, and there is a lot of waste in functional safety projects. Typical types of waste encountered on most projects include:
People waiting for input to perform the next activity. A lot of this waiting is unnecessary and due to bad planning, follow-up or lack of understanding of follow-on effects of missing deadlines
Unnecessary work performed – a lot of documentation is created and never used. This is related to competence levels with stakeholders and “wrong” or “ultraconservative” interpretations of standards and regulations.
Re-work: work done several times due to lack of information, wrong people involved, inefficient review processes, bad quality, etc.
Optimizing the whole work process requires the whole value chain to be involved, and that inefficiencies can be rooted out across organizational interfaces. By systematically removing “waste” in the functional safety value chain, I would expect that better quality and lower costs could be obtained at once. And better quality in this respect means fewer fatalities, less pollution and better uptime.