Excessive security controls when the organization isn’t ready causes friction and destroys value. Learn to identify your organization’s security sweet spot and avoid making the security team the most unpopular group in your company.
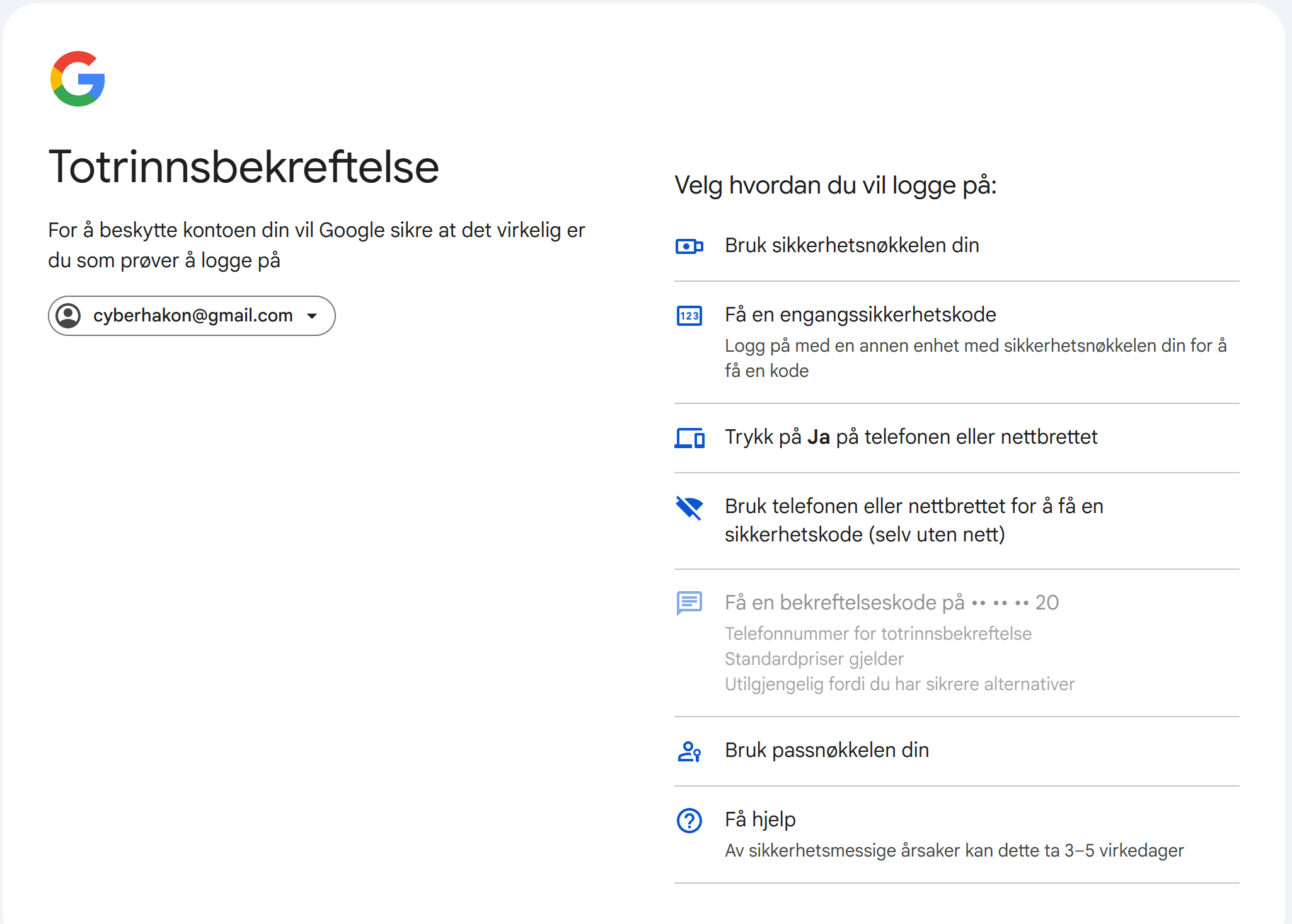
Many cybersecurity professionals are good at security but bad at supporting their organizations. When security takes priority over the mission of the organization, your security team may be just as bad for business as the adversary. Security paranoia will often lead to symptoms such as:
- Security controls introducing so much friction that people can’t get much done. The best employees give up and become disengaged or leave.
- Mentioning IT to people makes them angry. The IT department in general, and security team in particular, is hated by everyone.
- IT security policies are full of threats of disciplinary actions, including reporting employees to the police and firing them.
Security when done wrong, can be quite toxic. When security aligns with the culture and mission of the organization, it creates value. When it is abrasive and misaligned, it destroys value. Paranoia is destructive.

The minimum on the green line on the graph is perhaps the sweet spot for how much security to apply. The difficulty is in finding the sweet spot. It is also not a fixed point on the scale, it is a sliding scale. As the maturity of the organization develops, the sweet spot will move towards the right on the graph. Higher maturity in the organization will allow you to tighten security without destroying value through friction, inefficiencies and misalignment.

If you want to kick-start security improvements at work, consider e-mailing this article to your manager with your own take on what your organization’s security sweet spot is
Finding your sweet spot and translating it into security controls
Finding the sweet spot can be challenging. You want to challenge the organization, and help it grow its security maturity, without causing value destruction and disengagement. To achieve this, it is helpful to think about 3 dimensions in your security strategy:
- Business process risk
- Lean process flow with minimal waste
- Capacity for change
If you want to be profitable, keep an engaged workforce, and maintain a high level of security it requires good understanding of cyber risk, that you have established digital work processes that are not getting in the way of the organization’s goals, and a motivated workforce that welcomes change. If you are starting in a completely different place than that, tightening security can easily destory more value than it protects.
Understanding your business process cyber risk is necessary so that you can prioritize what needs to be protected. There are many methods available to asses risks or threats to a system. The result is a list of risks, with a description of possible causes and consequences, an evaluation of likelihood and severity, and suggested security controls or mitigations to reduce the risk. No matter what process you use to create the risk overview, you will need to
- Describe the system you are studying and what about it is important to protect.
- Identify events that can occur and disturb the system
- Evaluate the risk contribution from the elements
- Find risk treatments
If the risk to your business value from cyber attacks is very high, it would indicate a need for tighter security. If the risk is not too worrying, less security tightness may be appropriate.
The next step is about your workflows. Do you have work processes with low friction? Securing a cumbersome process is really difficult. Before you apply more security controls, focus on simplifying and optimizing the processes such that they become lean, reliable and joyful to work with. Get rid of the waste! If you are far from being lean and streamlined, be careful about how much security you apply.
The final point is the capacity for change. If the workforce is not too strained, has a clear understanding of the strategic goals, and feel they get rewarded for contributing to the organization’s mission, the capacity for change will typically be high. You can introduce more security measures without destroying value or causing a lot of frustration. If this is not in place, it will be a precursor for going deep on security measures.
To summarize – make sure you have efficient value creation processes and enough capacity for change before you apply a lot of security improvements. If your organization sees a high risk from cyber attacks, but has low process efficiency and limited capacity for change, it would be a good approach to apply basic security controls, and focus on improving the efficiency and capacity for change before doing further tightening. That does mean operating with higher risk than desired for some time, but there is no way to rush change in an organization that is not ready for it.

Security growth through continuous improvement is the way.
Like what you read? Remember to subscribe – and share the article with colleagues and friends!
The balancing act
Consider an engineering company that provides engineering services for the energy sector. They are worried about cyber attacks delaying their projects, which could cause big financial problems. The company is stretched, with most engineers routinely working 60-hour weeks. The workflows are highly dependent on the knowledge of individuals, and not much is documented or standardized. The key IT systems they have are Windows PC’s and Office 365, as well as CAD software.
The CEO has engaged a security consulting company to review the cybersecurity posture of the firm. The consulting report shows that the company is not very robust to cyber attacks, that security awareness is low. The cyber risk level is high.
The CEO, herself an experienced mechanical engineer, introduces a security improvement program that will require heavy standardization, introduction of new administrative software and processes, and will limit the personal freedom in choice of working methods for the engineers. He meets massive opposition, and one of the most senior and well-respected engineering managers says “this is a distraction, we have never seen a cyber attack before. We already work a lot of overtime, and cannot afford to spend time on other things than our core business – which is engineering.”. The other lead engineers support this view.
The CEO calls the consultants up again, and explains that she will have difficulties with introducing a lot of changes, especially in the middle of a big project for one of the key customers. She asks what the most important security measures would be. She gets a list of some key measures that should be implemented, such as least privilege access, multifactor authentication and patching. The CEO then makes a plan to roll out MFA first, and then to focus on working with the engineers to improve the work flows to reduce “waste”. With a step-by-step approach, they have seen some security wins, and after 12 months, the organization is at a much healthier state.
- Engineers no longer log on to their PC’s as administrators for daily work
- MFA is used everywhere, and 90% of logons are now SSO thorugh Entra ID
- They have documented, standardized and optimized some of the work processes that they do often. This has freed up a lot of time, 60-hour weeks are no longer the norm.
- The CEO has renewed focus on strategic growth for the company, and everyone knows what the mission is, and what they are trying to achieve. Staff motivation is much higher than before.
Thanks to good organizational understanding of the CEO, and helpful input from the security consultants, the actual security posture is vastly improved, even with few actual security controls implemented. The sweet spot has taken a giant leap to the right on the attacker-paranoia graph, and the firm is set to start its maturity growth journey for improved cybersecurity.
The key take-aways
- Don’t apply more security tightness than the organization can take. That will be destructive.
- Assess the security needs and capacity by evaluating risk, business process efficiency and capacity for change
- Prioritize based on risk and capacity, improve continuously instead of trying to take unsustainable leaps in security maturity