Most cybersecurity advisors will tell you that the most important of all security measures is to keep your software up to date by installing patches as soon as they are available. Most exploits that hackers use is old – they are not zero-day vulnerabilities being exploited. The reason this works is because people are so slow in updating their software; the average time from a patch is made available until it is installed in a corporate environment is 6 months – that is a big Window for wrongdoers to do their thing. This is cause for worry, especially when you also consider the fact that the time it takes from a vulnerability is made public until an exploit is available through frameworks such as Metasploit is only days. Days vs. months, in favor of the bad guys.
Keeping track of all the vulnerabilities that exist and the necessary patches or configuration changes that you need to apply to keep your organization safe is a daunting task. That is why you need automation, and you need open data. There are many open CVE (common vulnerabilities and exposures) databases available – and the typical go-to source is the one provided by NIST. This is a big database compiled for you, free to use. It has a web interface where you can search for software that you own – but of course this is tedious. Let us do it anyway, just to see what kind of information you can expect to get from this database. Searching for the word “outlook” gives 147 records. By random we select this result; CVE-2016-3278. We see that the vulnerability is described with a lot of information; it applies to Outlook in all versions since 2010, it has received a CVSS v2 base score of 9.3 (which means that this is essentially bad and you really want to protect yourself from it), and a link to the relevant Microsoft technical bulletin. OK, so the CVE database gives you a description of the vulnerability, and assessment of how bad it really is (the CVSS score) and a link to the vendor so you can find the relevant patches.
This is all good, but what if you have a system with thousands of assets you need to track? You need an asset database, and you need automation of the tracking of vulnerabilities. You can buy systems that do this for you from your favorite asset management vendors, or you can roll your own system based on open data. The latter is of course more interesting!
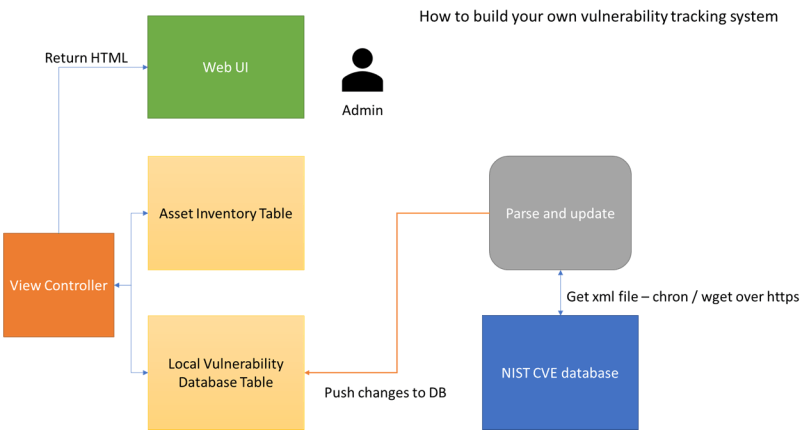
The NIST CVE database does not only come in the form of a search engine; it also has an API, or more correctly, it pushes its data in XML files kept up to date regularly. You get two files: one complete file with more than 82.000 vulnerabilities, and modification files that you can use to update your mirror of the database locally without downloading a humongous XML file again. You find the NIST data feeds here: https://nvd.nist.gov/download.cfm.
Of course, when you have the vulnerabilities, you need a foreign key relationship between your asset table and the vulnerability table. This is where another nice little trick comes into play: the CPE syntax (common platform enumeration). This is a standardized syntax for describing software assets that is used in the CVE database to indicate which software versions and configurations are threatened by a particular vulnerability.
It is relatively easy to write a web application to do this using your favorite backend – see the flow chart for one possible architecture you can use. Python is a good choice as backend because it is easy to render XML files using the fantastic module ElementTree, which makes parsing XML easy and quick (and the implementation is very fast as well).
This is the backend – what you put in the Web UI is up to you. You probably want some nice dashboards, alerts, and issue tracking. Now – go out and play!


