

We have connected everything to the Internet – from power plants to washing machines, from watches with fitness trackers to self-driving cars and even self-driving gigantic ships. At the same time, we struggle to defend our IT systems from criminals and spies. Every day we read about data breaches and cyber attacks. Why are we then not more afraid of cyber attacks on the physical things we have put into our networks?
- Autonomous cars getting hacked – what if they crash into someone?
- Autonomous ships getting hacked – what if they lose stability and sink due to a cyber attack or run over a small fishing boat?
- Autonomous light rail systems – what if they are derailed at high speed due to a cyber attack?
Luckily, we are not reading about things like this in the news, at least not very often. There have been some car hacking mentioned, usually demos of possibilities. But when we build more and more of these smart systems that can cause disasters of control is lost, shouldn’t we think more about security when we build and operate them? Perhaps you think that someone must surely be taking care of that. But fact is, in many cases, it isn’t really handled very well.

How can an autonomuos vessel defend against cyber attacks?
What is the attack surface of an autonomous system?
The attack surface of an autonomous system may of course vary, but they tend to have some things in common:
- They have sensors and actuators communicating with a “brain” to make decisions about the environment they operate in
- They have some form of remote access and support from a (mostly) human operated control center
- They require systems, software and parts from a high number of vendors with varying degree of security maturity
If we for the sake of the example consider an autonomous battery powered vessel at sea, such as ferry. Such a vessel will have multiple operating modes:
- Docking to the quay
- Undocking from the quay
- Loading and offloading at quay
- Journey at sea
- Autonomous safety maneuvers (collision avoidance)
- Autonomous support systems (bilge, ballast, etc)
In addition there will typically be a number of operations that are to some degree human led, such as search and rescue if there is a man over board situation, firefighting, and other operations, depending on the operating concept.
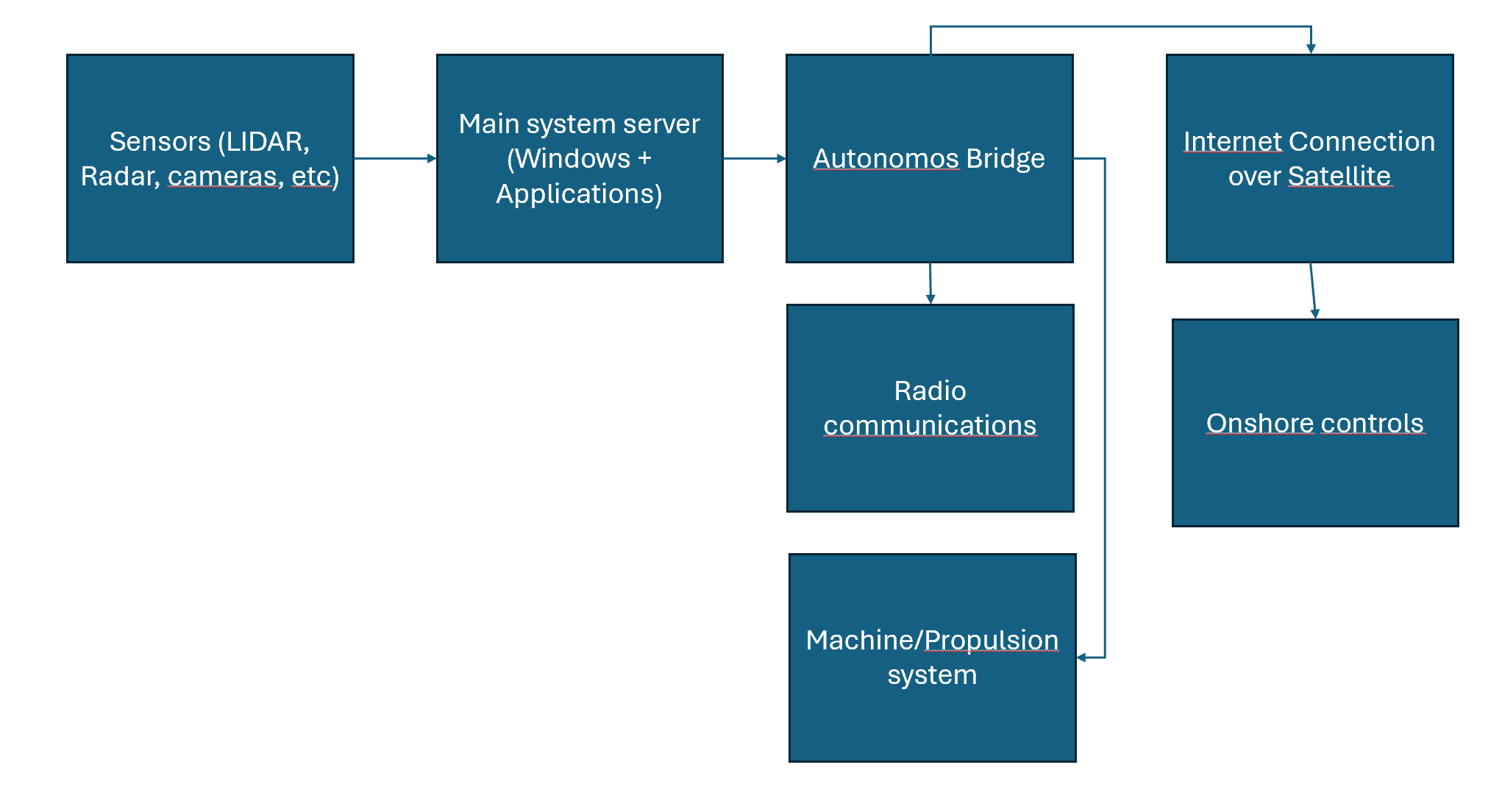
To support the operations required in the different modes, the vessel will need an autonomous bridge system, an engine room able to operate without a human engineer in place to maintain propulsion, and various support systems for charging, mooring, cargo handling, etc. This will require a number of IT components in place:
- Redundant connectivity with sufficient bandwidth (5G, satellite)
- Local networking
- Servers to run the required software for the ship to operate
- Sensors to ensure the ship’s autonomous system has good situational awareness (and the human onshore operators in the support center)
The attack surface is likely to be quite large, including a number of suppliers, remote access systems, people and systems in the remote control center, and remote software services that may run in private data centers, or in the cloud. The main keyword here is: complexity.
Defending against cyber piracy at high seas
With normal operation of the vessel, its propulsion and bridge systems would not depend on external connectivity. Although cyber attacks can also hit conventional vessels, much of the damage can be counteracted by seafarers onboard taking more manual control of the systems and turning off much of the “smartness”. With autonomous systems this is not always an option, although there are degrees of autonomy and it is possible to use similar mechanisms if the systems are semi-autonomous with people present to take over in case of unusual situations. Let’s assume the systems are fully autonomous and there is nobody onboard to take control of them.
Since there are no people to compensate for digital systems working against us, we need to teach the digital systems to defend themselves. We can apply the same structural approach to securing autonomous systems, as we do to other IT and OT systems; but we cannot rely on risk reduction from human local intervention. If we follow “NSM’s Grunnprinsipper for IKT-sikkerhet” (the Norwegian government’s recommendations for IT security, very similar to NIST’s cybersecurity framework), we have the following key phases:
- Identify: know what you have and the security posture of your system
- Protect: harden your systems and use security technologies to stop attackers
- Detect: set up systems so that cyber attacks can be detected
- Respond: respond to contain compromised systems, evict intruders, recover capabilities, improve hardening and return to normal operations
These systems are also operational technologies (OT). It may therefore be useful also to refer to IEC 62443 in the analysis of the systems, especially to assess the risk to the system, assign requires security levels and define requirements. Also the IEC 62443 reference architecture is useful.
It is not so that all security systems have to be working completely autonomously for an autonomous system, but it has to be more automated in a normal OT system, and also in most IT systems. Let’s consider what that could mean for a collision avoidance system on an autonomous vessel. The job of the collision avoidance system can be defined as follows:
- Detect other vessels and other objects that we are on collision course with
- Detect other objects close-by
- Choose action to take (turn, stop, reverse, alert on-shore control center, communicate to other vessels over radio, etc)
- Execute action
- Evaluate effect and make corrections if needed
In order to do this, the ship has a number of sensors to provide the necessary situational awareness. There has been a lot of research into such systems, especially collaborative systems with information exchange between vessels. There have also been pilot developments, such as this one https://www.maritimerobotics.com/news/seasight-situational-awareness-and-collision-avoidance by the Norwegian firm Maritime Robotics.
We consider a simplified view of how the collision avoidance system works. Sensors tell the anti collision system server about what it sees. The traffic is transmitted over proprietary protocols, some over tcp, some over udp (camera feeds). Some of the traffic is not encrypted, but all is transferred over the local network. The main system server is processing the data onboard the ship and making decisions. Those decisions go to functions in the autonomous bridge to take action, including sending radio messages to nearby ships or onshore. Data is also transmitted to onshore control via the bridge system. Onshore can use remote connection to connect to the collision avoidance server directly richer data, as well as overriding or configuring the system.
Identify
The system should automatically create a complete inventory of its hardware, software, networks, and users. This inventory must be available for automated decision making about security but also for human and AI agents working as security operators from onshore.
The system should also automatically keep track of all temporary exceptions and changes, as well as any known vulnerabilities in the system.
In other words: a real-time security posture management system must be put in place.
Protect
An attacker may wish to perform different types of actions on this vessel. Since we are only looking at the collision avoidance system here we only consider an adversary that wants to cause an accident. Using a kill-chain approach to our analysis, the threat actor thus has the following tasks to complete:
- Recon: get an overview of the attack surface
- Weaponization: create or obtain payloads suiteable for the target system
- Delivery: deliver the payloads to the systems. Here the adversary may find weaknesses in remote access, perform a supply-chain attack to deliver a flawed update, use an insider to gain access, or compromise an on-shore operator with remote access privileges.
- Execution: if a technical attack, automated execution will be necessary. For human based attacks, operator executed commands will likely be the way to perform malware execution.
- Installation: valid accounts on systems, malware running on Windows server
- Command and control: use internet connection to remotely control the system using installed malware
- Actions on objectives: reconfigure sensors or collision avoidance system by changing parameters, uploading changed software versions, or turning the system off
If we want to protect against this, we should harden our systems as much as possible.
- All access should require MFA
- Segregate networks as much as possible
- Use least privilege as far as possible (run software as non-privileged users)
- Write-protect all sensors
- Run up-to-date security technologies that block known malware (firewalls, antivirus, etc)
- Run only pre-approved and signed code, block everything else
- Remote all unused software from all systems, and disable built-in functionality that is not needed
- Block all non-approved protocols and links on the firewall
- Block internet egress from endpoints, and only make exceptions for what is needed
Doing this will make it very hard to compromise the system using regular malware, unless operations are run as an administrator that can change the hardening rules. It will most likely protect against most malware being run as an administrator too, if the threat actor is not anticipating the hardening steps. Blocking traffic both on the main firewall and on host based firewalls, makes it unlikely that the threat actor will be able to remove both security controls.
Detect
If an attacker manages to break into the anti-collision system on our vessel, we need to be able of detecting this fast, and responding to it. The autonomous system should ideally perform the detection on its own, without the need for a human analyst due to the need for fast response. Using human (or AI agents) onshore in addition is also a good idea. As a minimum the system should:
- Log all access requests and authorization requests
- Apply UEBA (user entity behavior analysis) to detect an unusual activity
- Use advanced detection technologies such as security features of a NGFW, a SIEM with robust detection rules, thorough audit logging on all network equipment and endpoints
- Use EDR technology to provide improved endpoint visibility
- Receive and use threat intelligence in relevant technologies
- Use deep packet inspection systems with protocol interpreters for any OT systems part of the anti-collision system
- Map threat models to detection coverage to ensure anticipated attacks are detectable
By using a comprehensive detection approach to cyber events, combined with a well-hardened system, it will be very difficult for a threat actor to take control of the system unnoticed.
Respond and recover
If an attack is detected, it should be dealt with before it can cause any damage. It may be a good idea to conservatively plan for physical response also for an autonomous ship with a cybersecurity intrusion detection, even if the detection is not 100% reliable, especially for a safety critical system. A possible response could be:
- Isolate the collision avoidance system from the local network automatically
- Stop the vessel and maintain position (using DP if available and without security detections, and as a backup to drop anchor)
- Alert nearby ships over radio that “Autonomous ship has lost anti-collision system availability and is maintaining position. Please keep distance. “
- Alert onshore control of the situation.
- Run system recovery
System recovery could entail securing forensic data, automatically analysing data for indicators of compromise and identify patient zero and exploitation path, expanding blast radius to continue analysis through pivots, reinstall all affected systems from trusted backups, update configurations and harden against exploitation path if possible, perform system validation, transfer back to operations with approval from onshore operations. Establishing a response system like this would require considerable engineering effort.
An alternative approach is to maintain position, and wait for humans to manually recover the system and approve returning to normal operation.
The development of autonomous ships, cars and other high-risk applications are subject to regulatory approval. Yet, the focus of authorities may not be on cybersecurity, and the competence of those designing the systems as well as the ones approving them may be stronger in other areas than cyber. This is especially true for sectors where cybersecurity has not traditionally been a big priority due to more manual operations.
A cyber risk recipe for people developing autonomous cyber-physical systems
If we are going to make a recipe for development of responsible autonomous systems, we can summarize this in 5 main steps:
- Maintain good cyber situational awareness. Know what you have in your systems, how it works, and where you are vulnerable – and also keep track of the adversary’s intentions and capabilities. Use this to plan your system designs and operations. Adapt as the situation changes.
- Rely on good practice. Use IEC 62443 and other know IT/OT security practices to guide both design and operation.
- Involve the suppliers and collaborate on defending the systems, from design to operations. We only win through joint efforts.
- Test continuously. Test your assumptions, your systems, your attack surface. Update defenses and capabilities accordingly.
- Consider changing operating mode based on threat level. With good situational awareness you can take precautions when the threat level is high by reducing connectivity to a minimum, moving to lower degree of autonomy, etc. Plan for high-threat situations, and you will be better equipped to meet challenging times.






 One of the typical major accident scenarios considered when building and operating an offshore drilling or production rig, is a gas leak that is ignited, leading to a jet fire, or even worse, an explosion. For this scenario to happen we need three things (from the fire triangle):
One of the typical major accident scenarios considered when building and operating an offshore drilling or production rig, is a gas leak that is ignited, leading to a jet fire, or even worse, an explosion. For this scenario to happen we need three things (from the fire triangle):