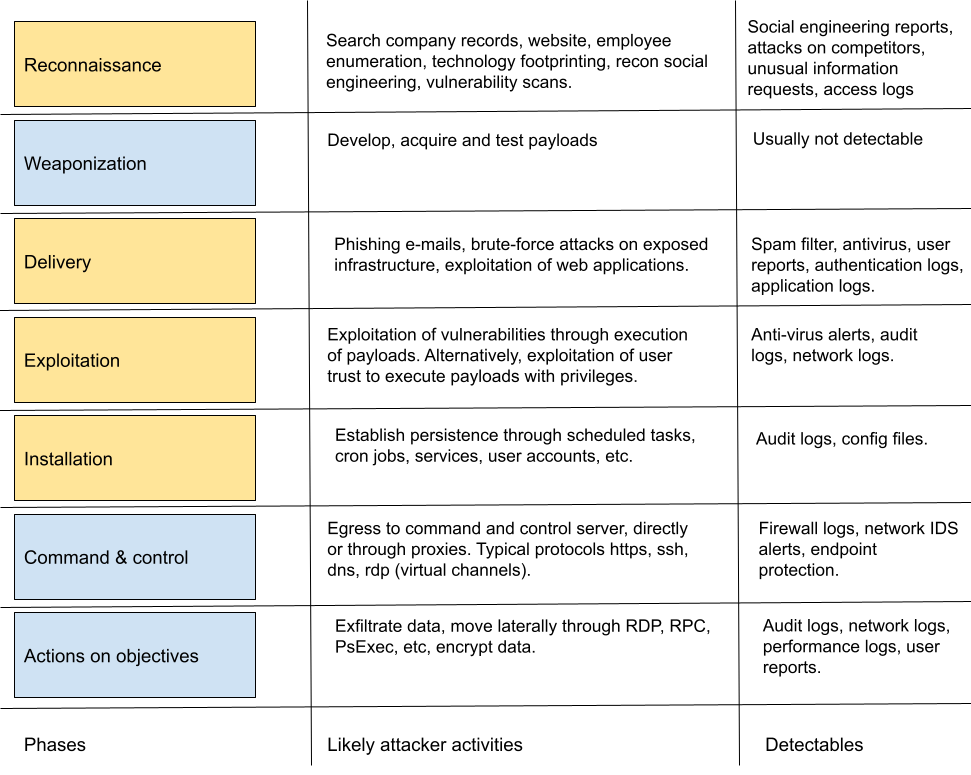
Securing operational technologies (OT) is different from securing enterprise IT systems. Not because the technologies themselves are so different – but the consequences are. OT systems are used to control all sorts of systems we rely on for modern society to function; oil tankers, high-speed trains, nuclear power plants. What is the worst thing that could happen, if hackers take control of the information and communication technology based systems used to operate and safeguard such systems? Obviously, the consequences could be significantly worse than a data leak showing who the customers of an adult dating site are. Death is generally worse than embarrassment.

No electricity could be a consequence of an OT attack.
When people think about cybersecurity, they typically think about confidentiality. IT security professionals will take a more complete view of data security by considering not only confidentiality, but also integrity and availability. For most enterprise IT systems, the consequences of hacking are financial, and sometimes also legal. Think about data breaches involving personal data – we regularly see stories about companies and also government agencies being fined for lack of privacy protections. This kind of thinking is often brought into industrial domains; people doing risk assessments describe consequences in terms such as “unauthorized access to data” or “data could be changed be an unauthorized individual”.
The real consequences we worry about are physical. Can a targeted attack cause a major accident at an industrial plant, leaking poisonous chemicals into the surroundings or starting a huge fire? Can damage to manufacturing equipment disrupt important supply-chains, thereby causing shortages of critical goods such as fuels or food? That is the kind of consequences we should worry about, and these are the scenarios we need to use when prioritizing risks.
Let’s look at three steps we can take to make cyber risks in the physical world more tangible.
Step 1 – connect the dots in your inventory
Two important tools for cyber defenders of all types are “network topologies” and “asset inventory”. If you do not have that type of visibility in place, you can’t defend your systems. You need to know what you have to defend it. A network topology is typically a drawing showing you what your network consists of, like network segments, servers, laptops, switches, and also OT equipment like PLC’s (programmable logic curcuits), pressure transmitters and HMI’s (human-machine interfaces – typically the software used to interact with the sensors and controllers in an industrial plant). Here’s a simple example:

A drawing like this would be instantly recognizable to anyone working with IT or OT systems. In addition to this, you would typically want to have an inventory describing all your hardware systems, as well as all the software running on your hardware. In an environment where things change often, this should be generated dynamically. Often, in OT systems, these will exist as static files such as Excel files, manually compiled by engineers during system design. It is highly likely to be out of date after some time due to lack of updates when changes happen.
Performing a risk assessment based on these two common descriptions is a common exercise. The problem is, that it is very hard to connect this information to the physical consequences we want to safeguard against. We need to know what the “equipment under control” is, and what it is used for. For example, the above network may be used to operate a batch chemical reactor running an exothermic reaction. That is, a reaction that produces heat. Such reactions need cooling, if not the system could overheat, and potentially explode as well if it produces gaseous products. We can’t see that information from the IT-type documentation alone; we need to connect this information to the physical world.
Let’s say the system above is controlling a reactor that has a heat-producing reaction. This reactor needs cooling, which is provided by supplying cooling water to a jacket outside the actual reactor vessel. A controller opens and closes a valve based on a temperature measurement in order to maintain a safe temperature. This controller is the “Temperature Control PLC” in the drawing above. Knowing this, makes the physical risk visible.
Without knowing what our OT system controls, we would be led to think about the CIA triad, not really considering that the real consequences could be a severe explosion that could kill nearby workers, destroy assets, release dangerous chemical to the environment, and even cause damage to neighboring properties. Unfortunately, lack of inventory control, especially connecting industrial IT systems to the physical assets they control, is a very common problem (disclaimer – this is an article from DNV, where I am employed) across many industries.

Step 1 – connect the dots: For every server, switch, transmitter, PLC and so on in your network, you need to know what jobs these items are a part of performing. Only that way, you can understand the potential consequences of a cyberattack against the OT system.
Step 2 – make friends with physical domain experts
If you work in OT security, you need to master a lot of complexity. You are perhaps an expert in industrial protocols, ladder logic programming, or building adversarial threat models? Understanding the security domain is itself a challenge, and expecting security experts to also be experts in all the physical domains they touch, is unrealistic. You can’t expect OT security experts to know the details of all the technologies described as “equipment under control” in ISO standards. Should your SOC analyst be a trained chemical engineer as well as an OT security expert? Or should she know the details of steel strength decreases with a temperature increase due to being engulfed in a jet fire? Of course not – nobody can be an expert at everything.
This is why risk assessments have to be collaborative; you need to make sure you get the input from relevant disciplines when considering risk scenarios. Going back to the chemical reactor discussed above, a social engineering incident scenario could be as follows.
John, who works as a plant engineer, receives a phishing e-mail that he falls for. Believing the attachment to be a legitimate instruction of re-calibration of the temperature sensor used in the reactor cooling control system, he executes the recipe from the the attachment in the e-mail. This tells him to download a Python file from Dropbox folder, and execute it on the SCADA server. By doing so, he calibrates the temperature sensor to report 10 degrees lower temperature than what it really measures. It also installs a backdoor on the SCADA server, allowing hackers to take full control of it over the Internet.
The consequences of this could potentially overpressurizing the reactor, causing a deadly explosion. The lack of cooling on the reactor would make a chemical engineering react, and help understand the potential physical consequences. Make friends with domain experts.
Another important aspect of domain expertise, is knowing the safety barriers. The example above was lacking several safety features that would be mandatory in most locations, such as having a passive pressure-relief system that works without the involvement of any digital technologies. In many locations it is also mandatory to have a process shutdown systems, a control system with separate sensors, PLC’s and networks to intervene and stop the potential accident from happening by using actuators also put in place only for safety use, in order to avoid common cause failures between normal production systems and safety critical systems. Lack of awareness of such systems can sometimes make OT security experts exaggerate the probability of the most severe consequences.
Step 2 – Make friends with domain experts. By involving the right domain expertise, you can get a realistic picture of the physical consequences of a scenario.
Step 3 – Respond in context
If you find yourself having to defend industrial systems against attacks, you need an incident response plan. This is no different from an enterprise IT environment; you also need an incident response plan that takes the operational context into account here. A key difference, though, is that for physical plants your response plan may actually involve taking physical action, such as manually opening and closing valves. Obviously, this needs to be planned – and exercised.

Even attacks that do not affect OT systems directly, may lead to operational changes in the industrial environment. Hydro, for example, was hit with a ransomware attack in 2019, crippling its enterprise IT systems. This forced the company to turn to manual operations of its aluminum production plants. This bears lessons for us all, we need to think about how to minimize impact not just after an attack, but also during the response phase, which may be quite extensive.
Scenario-based playbooks can be of great help in planning as well as execution of response. When creating the playbook we should
- describe the scenario in sufficient detail to estimate affected systems
- ask what it will take to return to operations if affected systems will have to be taken out of service
The latter question would be very difficult to answer for an OT security expert. Again, you need your domain expertise. In terms of the cyber incident response plan, this would lead to information on who to contact during response, who has the authority to make decision about when to move to next steps, and so on. For example, if you need to switch to manual operations in order to continue with recovery of control system ICT equipment in a safe way, this has to be part of your playbook.
Step 3 – Plan and exercise incident response playbooks together with industrial operations. If valves need to be turned, or new pipe bypasses welded on as part of your response activities, this should be part of your playbook.
OT security is about saving lives, the environment and avoiding asset damage
In the discussion above it was not much mention of the CIA triad (confidentiality, integrity and availability), although seen from the OT system point of view, that is still the level we operate at. We still need to ensure only authorized personnel has access to our systems, we need to ensure we protect data during transit and in storage, and we need to know that a packet storm isn’t going to take our industrial network down. The point we want to make is that we need to better articulate the consequences of security breaches in the OT system.
Step 1 – know what you have. It is often not enough to know what IT components you have in your system. You need to know what they are controlling too. This is important for understanding the risk related to a compromise of the asset, but also for planning how to respond to an attack.
Step 2 – make friends with domain experts. They can help you understand if a compromised asset could lead to a catastrophic scenario, and what it would take for an attacker to make that happen. Domain experts can also help you understand independent safety barriers that are part of the design, so you don’t exaggerate the probability of the worst-case scenarios.
Step 3 – plan your response with the industrial context in mind. Use the insight of domain experts (that you know are friends with) to make practical playbooks – that may include physical actions that need to be taken on the factory floor by welders or process operators.