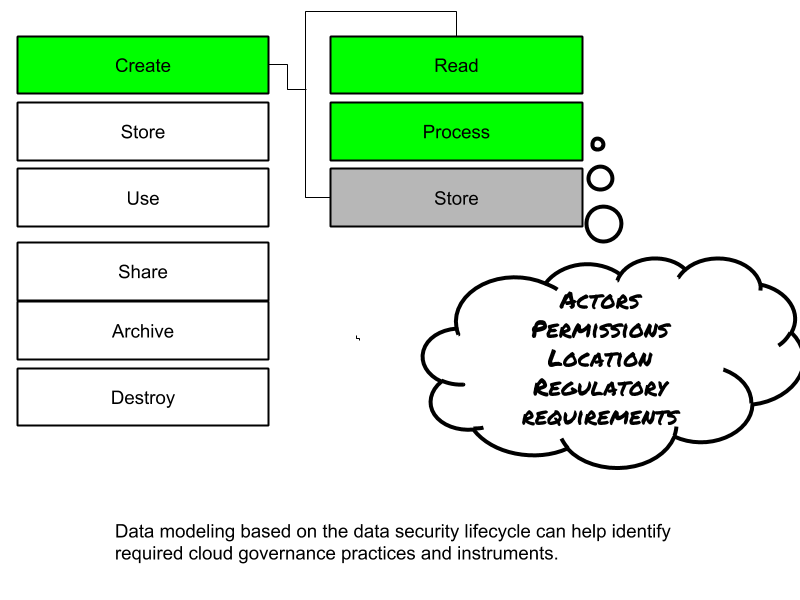
Securing Firestore objects from attacks abusing the JavaScript SDK can be done with the Firestore security rules, which you can read about in my recent post on Firestore.
If you are using the Admin SDK on the server side, you have full access to everything by default. The Firestore security rules do not apply to the Admin SDK. One thing in particular we should be aware of is that the Firesbase admin SDK gives access to management plane functionality, making it possible to change security rules, for example. This is not apparent from the Firebase console or command line tools.

In this blog post we dig into a Firebase project through the Google Cloud console and the gcloud command line tool, where we show how to improve the security of our capture-the-flag app by creating specific service accounts and role bindings for a cloud function. We also explore how to verify that a user is signed in using the Firebase Admin SDK.
A threat model for the flag checker
We have created a demo Firebase project with a simple web application at https://quizman-a9f1b.web.app/. This app has a simple CTF function, where a CTF challenge is presented, and players can verify if their identified flag is correct. The data exchange is primarily done using the JavaScript SDK, protected by security rules. For checking the flag, however, we are using a cloud function. If this cloud function has a vulnerability that allows an attacker to take control over it, that attacker could potentially overwrite the “correct flag”, or even change the security rules protecting the JavaScript SDK access.
Here’s a list of threats and potential consequences:
| Vulnerability | Exploitation | Impact |
| RCE vulnerability in code | Attacker can take full control of the Firebase project environment through the admin SDK | Can read/write to private collection (cheat)Can create other resources (costs money)Can reconfigure security rules (data leaks or DoS) |
| Lack of brute-force protection | Attacker can try to guess flags by automating submission | User can cheatCosts money |
| Lack of authentication | An unauthenticated user can perform function calls | Costs money in spite of not being a real player of the CTF game |
We need to make sure that attackers cannot exploit vulnerabilities to cheat in the program. We also want to protect against unavailability, and abuse that can drive up the cloud usage bill (after all this is a personal project). We will apply a defence-in-depth approach to our cloud function:
- Execution of the function requires the caller to be authenticated. The purpose of this is to limit abuse, and to revoke access to users abusing the app.
- The Firebase function shall only have read access to FIrestore, preferably only to the relevant collections. This will avoid the ability of an attacker with RCE to overwrite data, or to manage resources in the Firebase project.
- For the following events we want to create logs and possibly alerts:
- authenticated user verified token
- unauthenticated user requested token verification
Requiring the user to be authenticated
First we need to make sure that the person requesting to verify a flag is authenticated. We can use a built-in method of the Firebase admin SDK to do this. This method checks that the ID token received is properly signed, and that it is not expired. The good thing about this approach is that it avoids making a call to the authentication backend.
But what if the token has been revoked? It is possible to check if a token is revoked using either security rules (recommended, cheap), or making an extra call to the authentication backend (expensive, not recommended). Since we are not actively revoking tokens in this app, unless a user changes his/her password, we will not bother with this functionality but if you need it, there is documentation how here: https://firebase.google.com/docs/auth/admin/manage-sessions#detect_id_token_revocation.
We need to update our “check flag workflow” from this:
- send flag and challenge ID to cloud function
- cloud function queries Firestore based on challenge ID and gets the “correct flag”
- cloud function compares submitted flag with the correct flag, and returns {success: true/false} as appropriate
to this slightly more elaborate workflow:
- send flag, challenge ID and user token to cloud function
- cloud function verifies token ID
- If invalid: return 403 (forbidden) // simplified to returning 200 with {success: false}
- if valid:
- cloud function queries Firestore based on challenge ID and gets the “correct flag”
- cloud function compares submitted flag with the correct flag, and returns {success: true/false} as appropriate
The following code snippet shows how to perform the validation of the user’s token:
const idTokenResult = await admin.auth().verifyIdToken(idToken);
If the token is valid, we receive a decoded jwt back.
Restricting permissions using IAM roles
By default, a Firebase function initiated with the Firebase admin SDK has been assigned very powerful permissions. It gets automatically set up with a service account that is named as “firebase-adminsdk-random5chars@project-id.iam.gserviceaccount.com”. The service account itself does not have rights associated with it, but it has role bindings to roles that have permissions attached to it.
If you go into the Google Cloud Console, and navigate to “IAM” under your project, you can look up the roles assigned to a principal, such as your service account. For each role you automatically get an assessment of “excess permissions”; those are permissions available through the role bindings but that are not used in the project. Here’s the default configuration for the service account set up for the Admin SDK:
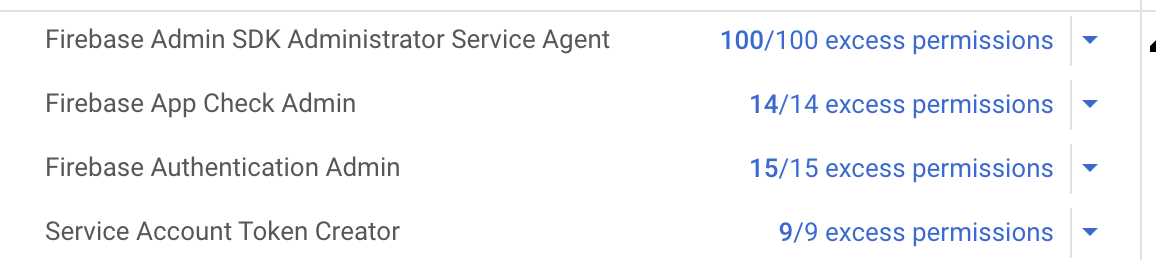
Our Firebase cloud function does not need access to all those permissions. By creating roles that are fit for purpose we can limit the damage an attacker can do if the function is compromised. This is just the same principle in action as when your security awareness training tells you not to run your PC as admin for daily work.
Cloud resources have associated ready-made roles that one can bind a service account to. For Firestore objects the relevant IAM roles are listed here: https://cloud.google.com/firestore/docs/security/iam. We see that there is a viewer role that allows read access to all Firestore resources, called datastore.viewer. We will use this, but be aware it could read all Firestore data in the project, not only the intended objects. Still, we are protecting against deletion, overwriting data, and creation of new resources.
Note that it is possible to create more specific roles. We could create a role that only has permission to read from Firestore entities. We cannot in an IAM role describe exactly which Firestore collection to allow read operations from, but if we create the role flagchecker and assign it the permission datastore.entities.get and nothing else, it is as locked down as we can make it.
To implement this for our cloud function, we create a new service account. This can be done in the Console by going to IAM → Service Accounts → New Service Account. We create the account and assign it the role datastore.viewer.
Our new service account is called quizman-flag-checker.
Now we need to attach this service account to our Firebase function. It is not clear form the Firebase documentation how we can accomplish this, but opening the Google Cloud Console, or using the gcloud command line tool, we can attach our new service account with more restrictive permissions to the Firebase function.
To do this, we go into the Google Cloud console, choose the right project and Compute → Cloud functions. Select the right function, and then hit the “edit” button to change the function. Here you can choose the service account you want to attach to the function.

After changing the runtime service account, we need to deploy the function again. Now the service-to-service authentication is performed with a principal with more sensible permissions; attackers can no longer create their own resources or delete security rules.
Auditing the security configurations of a Firebase function using gcloud
Firebase is great for an easy set-up, but as we have seen it gives us too permissive roles by default. It can therefore be a good idea to audit the IAM roles used in your project.
Key questions to ask about the permissions of a cloud function are:
- What is the service account this function is authenticating as?
- What permissions do I have for this cloud function?
- Do I have permissions that I do not need?
In addition to auditing the configuration, we want to audit changes to the configuration, in particular changes to service accounts, roles, and role bindings. This is easiest done using the log viewer tools in the Google Cloud console.
We’ll use the command line tool gcloud for the auditing, since this makes it possible to automate in scripts.
Service accounts and IAM roles for a Firebase function
Using the Google Cloud command line tool gcloud we can use the command
gcloud functions describe <functionName>
to get a lot of metadata about a function. To extract just the service account used you can pipe it into jq like this:
gcloud functions describe <functionName> --format=”json”| jq “.serviceAccountEmail”
When we have the service account, we can next check which roles are bound to the account. This query is somewhat complex due to the nested data structure for role bindings on a project (for a good description of gcloud IAM queries, see fabianlee.org):
gcloud projects get-iam-policy <projectIdNumber> --flatten="bindings[].members" --filter="bindings.members=serviceAccount:<account-email>" --format="value(bindings.role)"
Running this gives us the following role (as expected): projects/quizman-a9f1b/roles/flagchecker.
Hence, we know this is the only role assigned to this service account. Now we finally need to list the permissions for this role. Here’s how we can do that:
cloud iam roles describe flagchecker --project=quizman-a9f1b --format="value(includedPermissions)”
The output (as expected) is a single permission: datastore.entities.get.