If you Google “how to add login to a Google Site” you get many hits for questions and few answers. I wondered if we could somehow create a Google Site with access control for a “member’s area”. Turns out, you can’t really do that. We can, however, simulate that behavior by creating two sites, where one contains the “public pages” and another one the “private pages”.
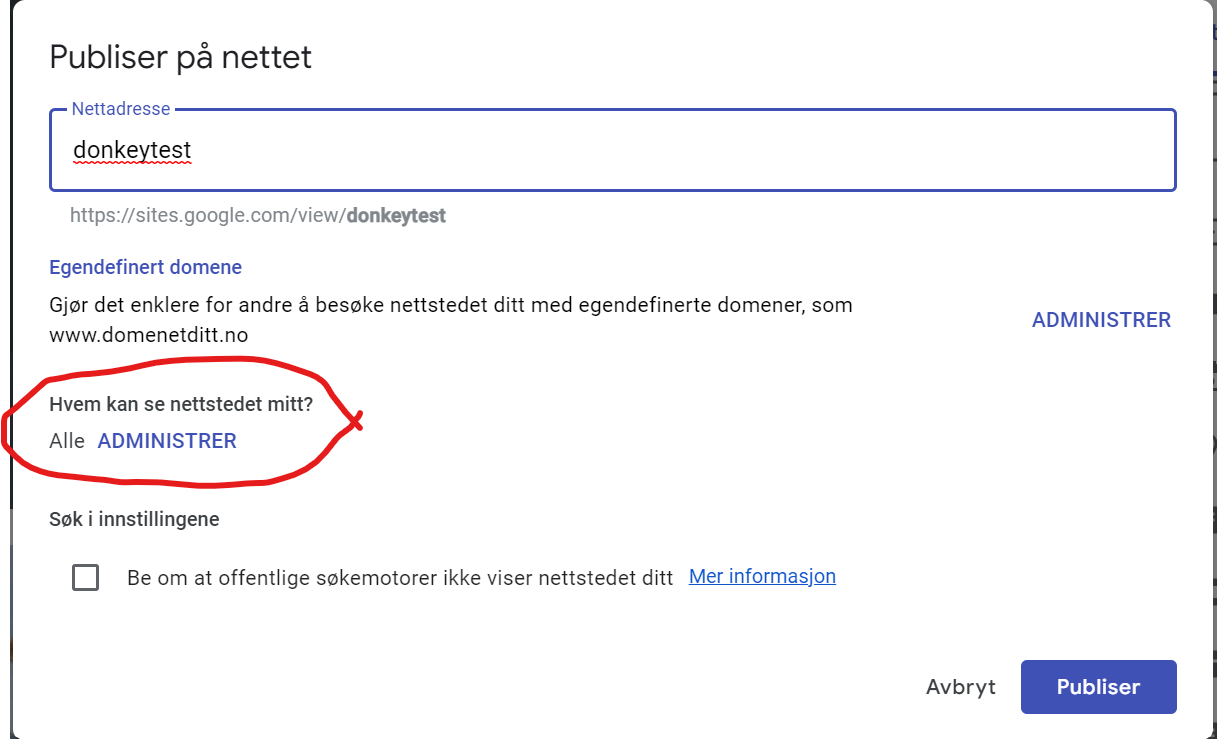
First, we create a site that we want to be public. Here’s an example of a published Google Site: https://sites.google.com/view/donkeytest/start. We publish this one as visible for everyone.
Publish dialog (in Norwegian) – showing access for all for our public page.
Now, create a folder to contain another site, which will be your membership site.
Membership site in its own folder
This one is published only to “specific persons”. These people will need to have Google accounts to access the membership site. Now, we can add new users by using the sharing functions in Google Drive, but we want it to be a bit more automated. This is the reason we put the site in its own folder.
Google used to have a version of Google Sites that could be scripted, but that version is now considered legacy. There is a new version of Google Sites that we are using but that one cannot be scripted. However, we can manipulate permissions for a folder in Google Drive using App Script, and permissions are hierarchical.
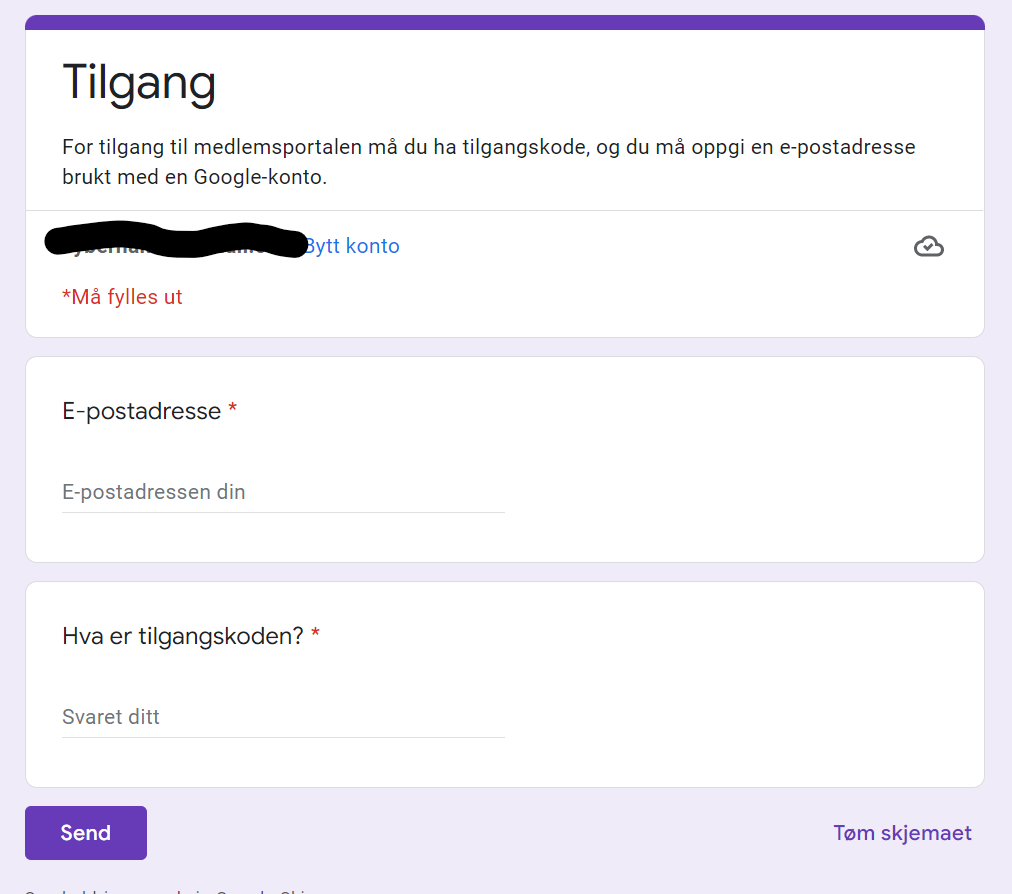
Let’s assume our users have received an access code that grants them access to the site, for example in a purchase process. We can create a Google Form for people to get access after obtaining this code. They will have to add their Gmail address + the secret access code.
Signup form for our membership page (also in Norwegian, tilgangskode = access code)
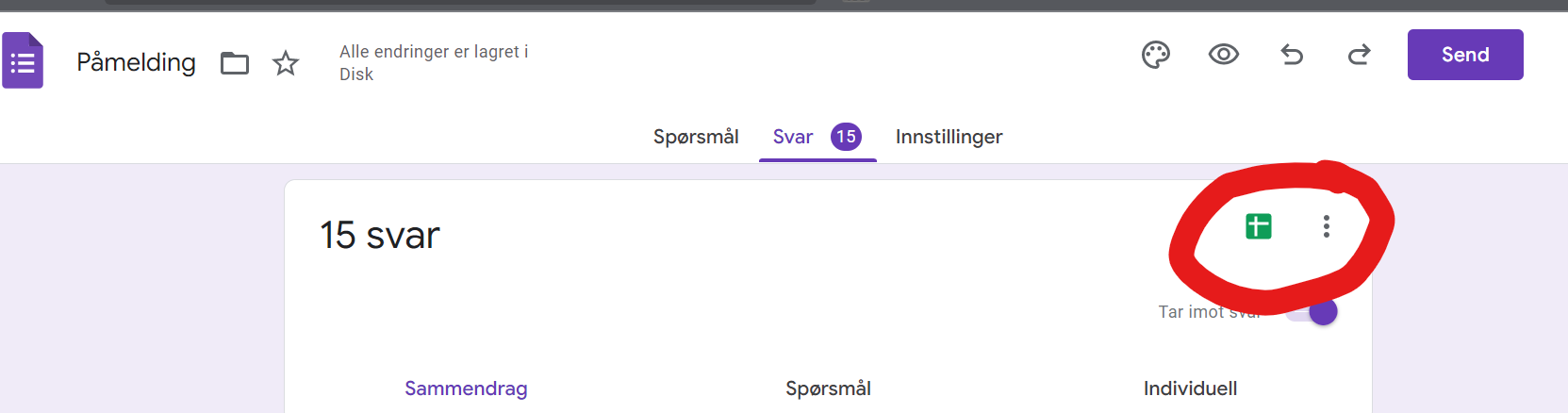
When the user submits this form, we need to process it and grant access to the parent folder of our membership site. First, make sure you go into the answers section, and click the “Google Sheet” symbol to create a Sheet for containing the signups.
Click the green Sheet symbol to create a Google Sheet to hold signup answers.
In Sheets, we create two extra tabs – one for the “secret access code”, and another for a block list in case there are users we want to deny signing up. To make the data from the spreadsheet accessible to Google App Script, we now click the Google App Script link on the Extensions menu in the Google Sheet.
Go to App Script!
Don’t miss future secure and tech posts – sign up here to be notified!
In App Script, we add the Sheets + Gmail services. We create a function to be triggered each time the form is submitted. Our function is called onFormSubmit. We click the “trigger button” in the editor to add a trigger to make this happen.
Trigger button looks like a clock!
In the trigger config, choose trigger source to be “spreadsheet”, and event type to “form submission”. Now the trigger is done, and it is time to write some code. In pseudocode form, this is what needs to happen:
Get the e-mail address of the new user + the access code submitted by the user
Check if the access code is correct
If correct, check if the user is on a block list. If the user is not blocked, grant access to the parent folder of the membership site using the Google Drive service. Send an e-mail to the user that access has been granted.
If incorrect, don’t grant access. Perhaps log the event
The App Script code is just JavaScript. Here’s our implementation.
function onFormSubmit(event) {
var useremail = event.values[1]
var accesscode = event.values[2]
var correctcode = sheetTest()
var blocked = getBlockedUsers()
console.log(blocked)
if (accesscode == correctcode) {
if (blocked.flat().includes(useremail)) {
Logger.log("Blocked user is attempting access: " + useremail)
} else {
Logger.log("Provide user with access: " + useremail)
var secretfolder = DriveApp.getFolderById("<id-of-folder>")
secretfolder.addViewer(useremail)
GmailApp.sendEmail(useremail, "Access to Membership Site", "Body text for email goes here...")
}
} else {
Logger.log("Deny user access")
}
}
function sheetTest() {
var sheet = SpreadsheetApp.openById("<Spreadsheet-ID>");
var thiscell = sheet.getSheets()[1].getDataRange().getValues()
var correctcode = thiscell[thiscell.length-1][0];
return correctcode
}
function getBlockedUsers() {
var sheet = SpreadsheetApp.openById("<Spreadsheet-ID>");
var blocklist = sheet.getSheets()[2].getDataRange().getValues()
return blocklist
}
Now, we are done with the “backend”. We can now create links in the navigation menus between the public site and the membership one, and you will have a functioning Google Site with a membership area as seen from the user’s point of view.
Modern operating systems have robust systems for creating audit trails built-in. They are very useful for detecting attacks, and understanding what has happened on a machine.
To make sense of the crime you need evidence. Ensure you capture enough logs to handle relevant threat scenarios against your assets.
Not all the features that are useful for security monitoring are turned on by default – you need to plan auditing. The more you audit, the more visibility you gain in theory, but there are trade-offs.
More data gives you more data – and more noise. Logging more than you need makes it harder to find the events that matter
More data can be useful for visibility, but can also quickly fill up your disk with logs if you turn on too much
More data can give you increased visibility of what is going on, but this can be at odds with privacy requirements and expectations
Brute-force attacks: export data and use Excel to make sense of it
Brute-force attacks are popular among attackers, because there are many systems using weak passwords and that are lacking reasonable password policies. You can easily defend against naive brute-force attacks using rate limiting and account lockouts.
If you expose your computer directly on the Internet on port 3389 (RDP), you will quickly see thousands of login attempts. The obvious answer to this problem is to avoid exposing RDP directly on the Internet. This will also cut away a lot of the noise, making it easier to detect actual intrusions.
Logon attempts on Windows will generate Event ID 4625 for failed logons, and Event ID 4624 for successful logons. An easy way to detect naive attacks is thus to look for a series of failed attempts in a short time for the same username, followed by a successful logon for the same user. A practical way to do this, is to use PowerShell to extract the relevant data, and export it to a csv file. You can then import the data to Excel for easy analysis.
For a system exposed on the Internet, there will be thousands of logons for various users. Exporting data for non-existent users makes no sense (this is noise), so it can be a good idea to pull out the users first. If we are interested in detecting attacks on local users on a machine, we can use the following Cmdlet:
Now we first fetch the logs with Event ID’s 4624, 4625. You need to do this from an elevated shell to read the events from the Windows security log. For more details on scripting log analysis and making sense of the XML log format that Windows is using, please refer to this excellent blog post: How to track Windows events with Powershell.
Now we can loop over the $events variable and pull out the relevant data. Note that we check that the logon attempt is for a target account that is a valid user account on our system.
Now we can import the data in Excel to analyze it. We have detected there are many logon attempts for the username “victim”, and filtering on this value clearly shows what has happened.
TimeCreated
EventID
TargetUserName
LogonType
WorkstationName
IpAddress
3/6/2022 9:26:54 PM
4624
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:54 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:54 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:54 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:54 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:54 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:54 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:53 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:53 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:53 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:26:53 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:38 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4624
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
3/6/2022 9:23:37 PM
4625
victim
Network
WinDev2202Eval
REDACTED
Log showing successful brute-force attack coming from a Windows workstation called WinDev2202Eval, with the source ip address.
Engineering visibility
The above is a simple example of how scripting can help pull out local logs. This works well for an investigation after an intrusion but you want to detect attack patterns before that. That is why you want to forward logs to a SIEM, and to create alerts based on attack patterns.
For logon events the relevant logs are created by Windows without changing audit policies. There are many other very useful security logs that can be generated on Windows, that require you to activate them. Two very useful events are the following:
Event ID 4688: A process was created. This can be used to capture what an attacker is doing as post-exploitation.
Event ID 4698: A scheduled task was created. This is good for detecting a common tactic for persistence.
Taking into account the trade-offs mentioned in the beginning of this post, turning on the necessary auditing should be part of your security strategy.
Securing operational technologies (OT) is different from securing enterprise IT systems. Not because the technologies themselves are so different – but the consequences are. OT systems are used to control all sorts of systems we rely on for modern society to function; oil tankers, high-speed trains, nuclear power plants. What is the worst thing that could happen, if hackers take control of the information and communication technology based systems used to operate and safeguard such systems? Obviously, the consequences could be significantly worse than a data leak showing who the customers of an adult dating site are. Death is generally worse than embarrassment.
No electricity could be a consequence of an OT attack.
When people think about cybersecurity, they typically think about confidentiality. IT security professionals will take a more complete view of data security by considering not only confidentiality, but also integrity and availability. For most enterprise IT systems, the consequences of hacking are financial, and sometimes also legal. Think about data breaches involving personal data – we regularly see stories about companies and also government agencies being fined for lack of privacy protections. This kind of thinking is often brought into industrial domains; people doing risk assessments describe consequences in terms such as “unauthorized access to data” or “data could be changed be an unauthorized individual”.
The real consequences we worry about are physical. Can a targeted attack cause a major accident at an industrial plant, leaking poisonous chemicals into the surroundings or starting a huge fire? Can damage to manufacturing equipment disrupt important supply-chains, thereby causing shortages of critical goods such as fuels or food? That is the kind of consequences we should worry about, and these are the scenarios we need to use when prioritizing risks.
Let’s look at three steps we can take to make cyber risks in the physical world more tangible.
Step 1 – connect the dots in your inventory
Two important tools for cyber defenders of all types are “network topologies” and “asset inventory”. If you do not have that type of visibility in place, you can’t defend your systems. You need to know what you have to defend it. A network topology is typically a drawing showing you what your network consists of, like network segments, servers, laptops, switches, and also OT equipment like PLC’s (programmable logic curcuits), pressure transmitters and HMI’s (human-machine interfaces – typically the software used to interact with the sensors and controllers in an industrial plant). Here’s a simple example:
An example of a simplified network topology
A drawing like this would be instantly recognizable to anyone working with IT or OT systems. In addition to this, you would typically want to have an inventory describing all your hardware systems, as well as all the software running on your hardware. In an environment where things change often, this should be generated dynamically. Often, in OT systems, these will exist as static files such as Excel files, manually compiled by engineers during system design. It is highly likely to be out of date after some time due to lack of updates when changes happen.
Performing a risk assessment based on these two common descriptions is a common exercise. The problem is, that it is very hard to connect this information to the physical consequences we want to safeguard against. We need to know what the “equipment under control” is, and what it is used for. For example, the above network may be used to operate a batch chemical reactor running an exothermic reaction. That is, a reaction that produces heat. Such reactions need cooling, if not the system could overheat, and potentially explode as well if it produces gaseous products. We can’t see that information from the IT-type documentation alone; we need to connect this information to the physical world.
Let’s say the system above is controlling a reactor that has a heat-producing reaction. This reactor needs cooling, which is provided by supplying cooling water to a jacket outside the actual reactor vessel. A controller opens and closes a valve based on a temperature measurement in order to maintain a safe temperature. This controller is the “Temperature Control PLC” in the drawing above. Knowing this, makes the physical risk visible.
Without knowing what our OT system controls, we would be led to think about the CIA triad, not really considering that the real consequences could be a severe explosion that could kill nearby workers, destroy assets, release dangerous chemical to the environment, and even cause damage to neighboring properties. Unfortunately, lack of inventory control, especially connecting industrial IT systems to the physical assets they control, is a very common problem (disclaimer – this is an article from DNV, where I am employed) across many industries.
An example of a physical system: a continuously stirred-tank reactor (CSTR) for producing a chemical in a batch-type process.
Step 1 – connect the dots: For every server, switch, transmitter, PLC and so on in your network, you need to know what jobs these items are a part of performing. Only that way, you can understand the potential consequences of a cyberattack against the OT system.
Step 2 – make friends with physical domain experts
If you work in OT security, you need to master a lot of complexity. You are perhaps an expert in industrial protocols, ladder logic programming, or building adversarial threat models? Understanding the security domain is itself a challenge, and expecting security experts to also be experts in all the physical domains they touch, is unrealistic. You can’t expect OT security experts to know the details of all the technologies described as “equipment under control” in ISO standards. Should your SOC analyst be a trained chemical engineer as well as an OT security expert? Or should she know the details of steel strength decreases with a temperature increase due to being engulfed in a jet fire? Of course not – nobody can be an expert at everything.
This is why risk assessments have to be collaborative; you need to make sure you get the input from relevant disciplines when considering risk scenarios. Going back to the chemical reactor discussed above, a social engineering incident scenario could be as follows.
John, who works as a plant engineer, receives a phishing e-mail that he falls for. Believing the attachment to be a legitimate instruction of re-calibration of the temperature sensor used in the reactor cooling control system, he executes the recipe from the the attachment in the e-mail. This tells him to download a Python file from Dropbox folder, and execute it on the SCADA server. By doing so, he calibrates the temperature sensor to report 10 degrees lower temperature than what it really measures. It also installs a backdoor on the SCADA server, allowing hackers to take full control of it over the Internet.
The consequences of this could potentially overpressurizing the reactor, causing a deadly explosion. The lack of cooling on the reactor would make a chemical engineering react, and help understand the potential physical consequences. Make friends with domain experts.
Another important aspect of domain expertise, is knowing the safety barriers. The example above was lacking several safety features that would be mandatory in most locations, such as having a passive pressure-relief system that works without the involvement of any digital technologies. In many locations it is also mandatory to have a process shutdown systems, a control system with separate sensors, PLC’s and networks to intervene and stop the potential accident from happening by using actuators also put in place only for safety use, in order to avoid common cause failures between normal production systems and safety critical systems. Lack of awareness of such systems can sometimes make OT security experts exaggerate the probability of the most severe consequences.
Step 2 – Make friends with domain experts. By involving the right domain expertise, you can get a realistic picture of the physical consequences of a scenario.
Step 3 – Respond in context
If you find yourself having to defend industrial systems against attacks, you need an incident response plan. This is no different from an enterprise IT environment; you also need an incident response plan that takes the operational context into account here. A key difference, though, is that for physical plants your response plan may actually involve taking physical action, such as manually opening and closing valves. Obviously, this needs to be planned – and exercised.
If welding will be a necessary part of handling your incident, coordinating with the industrial operations side better be part of your incident response playbooks.
Even attacks that do not affect OT systems directly, may lead to operational changes in the industrial environment. Hydro, for example, was hit with a ransomware attack in 2019, crippling its enterprise IT systems. This forced the company to turn to manual operations of its aluminum production plants. This bears lessons for us all, we need to think about how to minimize impact not just after an attack, but also during the response phase, which may be quite extensive.
Scenario-based playbooks can be of great help in planning as well as execution of response. When creating the playbook we should
describe the scenario in sufficient detail to estimate affected systems
ask what it will take to return to operations if affected systems will have to be taken out of service
The latter question would be very difficult to answer for an OT security expert. Again, you need your domain expertise. In terms of the cyber incident response plan, this would lead to information on who to contact during response, who has the authority to make decision about when to move to next steps, and so on. For example, if you need to switch to manual operations in order to continue with recovery of control system ICT equipment in a safe way, this has to be part of your playbook.
Step 3 – Plan and exercise incident response playbooks together with industrial operations. If valves need to be turned, or new pipe bypasses welded on as part of your response activities, this should be part of your playbook.
OT security is about saving lives, the environment and avoiding asset damage
In the discussion above it was not much mention of the CIA triad (confidentiality, integrity and availability), although seen from the OT system point of view, that is still the level we operate at. We still need to ensure only authorized personnel has access to our systems, we need to ensure we protect data during transit and in storage, and we need to know that a packet storm isn’t going to take our industrial network down. The point we want to make is that we need to better articulate the consequences of security breaches in the OT system.
Step 1 – know what you have. It is often not enough to know what IT components you have in your system. You need to know what they are controlling too. This is important for understanding the risk related to a compromise of the asset, but also for planning how to respond to an attack.
Step 2 – make friends with domain experts. They can help you understand if a compromised asset could lead to a catastrophic scenario, and what it would take for an attacker to make that happen. Domain experts can also help you understand independent safety barriers that are part of the design, so you don’t exaggerate the probability of the worst-case scenarios.
Step 3 – plan your response with the industrial context in mind. Use the insight of domain experts (that you know are friends with) to make practical playbooks – that may include physical actions that need to be taken on the factory floor by welders or process operators.
To build organizations with cultures that reinforce security, we need to turn from awareness training, to a holistic approach taking human performance into account. In this post, we look at performance shaping factors as part of the root cause of poor security decisions, and suggest 4 key delivery domains for improved cybersecurity performance in organizations; leadership, integrating security in work processes, getting help when needed, and finally, delivering training and content.
This is a blog post about what most people call “security awareness”. This term is terrible; being aware that security exists doesn’t really help much. I’ve called it “pointing fingers solves nothing” – because a lot of what we do to build security awareness, has little to no effect. Or sometimes, the activities we introduce can even make us more likely to get hacked!
We want organizational cultures that make us less vulnerable to cyber threats. Phishing your own employees and forcing them to click through e-learning modules about hovering links in e-mails will not give us that.
What do we actually want to achieve?
Cybersecurity has to support the business in reaching its goals. All companies have a purpose; there is a reason they exist. Why should people working at a cinema care about cybersecurity for example? Let us start with a hypothetical statement of why you started a cinema!
What does the desire to share the love of films have to do with cybersecurity? Everything!
We love film. We want everyone to be able to come here and experience the magic of the big screen, the smell of popcorn and feeling as this is the only world that exists.
Mr. Moon (Movie Theater Entrepreneur)
Running a cinema will expose you to a lot of business risks. Because of all the connected technologies we use to run our businesses, a cyber attack can disturb almost any business, including a cinema. It could stop ticket sales, and the ability to check tickets. It could cost so much money that the cinema goes bankrupt, for example through ransomware. It could lead to liability issues if a personal data breach occurs, and the data was not protected as required by law. In other words; there are many reasons for cinema entrepreneurs to care about cybersecurity!
An “awareness program” should make the cinema more resilient to cyber attacks. We want to reach a state where the following would be true:
We know how to integrate security into our work
We know how information security helps us deliver on our true purpose
We know how to get help with security when we need it
Knowing when and how to get help is a key cybersecurity capability
Design principles for awareness programs
We have concluded that we want security be a natural part of how we work, and that people are motivated to follow the expected practices. We also know from research that the reason people click on a phishing e-mail or postpones updating their smartphone, is not a lack of knowledge, but rather a lack of motivation to prioritize security over short-term productivity. There can be many reasons for this, ranging from lack of situational awareness to stress and lack of time.
From human factors engineering, we know that our performance at work depends on many factors. There are factors that can significantly degrade our capability to make the right decisions, despite having the knowledge required to make the right decisions. According to the SPAR-H methodology for human reliability analysis, the following PSF’s (performance shaping factors) can greatly influence our ability to make good decisions:
Available time
Stress/stressors
Task complexity
Experience and training
Procedures
Human-machine interface
Fitness for duty
It is thus clear that telling people to avoid clicking suspicious links in e-mails from strangers will not be enough to improve the cybersecurity performance of the organization. When we want our program to actually make our organization less likely to see severe consequences from cyber attacks we need to do more. To guide us in making such a program, I suggest the following 7 design principles for building security cultures:
Management must show that security is a priority
Motivation before knowledge
Policies are available and understandable
Culture optimizing for human reliability
Do’s before don’ts
Trust your own paranoia – report suspicious observations
Talk the walk – keep security on the agenda
Based on these principles, we collect activities into four delivery domains for cybersecurity awareness;
Leadership
Work integration
Access to help
Training and content
The traditional “awareness” practices we all know such as threat briefs, e-learning and simulated phishing campaigns fit into the fourth domain here. Those activities can help us build cyber resilience but they do depend on the three other domains supporting the training content.
Delivery domain 1 – Leadership
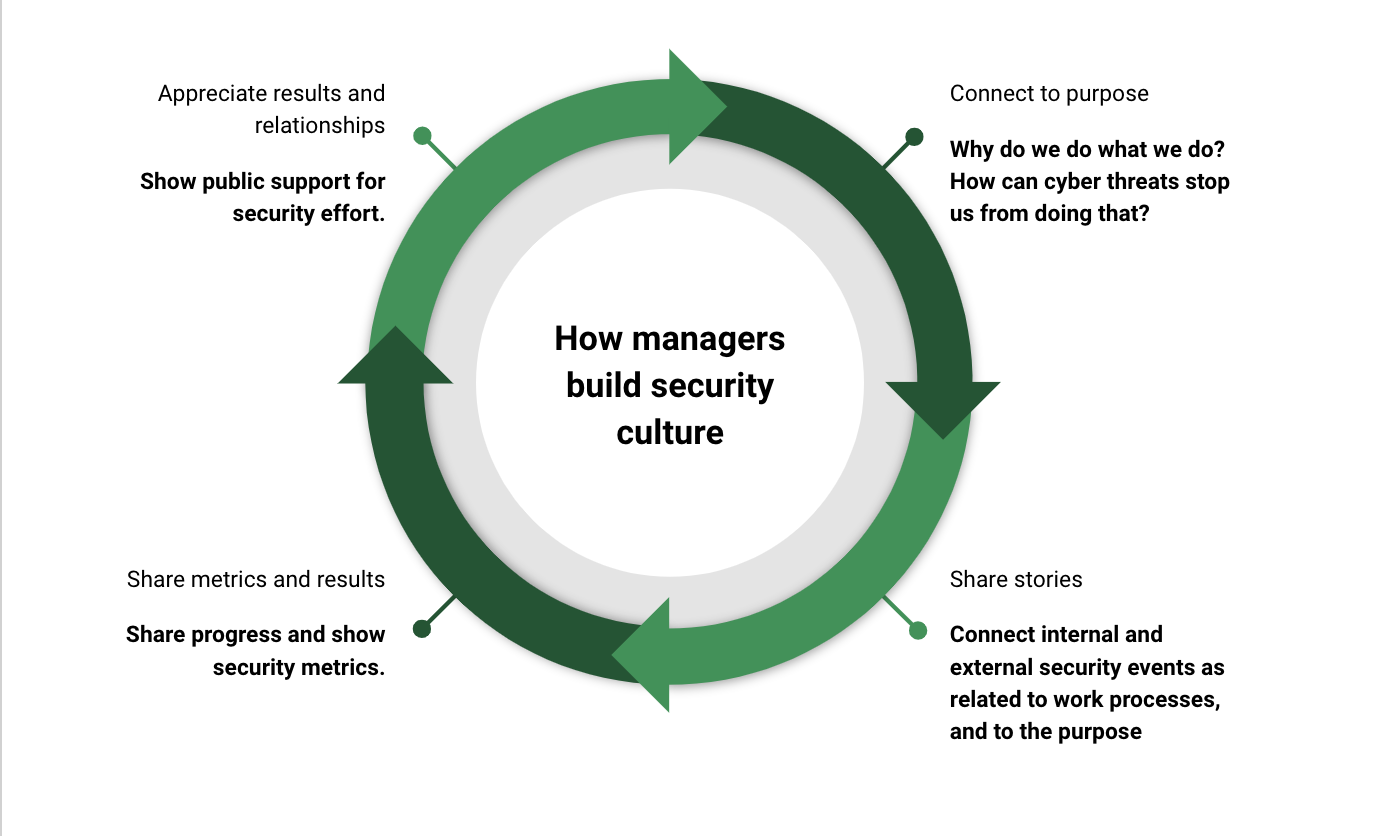
Leaders play a very important role in the implementation of a security aware organization culture. The most important part of the responsibility of leaders is to motivate people to follow security practices. When leaders respect security policies, and make this visible, it inspires and nudges others to follow those practices too. Leaders should also share how security helps support the purpose of the organization. Sharing the vision is perhaps the most important internally facing job of senior management, and connecting security to that vision is an important part of the job. Without security, the vision is much more likely to never materialize, it will remain a dream.
Further, leaders should seek to draw in relevant security stories to drive motivation for good practice. When a competitor is hit with ransomware, the leader should draw focus to it internally. When the organization was subject to a targeted attack, but the attack never managed to cause any harm due to good security controls, that is also worth sharing; the security work we do every day is what allows us to keep delivering services and products to customers.
The leadership wheel; building motivation for security is a continuous process
Delivery domain 2 – work integration
Integrating security practices into how we deliver work, is perhaps the most important deliberate action to take for organizations. The key tool we need to make this reality is threat modeling. We draw up the business process in a flowchart, and then start to think like an attacker. How could cyber attacks disturb or exploit our business process? Then we build the necessary controls into the process. Finally, we need to monitor if the security controls are working as intended, and improve where we see gaps. This way, security moves from something we focus on whenever we read about ransomware in the news, to something we do every day as part of our normal jobs.
Let’s take an example. At our cinema, a key business process is selling tickets to our movies. We operate in an old-fashioned way, and the only way to buy tickets is to go to the ticket booth at the entrance of the cinema and buy your ticket.
How can cyber attacks disturb ticket sales over the counter?
Let’s outline what is needed to buy a ticket:
A computer connected a database showing available tickets
Network to send confirmation of ticket purchase to the buyer
Printer to print paper tickets
A payment solution to accept credit card payments, and perhaps also cash
There are many cyber attacks that could create problems here. A ransomware attack removing the ability to operate the ticket inventory for example, or a DDoS attack stopping the system from sending ticket ocnfirmations. Also, if the computer used by the seller is also used for other things such as e-mail and internet browsing, there are even more possibilities of attacks. We can integrate some security controls into this process:
Use only a hardened computer for the ticket sales
Set up ticket inventory systems that are less vulnerable to common attacks, e.g. use a software-as-a-service solution with good security. Choosing software tools with good security posture is always a good idea.
Provide training to the sales personnel on common threats that could affect ticket sales, including phishing, no shadow IT usage, and how to report potential security incidents
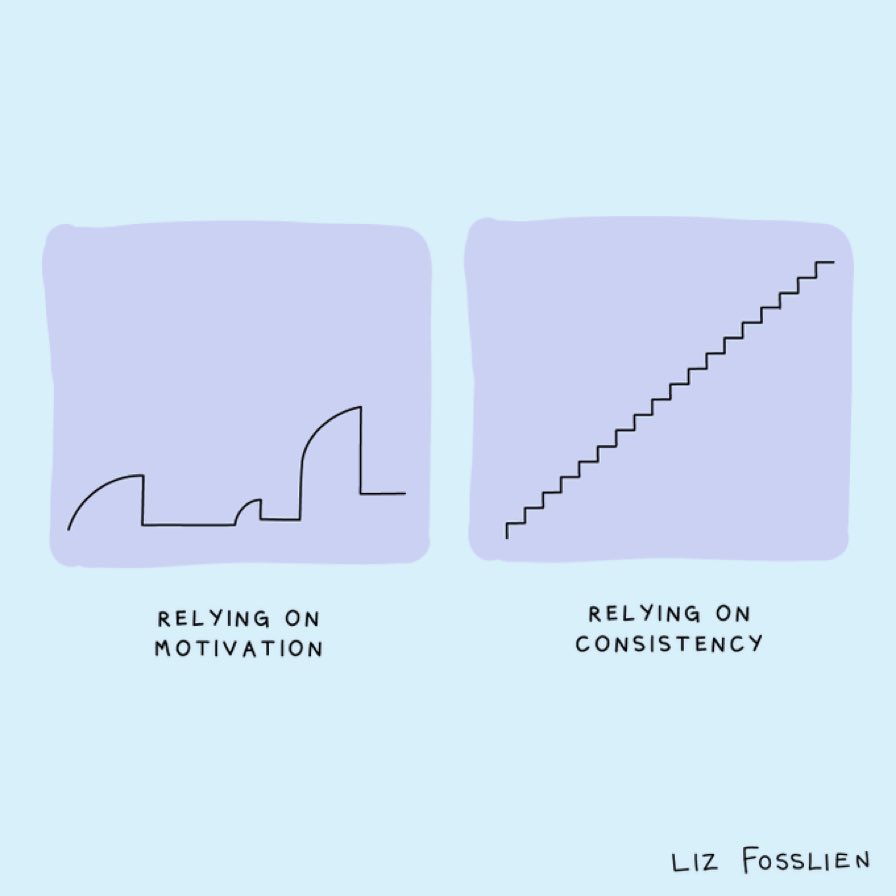
By going through every business process like this, and looking at how we can improve the cybersecurity for each process, we help make security a part of the process, a part of how we do business. And as we know, consistency beats bursts of effort, every time.
Consistency beats motivational bursts every time. Make security a part of how we do work every day, and focus on continuous improvement. That’s how we beat the bad guys, again and again.
Delivery domain 3 – access to help
Delivery domain 3 is about access to help. You don’t build security alone, we do it together. There are two different types of help you need to make available:
I need help to prepare so that our workflows and our knowledge is good enough. Software developers may need help from security specialists to develop threat models or improve architectures. IT departments may need help designing and setting up security tools to detect and stop attacks. These are things we do before we are attacked, and that will help us reduce the probability of a successful attack, and help us manage attacks when they happen.
The other type of help we need, is when we have an active attack. We need to know who to call to get help kicking the cyber adversaries out and reestablishing our business capabilities
You may have the necessary competence in your organization to both build solid security architectures (help type 1) and to respond to incidents (help type 2). If not, you may want to hire consultants to help you design the required security controls. You may also want to contract with a service provider that offers managed detection and response, where the service provider will take care of monitoring your systems and responding to attacks. You could also sign up for an incident response retainer; then you have an on-call team you can call when the cyber villains are inside your systems and causing harm.
Delivery domain 4 – training and content
Our final domain is where the content lives. This is where you provide e-learning, you do phishing simulations, and write blog posts.
About 50% of the effort done in providing the “knowledge part” of awareness training should be focused on baseline security. These are security aspects that everyone in the organization would need to know. Some typical examples of useful topics include the following:
Social engineering and phishing: typical social engineering attacks and how to avoid getting tricked
Policies and requirements: what are the rules and requirements we need to follow?
Reporting and getting help: how do we report a security incident, and what happens then?
Threats and key controls: why do we have the controls we do and how do they help us stop attacks?
Shadow IT: why we should only use approved tools and systems
Simulated phishing attacks are commonly used as part of training. The effect of this is questionable if done the way most organizations do them; send out a collection of phishing e-mails and track who is clicking them, or providing credentials on a fake login page. Everyone can be tricked if the attack is credible enough, and this can quickly turn into a blame game eroding trust in the organization.
Simulated phishing can be effective to provide more practical insights into how social engineering works. In other words, if it is used as part of training, and not primarily as a measurement, it can be good. It is important to avoid “pointing fingers”, and remember that our ability to make good decisions are shaped less by knowledge than performance shaping factors. If you see that too many people are falling for phishing campaigns, consider what could be the cause of this.
When it comes to e-learning, this can be a good way to provide content to a large population, and manage the fact that people join and leave organizations all the time. E-learning content should be easy to consume, and in small enough chunks to avoid becoming a drain on people’s time.
In addition to the baseline training we have discussed here, people who are likely to be targeted with specific attacks, or whose jobs increase the chance of severe consequences of cyber attacks, should get specific training relevant to their roles. For example, a financial department’s workers with authority to pay invoices, should get training in avoiding getting tricked by fake invoices, or to fall for typical fraud types related to business payments.
The last part should close the circle by helping management provide motivation for security. Are there recent incidents managers should know about? Managers should also get security metrics that provide insight into the performance of the organization, both for communication to the people in the organization, and to know if they resources they are investing in for security are actually bringing the desired benefit.
tl;dr – key takeaways for security awareness pushers
The most important take-away from this post is the fact that people’s performance when making security decisions is shaped both by knowledge, and by performance shaping factors. Building a strong security culture should optimize for good security decisions. This means we need to take both knowledge, leadership and the working environment into account. We have suggested 7 design principles to help build awareness programs that work. The principles are:
Management must show that security is a priority
Motivation before knowledge
Policies are available and understandable
Culture optimizing for human reliability
Do’s before don’ts
Trust your own paranoia – report suspicious observations
Talk the walk – keep security on the agenda
Based on the principles we suggested that awareness programs consider 4 delivery domains: Leadership, Work Integration, Access to Help, and Training & Content.
When attackers target our systems, they leave traces. The first place to look is really the logs. Hopefully the most important logs are being collected and sent to a SIEM (security incident and event management) system, but in any case, we need to know how to search logs to find traces of malicious activity. Let’s consider three very common attack scenarios:
• Brute-force attack on exposed remote access port (SSH or RDP) • Establishing persistence through a cron job or a scheduled task • Adding accounts or credentials to maintain persistence
Attackers leave footprints from their actions. The primary tool for figuring out what happened on a system, is log analysis.
Brute force
Brute-force attack: an attacker may try to gain access by guessing a password. This will be visible in logs through a number of failed logon attempts, often from the same ip address. If your system is exposed to the Internet, this is constantly ongoing. The attackers are not human operators but botnets scanning the entire Internet, hoping to gain access. An effective way of avoiding this is to reduce the attack surface and not expose RDP or SSH directly on the internet.
For Windows, failed logon attempts will generate event log entries with Event ID 4625. What you should be looking for is a number of failed attempts (ID 4625), followed by a successful attempt from the same ip address. Successful logins have Event ID 4624. You will need administrator privileges to read the Windows logs. You can use the Event Viewer application on Windows to do this, but if you want to create a more automated detection, you can use a PowerShell script to check the logs. You still need that administrator access though.
You can also use Get-EventLog if you are on PowerShell 5, but that commandlet is not longer present in Powershell 7.
For attacks on SSH on Linux, you will find entries in the authpriv file. But the easiest way to spot malicious logon attempts is to use the command “lastb” that will show you the last failed logon attempts. This command requires sudo privileges. If you correlate a series of failed attempts reported by “lastb” with a successful attempt found in “authpriv” from the same ip address, you probably have a breach.
lastb: The last 10 failed login attempts on a cloud hosted VM exposing SSH on port 22 to the Internet.
Persistence
Let’s move on to persistence through scheduled tasks or cron jobs
The Event ID you are looking for on Windows is 4698. This means a scheduled task was created. There are many reasons to create scheduled tasks; it can be related to software updates, cleanup operations, synchronization tasks and many other things. It is also a popular way to establish persistence for an attacker. If you have managed to drop a script or a binary file on a target machine, and set a scheduled task to execute this on a fixed interval, for example every 5 minutes, you have an easy way to make malware reach out to a command and control server on the Internet.
There are two types of scheduled tasks to worry about here; one is running under the user account. This task will only run when the user is logged on to the computer. If the attacker can establish a scheduled task to run with privileges, the task will run without having a user being logged on – but the computer must of course be in a running state. Because of this, it is a good idea to check the user account that created the scheduled task.
Cron jobs are logged to different files depending on the system you are on. Most systems will log cron job execution to /var/log/syslog, whereas some, such as CoreOS and Amazon Linux, will log to /var/log/cron. For a systemd based Linux distro, you can also use “journalctl -u cron” to view the cron job logs. Look for jobs executing commands or binaries you don’t know what is. Then verify what those are.
You do not get exit codes in the default cron logs, only what happens before the command in the cron job executes. Exit logs are by default logged to the mailbox of the job’s owner but this can be configured to log to a file instead. Usually seeing the standard cron logs is sufficient to discover abuse of this feature to gain persistence or run C2 communications.
Adding accounts
Finally, we should check if an attacker has added an account, a common way to establish extra persistence channels.
For Windows, the relevant Event ID is 4720. This is generated every time a user account is created, whether centrally on a domain controller, or locally on a workstation. If you do not expect user accounts to be created on the system, every Event ID like this should be investigated. The Microsoft documentation has a long list of signals to monitor for regarding this event: https://docs.microsoft.com/en-us/windows/security/threat-protection/auditing/event-4720.
On Linux, the command “adduser” can be used to add a new user. Creating a new user will create an entry in the /var/log/auth.log file. Here’s an example form adding a user called “exampleuser” on Ubuntu (running on a host called “attacker”).
Jan 29 20:14:27 attacker sudo: cyberhakon : TTY=pts/0 ; PWD=/home/cyberhakon ; USER=root ; COMMAND=/usr/sbin/useradd exampleuser Jan 29 20:14:27 attacker useradd[6211]: new group: name=exampleuser, GID=1002 Jan 29 20:14:27 attacker useradd[6211]: new user: name=exampleuser, UID=1001, GID=1002, home=/home/exampleuser, shell=/bin/sh
Changing the password for the newly created user is also visible in the log.
an 29 20:18:20 attacker sudo: cyberhakon : TTY=pts/0 ; PWD=/var/log ; USER=root ; COMMAND=/usr/bin/passwd exampleuser Jan 29 20:18:27 attacker passwd[6227]: pam_unix(passwd:chauthtok): password changed for exampleuser
Summary: we can detect a lot of common attacker behavior just by looking at the default system logs. Learning how to look for such signals is very useful for incident response and investigations. Even better is to be prepared and forward logs to a SIEM, and create alerts based on behavior that is expected from attackers, but not from regular system use. Then you can stop the attackers before much damage is done.
Let’s set up a server to run Vulnerable Norris. An attacker discovers that the web application has a remote command injection vulnerability, and exploits it to gain a reverse shell. The attackers copy their own SSH public keys onto the device, and uses it as a foothold in the network. How can we detect and stop this from happening, even if we don’t know that the application itself has a vulnerability?
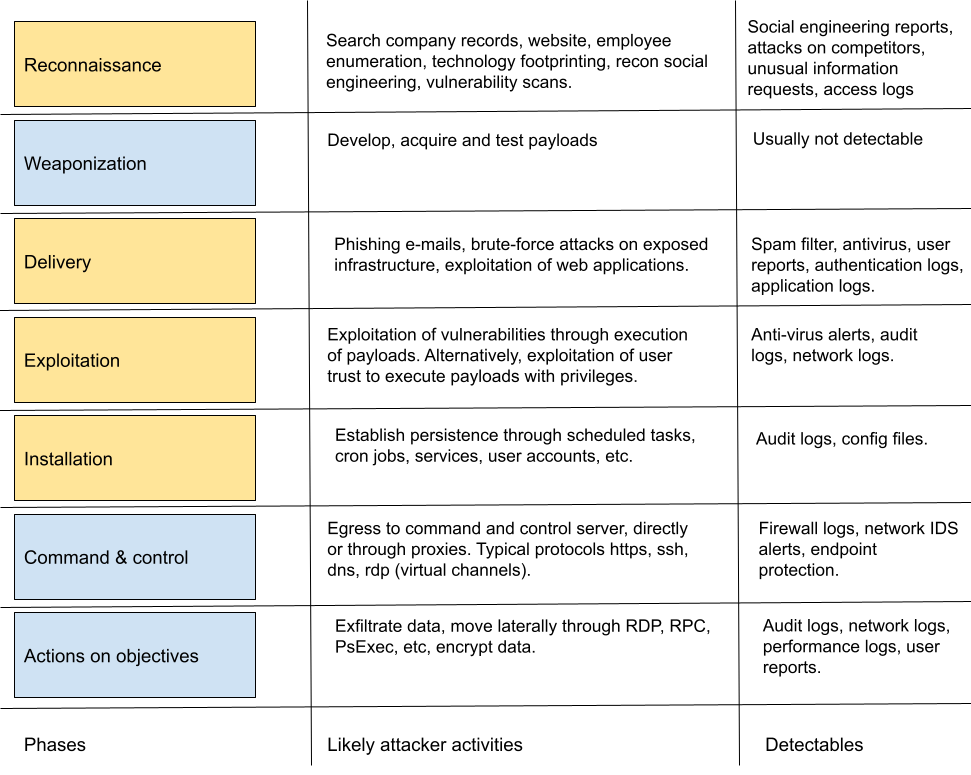
Here’s a summary of attack activities in different phases from the Lockheed-Martin kill-chain model. We will see that a lot of these opportunities for detection are not used out of the box in typical security tooling, and that an attacker can be relatively blunt in the choice of methods without creating alerts.
Phase
Attacker’s actions
Artifacts produced
Recon
Endpoint scanning, spidering, payload probing
Access logs Application logs
Weaponization
Plan reverse shell to use
Application logs
Delivery
Payload submitted through application’s injection point
Command line input
Exploitation
Command line input, create reverse shell
Network traffic Audit logs
Installation
Webshell injection Add SSH keys
Changed files on system
Command and control
Use access method established to perform actions
Network connections Audit logs
Actions on objective
Software installation Network reconnessaince Data exfiltration
Network connections Audit logs
Attack phases and expected artifacts generated
Deploying on an Azure Linux VM
We will deploy Vulnerable Norris on a Linux VM on Azure. Our detection strategy is to enable recommended security tooling in Azure, such as Microsoft Defender for Cloud, and to forward Syslog data to Sentinel. It is easy to think that an attack like the one above would light up with alerts relatively early, but as we will see this is not the case, at least not out of th box.
First we deploy a VM using the Azure CLI.
az vm create --name victimvm --group security-experiments --location norwayeast --image UbuntuLts --admin-username donkeyman --generate-ssh-keys
Now we have a standard VM with SSH access. By default it has port 22 open for SSH access. We will open another port for the application:
az vm open-port --name victimvm -g security-experiments --port 3000
We remote into the server with
ssh donkeyman@<ip-address-here>
Then we pull the Vulnerable Norris app in from Github and install it according to the README description. We need to install a few dependencies first:
OK, our server is up and running at <ip-address>:3000.
Turning on some security options
Let’s enable Defender for Cloud. According to the documentation, this should
Provide continuous assessment of security posture
Make recommendations for hardening – with a convenient “fix now” button
With the enhanced security features enabled, Defender for Cloud detects threats to your resources and workloads.
This sounds awesome – with the flick of a switch our Norris should be pretty secure, right?
Turns out there are more switches: you can turn on an EDR component called Defender for Server. That’s another switch to flick. It is not always clear when you have enabled enough features to be “safe enough”, and each new service enabled will add to the bill.
A very basic security measure that we have turned on, is to forward syslog to a SIEM. We are using Microsoft Sentinel for this. This allows us to create alerts based on log findings, as well as to search the logs through a simple interface, without logging on to the actual VM to do this. Alerts from Defender for Cloud are also set up to be forwarded to Sentinel, and an incident can be managed from both places and will synchronize.
The attack
The attacker comes from another planet – or at least another cloud. We are setting up a VM in Google Cloud. We will use this one to stage the attack by setting up a listener first to return a reverse shell from our VictimVM. Then we will generate SSH keys on the attacker’s server, and add the public key from here to VictimVM. Now we can log in over SSH from the GCP VM to VictimVM on Azure whenever we want. The key question is:
Does Defender for Cloud stop us?
Does it at least create an alert for us
We temporarily got the service up and running, exposing port 3000.
Vulnerable app running in an Azure VM.
Going to the app gives us a Chuck Norris fact from the Chuck Norris API. We have implemented a very poor implementation of this, calling the API using curl and using a system call from the web application, at the endpoint /dangerzone. This one has a parsing error that allows command injection.
Norris app with demo of remote command injection using “whoami”
The payload is
/dangerzone?category=fashion%26%26whoami
The output shows that we have command injection, and that the app is running as the user donkeyvictim. Now we can get a reverse shell to secure a bit more convenient access to the box. We have set up the VM to listen to port 3333, and use the following reverse shell payload generated by Online – Reverse Shell Generator (revshells.com):
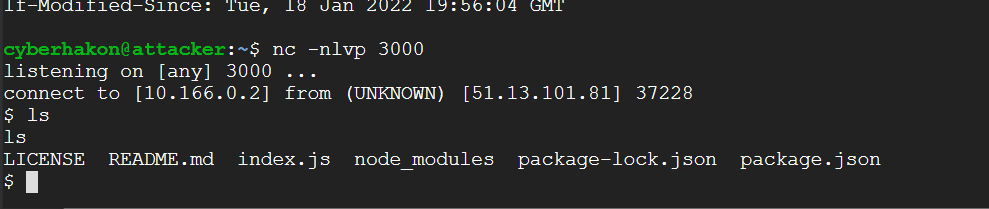
Simple reverse shell received using netcat listener
Running ls shows that we are indeed in a reverse shell, but it is very crude. We can upgrade the shell using a neat Python trick from this page:
python3 -c 'import pty;pty.spawn("/bin/bash")'
The blog I took this from has a lot of tweaks you can do to get full autocomplete etc through the netcat listener, but this will do for a bit nicer experience.
What we now do on the attacker VM is to generate an SSH keypair. We then copy the public key to the authorized_keys file for user donkeyvictim on the VictimVM using our reverse shell. We now have established a persistent access channel.
Upgraded shell: the attacker’s console on GCP cloud shell, connected to VictimVM on Azure over SSH.
We obviously see that this activity was not stopped by Microsoft’s Defender for Cloud. But did it at least create some alerts for us? It seems the answer to that is “nope”.
If we turn to Microsoft Sentinel, there are also no incidents or alerts related to this activity.
Checking the logs
Can we then see it in the logs? We know at least that authentication events over SSH will create auth log entries. Since we have set up the Syslog connector in Sentinel, we get the logs into a tool that makes searching easier. The following search will reveal which IP addresses have authenticated with a publickey, and the username it has authenticated with.
Syslog
| where Computer == "victimvm"
| where SyslogMessage contains "Accepted publickey for"
| extend ip = extract("([0-9]+.[0-9]+.[0-9]+.[0-9]+)",1,SyslogMessage)
| extend username = extract("publickey for ([a-zA-Z0-9@!]+)",1,SyslogMessage)
| project TimeGenerated, username, ip
The output from this search is as follows:
Showing the same user logging in with ssh from two different ip addresses.
Here we see that the same user is logging in from two different IP addresses. Enriching it with geolocation data could make the suspicious login easier to detect, as the 212… Is in Norway, and the 34… Is a Google owned ip address in Finland.
In other words: it is possible to detect unusual login acticity by creating queries in Sentinel. At least it is something.
How could we have detected the attack?
But what about all the things leading up to the SSH login? We should definitly be able to stop this at an earlier point.
The payload sent to the application
The network egress when the reverse shell is generated
The change of the ~/.ssh/authorized_keys file
Because the application does not log messages anywhere but stdout, they are not captured anywhere. It would have been good if the application logged issues to a standard location that could be forwarded.
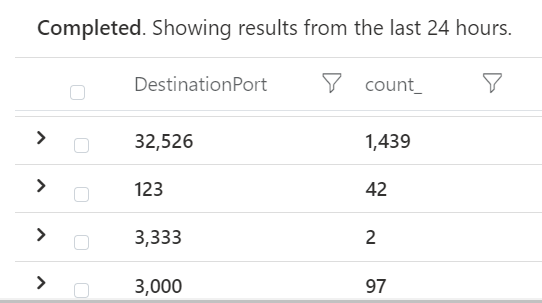
Detecting the attack when the reverse shell is generated is a good option. Here we can use the VMConnection data provided by the Defender for Cloud agent running on the VM.
VMConnection
| where Computer has "victimvm"
| where Direction == "outbound"
| summarize count() by DestinationPort
Here we look at which destination prots we see in egress traffic. Reverse shells will often use ports not requiring sudo rights, ie above 1000.
Count of outbound connections per destination port
We see we have outbound connections to port 3000. Looking into one of the log items we find some interesting information:
TimeGenerated [UTC]
2022-01-18T19:58:20.211Z
Computer
victimvm
Direction
outbound
ProcessName
python3
SourceIp
10.0.0.4
DestinationIp
34.88.132.129
DestinationPort
3000
Protocol
tcp
RemoteIp
34.88.132.129
RemoteLongitude
28.21
RemoteLatitude
61.03
RemoteCountry
Finland
We know that this is our reverse shell. We could then correlate the outbound connection to this IP address with later incoming SSH connection from this IP address. For relatively specific attack events we can in other words create detections. However, we don’t know in advance what persistence option the attacker would go for, or the port number used for the reverse shell.
A good idea would be to list the scenarios we would want to detect, and then build logging practices and correlations to help us create alerts for these incidents.
Can we throw more security at the VM to detect and stop attacks?
One thing Azure supports for VM’s if Defender for Cloud is enabled with “enhanced security” is “just-in-time access” for the VM. You need to pre-authorize access to open for inbound traffic to management ports through the network security group. The result of trying to connect with SSH after enabling it, is a timeout:
After enabling JIT access, our SSH connection times out without pre-approval.
We can now request access over SSH in Azure Portal by going to the VM’s overview page, and then selecting “connect”:
Pre-authorizing SSH access enables it for a defined period.
This will effectively stop an attacker’s persistence tactic but it will not take care of the remote command injection vulnerability.
For a web application we could also put a web application firewall in front of it to reduce the malicious payloads reaching the app. Even better is of course to only run code that has been developed with security in mind.
The key takeaways are:
Log forwarding is gold but you have to use it and set up your own alerts and correlations to make it help stop attacks
Enabling security solutions will help you but it will not take care of security for you. Setting up endpoint security won’t help you if the application code you are running is the problem.
Avoid exposing management ports directly on the internet if possible.
This weekend I decided to do a small experiment. Create two virtual machines in the cloud, one running Windows, and one running Linux. The Windows machine exposes RDP (port 3389) to the internet. The Linux machine exposes SSH (port 22). The Windows machines sees more than 10x the brute-force attempts of the Linux machine.
We capture logs, and watch the logon attempts. Here’s what I wanted to find out:
How many login attempts do we have in 24 hours?
What usernames are the bad guys trying with?
Where are the attacks coming from?
Is there a difference between the two virtual machines in terms of attack frequency?
The VM’s were set up in Azure, so it was easy to instrument them using Microsoft Sentinel. This makes it easy to query the logs and create some simple statistics.
Where are the bad bears coming from?
Let’s first have a look at the login attempts. Are all the hackers Russian bears, or are they coming from multiple places?
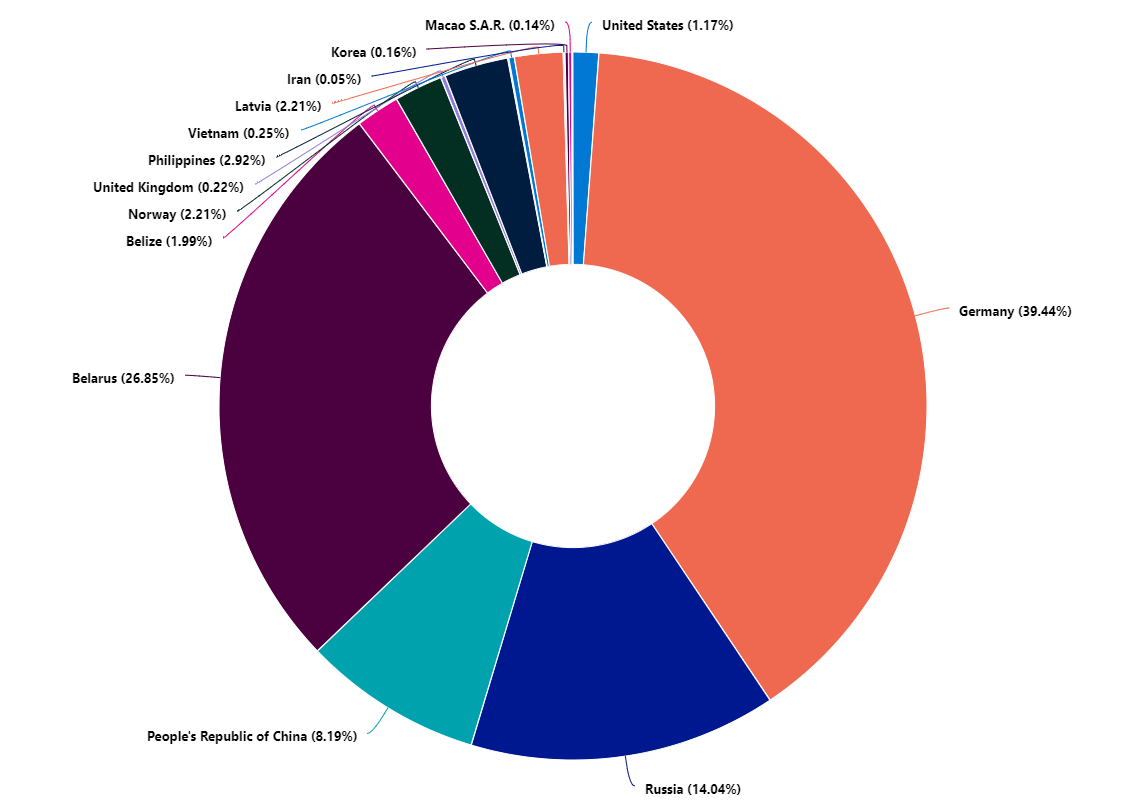
Windows
On Windows we observed more than 30.000 attempts over 24 hours. The distribution of attacks that the majority came from Germany, then Belarus, followed by Russia and China. We also see that there are some attempts from many countries, all around the globe.
Logon attempts on a Windows server over 24 hours
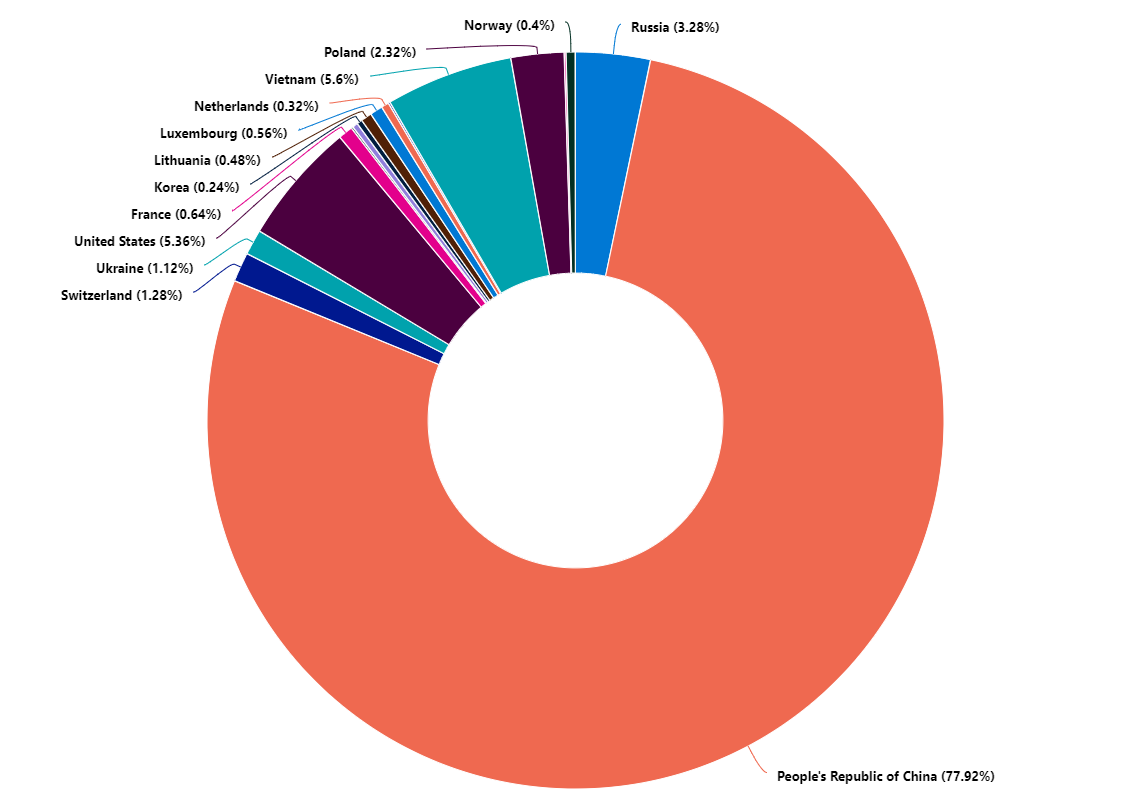
Linux
On Linux the situation is similar, although the Chinese bad guys are a lot more intense than the rest of them. We don’t see that massive amount of attacks from Germany on this VM. It is also less popular to attack the Linux VM: only 3000 attempts over 24 hours, about 10% of the number of login attempts observed on the Windows VM.
Logon attempts on a Linux server over 24 hours
What’s up with all those German hackers?
The German hackers are probably not German, or human hackers. These login attempts are coming from a number of IP addresses known to belong to a known botnet. That is; these are computers in Germany infected with a virus.
Usernames fancied by brute-force attackers
What are the usernames that attackers are trying to log in with?
Top 5 usernames on Linux:
Top 5 usernames on Windows:
We see that “admin” is a popular choice on both servers, which is perhaps not so surprising. On Linux the attackers seem to try a lot of typical service names, for example “ftp” as shown above. Here’s a collection of usernames seen in the logs:
zabbix
ftp
postgres
ansible
tomcat
git
dell
oracle1
redmine
samba
elasticsearch
apache
mysql
kafka
mongodb
sonar
Perhaps it is a good idea to avoid service names as account names, although the username itself is not a protection against unauthorized access.
There is a lot less of this in the Windows login attempts; here we primarily see variations of “administrator” and “user”.
Tips for avoiding brute-force attackers
The most obvious way to avoid brute-force attacks from the Internet, is clearly to not put your server on the Internet. There are many design patterns that allow you to avoid exposing RDP or SSH directly on the Internet. For example:
Only allow access to your server from the internal network, and set up a VPN solution with multi-factor authentication to get onto the local network remotely
Use a bastion host solution, where access to this host is strictly controlled
Use an access control solution that gives access through short-lived tokens, requiring multi-factor authentication for token access. Cloud providers have services of this type, such as just-in-time access on Azure or OS Login on GCP.
If you are using the Admin SDK on the server side, you have full access to everything by default. The Firestore security rules do not apply to the Admin SDK. One thing in particular we should be aware of is that the Firesbase admin SDK gives access to management plane functionality, making it possible to change security rules, for example. This is not apparent from the Firebase console or command line tools.
Running Firebase Cloud Functions using the Admin SDK with default permissions can quickly lead to a lot of firefighting. Better get those permissions under control!
In this blog post we dig into a Firebase project through the Google Cloud console and the gcloud command line tool, where we show how to improve the security of our capture-the-flag app by creating specific service accounts and role bindings for a cloud function. We also explore how to verify that a user is signed in using the Firebase Admin SDK.
A threat model for the flag checker
We have created a demo Firebase project with a simple web application at https://quizman-a9f1b.web.app/. This app has a simple CTF function, where a CTF challenge is presented, and players can verify if their identified flag is correct. The data exchange is primarily done using the JavaScript SDK, protected by security rules. For checking the flag, however, we are using a cloud function. If this cloud function has a vulnerability that allows an attacker to take control over it, that attacker could potentially overwrite the “correct flag”, or even change the security rules protecting the JavaScript SDK access.
Here’s a list of threats and potential consequences:
Vulnerability
Exploitation
Impact
RCE vulnerability in code
Attacker can take full control of the Firebase project environment through the admin SDK
Can read/write to private collection (cheat)Can create other resources (costs money)Can reconfigure security rules (data leaks or DoS)
Lack of brute-force protection
Attacker can try to guess flags by automating submission
User can cheatCosts money
Lack of authentication
An unauthenticated user can perform function calls
Costs money in spite of not being a real player of the CTF game
We need to make sure that attackers cannot exploit vulnerabilities to cheat in the program. We also want to protect against unavailability, and abuse that can drive up the cloud usage bill (after all this is a personal project). We will apply a defence-in-depth approach to our cloud function:
Execution of the function requires the caller to be authenticated. The purpose of this is to limit abuse, and to revoke access to users abusing the app.
The Firebase function shall only have read access to FIrestore, preferably only to the relevant collections. This will avoid the ability of an attacker with RCE to overwrite data, or to manage resources in the Firebase project.
For the following events we want to create logs and possibly alerts:
authenticated user verified token
unauthenticated user requested token verification
Requiring the user to be authenticated
First we need to make sure that the person requesting to verify a flag is authenticated. We can use a built-in method of the Firebase admin SDK to do this. This method checks that the ID token received is properly signed, and that it is not expired. The good thing about this approach is that it avoids making a call to the authentication backend.
But what if the token has been revoked? It is possible to check if a token is revoked using either security rules (recommended, cheap), or making an extra call to the authentication backend (expensive, not recommended). Since we are not actively revoking tokens in this app, unless a user changes his/her password, we will not bother with this functionality but if you need it, there is documentation how here: https://firebase.google.com/docs/auth/admin/manage-sessions#detect_id_token_revocation.
We need to update our “check flag workflow” from this:
send flag and challenge ID to cloud function
cloud function queries Firestore based on challenge ID and gets the “correct flag”
cloud function compares submitted flag with the correct flag, and returns {success: true/false} as appropriate
to this slightly more elaborate workflow:
send flag, challenge ID and user token to cloud function
cloud function verifies token ID
If invalid: return 403 (forbidden) // simplified to returning 200 with {success: false}
if valid:
cloud function queries Firestore based on challenge ID and gets the “correct flag”
cloud function compares submitted flag with the correct flag, and returns {success: true/false} as appropriate
The following code snippet shows how to perform the validation of the user’s token:
If the token is valid, we receive a decoded jwt back.
Restricting permissions using IAM roles
By default, a Firebase function initiated with the Firebase admin SDK has been assigned very powerful permissions. It gets automatically set up with a service account that is named as “firebase-adminsdk-random5chars@project-id.iam.gserviceaccount.com”. The service account itself does not have rights associated with it, but it has role bindings to roles that have permissions attached to it.
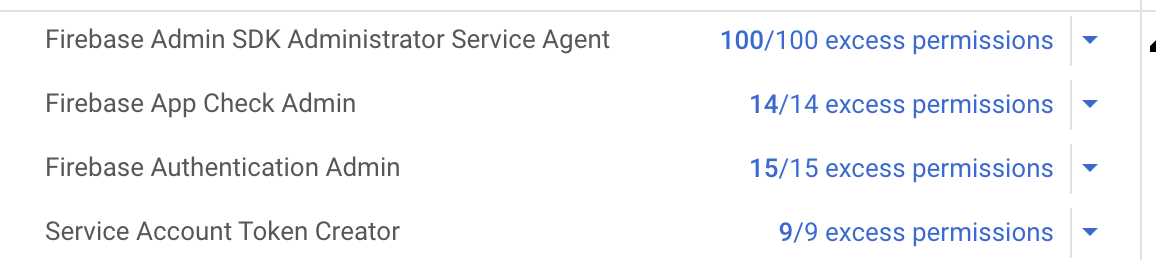
If you go into the Google Cloud Console, and navigate to “IAM” under your project, you can look up the roles assigned to a principal, such as your service account. For each role you automatically get an assessment of “excess permissions”; those are permissions available through the role bindings but that are not used in the project. Here’s the default configuration for the service account set up for the Admin SDK:
By default Firebase Cloud Functions run with excessive permissions!
Our Firebase cloud function does not need access to all those permissions. By creating roles that are fit for purpose we can limit the damage an attacker can do if the function is compromised. This is just the same principle in action as when your security awareness training tells you not to run your PC as admin for daily work.
Cloud resources have associated ready-made roles that one can bind a service account to. For Firestore objects the relevant IAM roles are listed here: https://cloud.google.com/firestore/docs/security/iam. We see that there is a viewer role that allows read access to all Firestore resources, called datastore.viewer. We will use this, but be aware it could read all Firestore data in the project, not only the intended objects. Still, we are protecting against deletion, overwriting data, and creation of new resources.
Note that it is possible to create more specific roles. We could create a role that only has permission to read from Firestore entities. We cannot in an IAM role describe exactly which Firestore collection to allow read operations from, but if we create the role flagchecker and assign it the permission datastore.entities.get and nothing else, it is as locked down as we can make it.
To implement this for our cloud function, we create a new service account. This can be done in the Console by going to IAM → Service Accounts → New Service Account. We create the account and assign it the role datastore.viewer.
Our new service account is called quizman-flag-checker.
Now we need to attach this service account to our Firebase function. It is not clear form the Firebase documentation how we can accomplish this, but opening the Google Cloud Console, or using the gcloud command line tool, we can attach our new service account with more restrictive permissions to the Firebase function.
To do this, we go into the Google Cloud console, choose the right project and Compute → Cloud functions. Select the right function, and then hit the “edit” button to change the function. Here you can choose the service account you want to attach to the function.
After changing the runtime service account, we need to deploy the function again. Now the service-to-service authentication is performed with a principal with more sensible permissions; attackers can no longer create their own resources or delete security rules.
Auditing the security configurations of a Firebase function using gcloud
Firebase is great for an easy set-up, but as we have seen it gives us too permissive roles by default. It can therefore be a good idea to audit the IAM roles used in your project.
Key questions to ask about the permissions of a cloud function are:
What is the service account this function is authenticating as?
What permissions do I have for this cloud function?
Do I have permissions that I do not need?
In addition to auditing the configuration, we want to audit changes to the configuration, in particular changes to service accounts, roles, and role bindings. This is easiest done using the log viewer tools in the Google Cloud console.
We’ll use the command line tool gcloud for the auditing, since this makes it possible to automate in scripts.
Service accounts and IAM roles for a Firebase function
Using the Google Cloud command line tool gcloud we can use the command
gcloud functions describe <functionName>
to get a lot of metadata about a function. To extract just the service account used you can pipe it into jq like this:
When we have the service account, we can next check which roles are bound to the account. This query is somewhat complex due to the nested data structure for role bindings on a project (for a good description of gcloud IAM queries, see fabianlee.org):
Running this gives us the following role (as expected): projects/quizman-a9f1b/roles/flagchecker.
Hence, we know this is the only role assigned to this service account. Now we finally need to list the permissions for this role. Here’s how we can do that:
cloud iam roles describe flagchecker --project=quizman-a9f1b --format="value(includedPermissions)”
The output (as expected) is a single permission: datastore.entities.get.
Do you like quizzes or capture the flag (CTF) exercises? Imagine we want to build a platform for creating a capture the flag exercise! We need the platform to present a challenge. When users solve the challenge, they find a “flag”, which can be a secret word or a random string. They should then be able to submit the flag in our CTF platform and check if it is correct or not.
Capture the flag can be fun: looking for a hidden flag whether physically or on a computer
To do this, we need a web server to host the CTF website, and we need a database to store challenges. We also need some functionality to check if we have found the right flag.
Firebase is a popular collection of serverless services from Google. It offers various easy to use solutions for quickly assembling applications for web or mobile, storing data, messaging, authentication, and so on. If you want to set up a basic web application with authentication and data storage without setting up backends, it is a good choice. Let’s create our CTF proof-of-concept on Firebase using Hosting + Firestore for data storage. Good for us, Google has created very readable documentation for how to add Firebase to web projects.
Firestore is a serverless NoSQL database solution that is part of Firebase. There are basically two ways of accessing the data in Firebase:
Directly from the frontend. The data is protected by Firestore security rules
Via an admin SDK meant for use on a server. By default the SDK has full access to everything in Firestore
We don’t want to use a server, so we’ll work with the JavaScript SDK for the frontend. Here are the user stories we want to create:
As an organizer I want to create a CTF challenge in the platform and store it in Firebase so other users can find it and solve the challenge
As a player I want to view a challenge so that
As a player I want to create a form to submit a flag to check that it is correct
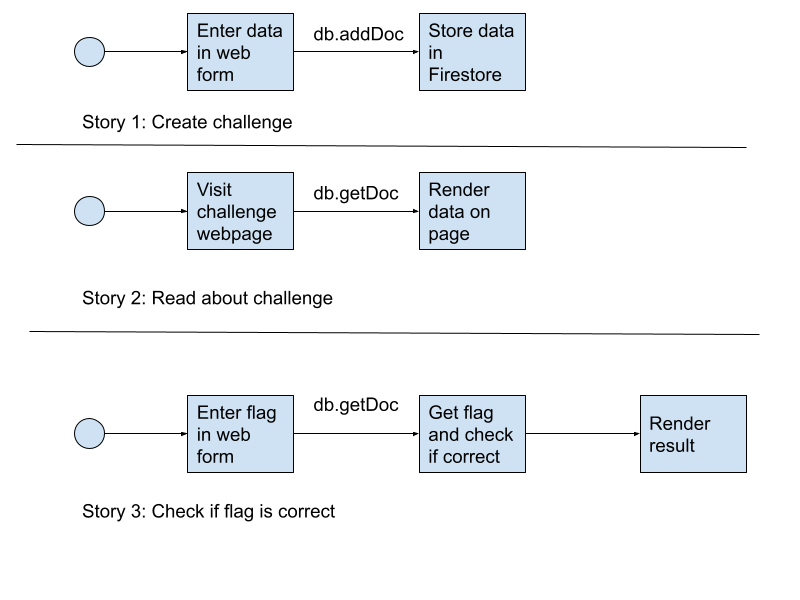
We want to avoid using a server, and we are simply using the JavaScript SDK. Diagrams for the user stories are shown below.
User stories for a simple CTF app example
What about security?
Let’s think about how attackers could abuse the functionalities we are trying to create.
Story 1: Create a challenge
For the first story, the primary concern is that nobody should be able to overwrite a challenge, including its flag.
Each challenge gets a unique ID. That part is taken care of by Firestore automatically, so an existing challenge will not be overwritten by coincidence. But the ID is exposed in the frontend, and so is the project metadata. Could an attacker modify an existing record, for example its flag, by sending a “PUT” request to the Firestore REST API?
Let’s say we have decided a user must be authenticated to create a challenge, and implemented this by the following Firebase security rule:
match /challenges/{challenges} {
allow read, write: if request.auth != null;
}
Hacking the challenge: overwriting data
This says nothing about overwriting existing data. It also has no restriction on what data the logged in user has access to – you can both read and write to challenges, as long as you are authenticated. Here’s how we can overwrite data in Firestore using set.
This challenge has the title “Fog” and description “on the water”. We want to hack this as another user directly in the Chrome dev tools to change the title to “Smoke”. Let’s first register a new user, cyberhakon+dummy@gmail.com and log in.
If we open devtools directly, we cannot find Firebase or similar objects in the console. That is because the implementation uses SDV v.9 with browser modules, making the JavaScript objects contained within the module. We therefore need to import the necessary modules ourselves. We’ll first open “view source” and copy the Firebase metadata.
We’ll simply paste this into the console while on our target challenge page. Next we need to import Firebase to interact with the data using the SDK. We could use SDK v.8 that is namespaced, but we can stick to v.9 using dynamic imports (works in Chrome although not yet a standard):
import('https://www.gstatic.com/firebasejs/9.6.1/firebase-app.js').then(m => firebase = m)
and
import('https://www.gstatic.com/firebasejs/9.6.1/firebase-firestore.js').then(m => firestore = m)
Now firestore and firebase are available in the console.
First, we initalize the app with var app = firebase.initializeApp(firebaseConfig), and the database with var db = firestore.getFirestore(). Next we pull information about the challenge we are looking at:
var mydoc = firestore.doc(db, "challenges", "wnhnbjrFFV0O5Bp93mUV");
var docdata = await firestore.getDoc(mydoc);
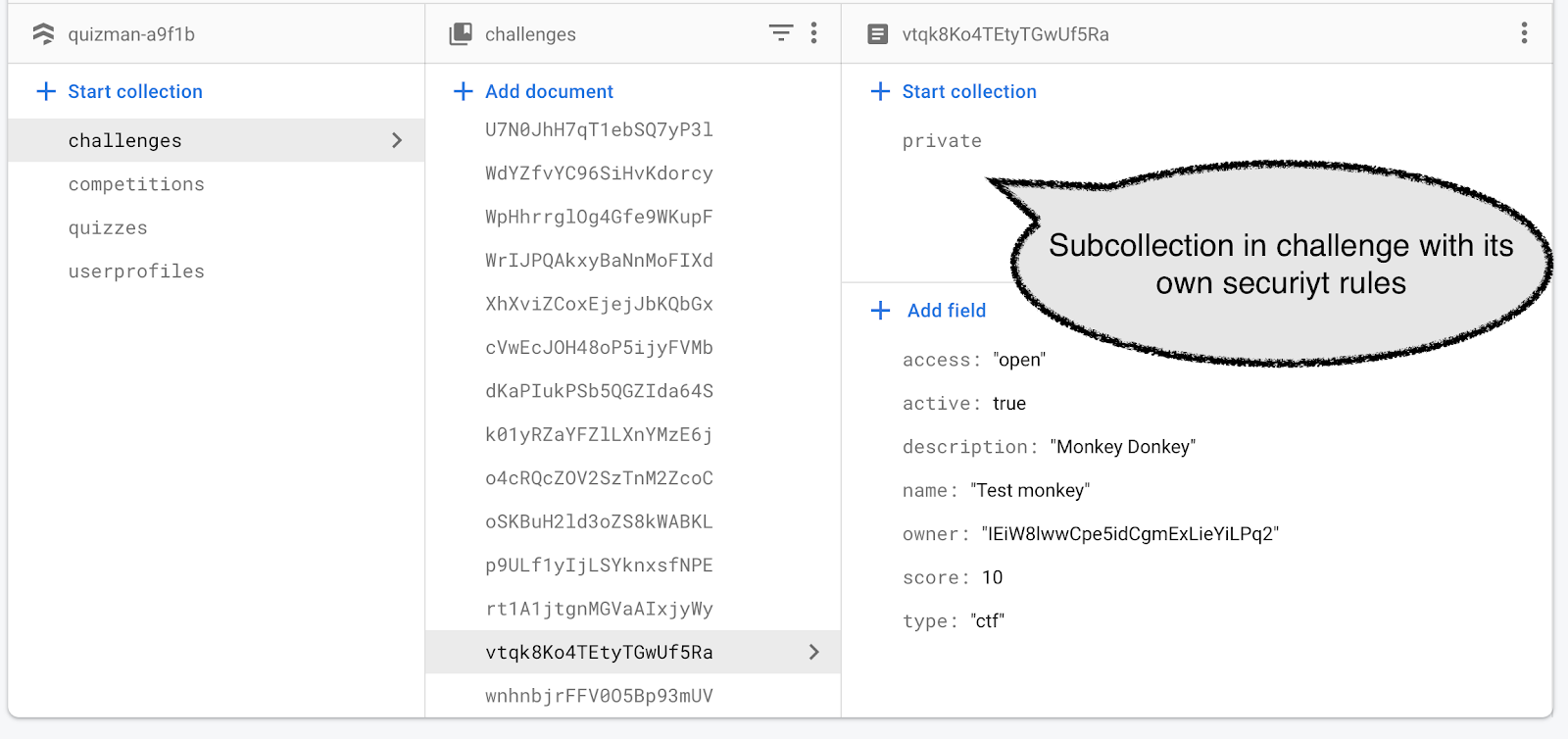
This works well. Here’s the data returned:
access: “open”
active: true
description: “on the water”
name: “Fog”
owner: “IEiW8lwwCpe5idCgmExLieYiLPq2”
score: 5
type: “ctf”
That is also as intended, as we want all users to be able to read about the challenges. But we can probably use setDoc as well as getDoc, right? Let’s try to hack the title back to “Smoke” instead of “Fog”. We use the following command in the console:
var output = await firestore.setDoc(mydoc, {name: “Smoke”},{merge: true})
Note the option “merge: true”. Without this, setDoc would overwrite the entire document. Refreshing the page now yields the intended result for the hacker!
Improving the security rules
Obviously this is not good security for a very serious capture-the-flag app. Let’s fix it with better security rules! Our current rules allows anyone who is authenticated to read data, but also to write data. Write here is shorthand for create, update, and delete! That means that anyone who is logged in can also delete a challenge. Let’s make sure that only owner can modify documents. We keep the rule for reading to any logged in user, but change the rule for writing to the following:
Safe rule against malicious overwrite:
allow write: if request.auth != null && request.auth.uid == resource.data.owner;
This means that authenticated users UID must match the “owner” field in the challenge.
Using the following security rules will allow anyone to create, update and delete data because the field “author_id” can be edited in the request directly. The comparison should be done as shown above, against the existing data for update using resource.data.<field_name>.
service cloud.firestore {
match /databases/{database}/documents {
// Allow only authenticated content owners access
match /some_collection/{document} {
allow read, write: if request.auth != null && request.auth.uid == request.resource.data.author_uid
}
}
}
// Example from link quoted above
There is, however, a problem with the rule marked “SAFE AGAINST MALICIOUS UPDATES” too; it will deny creation of new challenges! We thus need to split the write condition into two new rules, one for create (for any authenticated user), and another one for update and delete operations.
The final rules are thus:
allow read, create: if request.auth != null;
allow update, delete: if request.auth != null && request.auth.uid == resource.data.owner;
Story 2: Read the data for a challenge
When reading data, the primary concern is to avoid that someone gets access to the flag, as that would make it possible for them to cheat in the challenge. Security rules apply to documents, not to fields in a document. This means that we cannot store a “secret” inside a document; access is an all or nothing decision. However, we can create a subcollection within a document, and apply separate rules to that subdocument. We have thus created a data structure like this:
Security rules are hierarchical, so we need to apply rules to /challenges/{challenge}/private/{document}/ to control access to “private”. Here we want the rules to allow only “create” a document under “private” but not to change it, and also not to read it. The purpose of blocking reading of the “private” documents is to avoid cheating.
But how can we then compare a player’s suggested flag with the stored one? We can’t in the frontend, and that is the point. We don’t want to expose the data in on the client side.
Story 3: Serverless functions to the rescue
Because we don’t want to expose the flag from the private subcollection in the frontend, we need a different pattern here. We will use Firebase cloud functions to do that. This is similar to AWS’ lambda functions, just running on GCP/Firebase instead. For our Firestore security, the important aspect is that a cloud function running in the same Firebase project has full access to everything in Firestore, and the security rules do not apply to the admin SDK used in functions. By default a cloud function is assigned an IAM role that gives it this access level. For improved security one can change the roles so that you allow only the access needed for each cloud function (here: read data from Firestore). We haven’t done that here, but this would allow us to improve security even further.
Serverless security engineering recap
Applications don’t magically secure themselves in the cloud, or by using serverless. With serverless computing, we are leaving all the infrastructure security to the cloud provider, but we still need to take care of our workload security.
In this post we looked at access control for the database part of a simple serverless web application. The authorization is implemented using security rules. These rules can be made very detailed, but it is important to test them thoroughly. Misconfigured security rules can suddenly allow an attacker to bypass your intended control.
Using Firebase, it is not obvious from the Firebase Console how to set up good application security monitoring and logging. Of course, that is equally important when using serverless as other types of infrastructure, both for detecting attacks, and for forensics after a successful breach. You can set up monitoring Google Cloud Monitoring for Firebase resources, including alerts for events you want to react to.
As always: basic security principles still hold with serverless computing!
Without IT systems, modern life does not exist. Whether we are turning on our dishwasher, ordering food, working, watching a movie or even just turning the lights on, we are using computers and networked services. The connection of everything in networks brings a lot of benefits – but can also make the infrastructure of modern societies very fragile.
Cyber attacks can make society stop. That’s why we need to stop the attackers early in the kill-chain!
When society moved online, so did crime. We hear a lot about nation state attacks, industrial espionage and cyber warfare, but for most of us, the biggest threat is from criminals trying to make money through theft, extortion and fraud. The difference from earlier times is that we are not only exposed to “neighborhood crime”; through the Internet we are exposed to criminal activities executed by criminals anywhere on the planet.
We see in media reports every week that organizations are attacked. They cause serious disruptions, and the cost can be very high. Over Christmas we had several attacks happening in Norway that had real consequences for many people:
Nortura, a cooperative owned by Norwegian farmers that processes meat and eggs, was hit by a cyber attack that made them take many systems offline. Farmers could not deliver animals for slaughtering, and distribution of meat products to stores was halted. This is still the situation on 2 January 2022, and the attack was made public on 21 December 2021.
Amedia, a media group publishing mostly local newspapers, was hit with ransomware. The next 3 days following the attack on the 28th of December, most of Amedia’s print publications did not come out. They managed to publish some print publications through collaboration with other media houses.
Nordland fylkeskommune (a “fylkeskomune” is a regional administrative level between municapalities and the central government in Norway) and was hit with an attack on 23 December 2021. Several computer systems used by the educational sector have been taken offline, according to media reports.
What is clear is that there is a serious and very real threat to companies from cyber attacks – affecting not only the companies directly, but entire supply chains. The three attacks mentioned above all happened within two weeks. They caused disruption of people’s work, education and media consumption. When society is this dependent on IT systems, attacks like these have real consequences, not only financially, but to quality of life.
This blog post is about how we can improve our chances of detecting attacks before data is exfiltrated, before data is encrypted, before supply chains collapse and consumers get angry. We are not discussing what actions to take when you detect the attack, but we will assume you already have an incident response plan in place.
How an attack works and what you can detect
Let’s first look at a common model for cyber attacks that fit quite well with how ransomware operators execute; the cyber kill-chain. An attacker has to go through certain phases to succeed with an attack. The kill-chain model uses 7 phases. A real attack will jump a bit back and forth throughout the kill-chain but for discussing what happens during the attack, it is a useful mental model. In the below table, the phases marked in yellow will often produce detectable artefacts that can trigger incident response activities. The blue phases of weaponization (usually not detectable) and command & control, actions on objectives (too late for early response) are not discussed further.
Defensive thinking using a multi-phase attack model should take into account that the earlier you can detect an attack, the more likely you are to avoid the most negative consequences. At the same time, the earlier phases give you detections with more uncertainty, so you do risk initiating response activities that can hurt performance based on false positives.
Detecting reconnaissance
Before the attack happens, the attacker will identify the victim. For some attacks this is completely automated but serious ransomware attacks are typically human directed and will involve some human decision making. In any case, the attacker will need to know some things about your company to attack it.
What domain names and URL’s exist?
What technologies are used, preferably with version numbers so that we can identify potential vulnerabilities to exploit?
Who are the people working there, what access levels do they have and what are their email addresses? This can be used for social engineering attacks, e.g. delivering malicious payloads over email.
These activities are often difficult to detect. Port scans and vulnerability scans of internet exposed infrastructure are likely to drown in a high number of automated scans. Most of these are happening all the time and not worth spending time reacting to. However, if you see unusual payloads attempted, more thorough scans, or very targeted scans on specific systems, this can be a signal that an attacker is footprinting a target.
Other information useful to assess the risk of an imminent attack would be news about attacks on other companies in the same business sector, or in the same value chain. Also attacks on companies using similar technical set-ups (software solutions, infrastructure providers, etc) could be an early warning signal. In this case, it would be useful to prepare a list of “indicators of compromise” based on those news reports to use for threat hunting, or simply creating new alerts in monitoring systems.
Another common indicator that footprinting is taking place, is an increase in the number of social engineering attempts to elicit information. This can be over phone, email, privacy requests, responses to job ads, or even in person. If such requests seem unusual it would be useful for security if people would report it so that trends or changes in frequency can be detected.
Detecting delivery of malicious payloads
If you can detect that a malicious payload is being delivered you are in a good position to stop the attack early enough to avoid large scale damage. The obvious detections would include spam filters, antivirus alerts and user reports. The most common initial intrusion attack vectors include the following:
Phishing emails (by far the most common)
Brute-force attacks on exposed systems with weak authentication systems
Exploitation of vulnerable systems exposed to the Internet
Phishing is by far the most common attack vector. If you can reliably detect and stop phishing attacks, you are reducing your risk level significantly. Phishing attacks usually take one of the following forms:
Phishing for credentials. This can be username/password based single-factor authentication, but also systems protected by MFA can be attacked with easy to use phishing kits.
Delivery of attachments with malicious macros, typically Microsoft Office.
Other types of attachments with executable code, that the user is instructed to execute in some way
Phishing attacks create a number of artefacts. The first is the spam filter and endpoint protection; the attacker may need several attempts to get the payload past first-line of defences. If there is an increase in phishing detections from automated systems, be prepared for other attacks to slip past the filters.
The next reliable detection is a well-trained workforce. If people are trained to report social engineering attempts and there is an easy way to do this, user reports can be a very good indicator of attacks.
For brute-force attacks, the priority should be to avoid exposing vulnerable systems. In addition, creating alerts on brute-force type attacks on all exposed interfaces would be a good idea. It is then especially important to create alerts to successful attempts.
For web applications, both application logs and WEF logs can be useful. The main problem is again to recognize the attacks you need to worry about in all the noise from automated scans.
Detecting exploitation of vulnerabilities
Attackers are very interested in vulnerabilities that give them access to “arbitrary code execution”, as well as “escalation of privileges”. Such vulnerabilities will allow the attacker to install malware and other tools on the computer targeted, and take full control over it. The primary security control to avoid this, is good asset management and patch management. Most attacks are exploiting vulnerabilities where a patch exists. This works because many organizations are quite late at patching systems.
A primary defense against exploitation of known vulnerabilities is endpoint protection systems, including anti-virus. Payloads that exploit the vulnerabilities are recognized by security companies and signatures are pushed to antivirus systems. Such detections should thus be treated as serious threat detections. It is all well and good that Server A was running antivirus that stopped the attack, but what if virus definitions were out of date on Server B?
Another important detection source here would be the system’s audit logs. Did the exploitation create any unusual processes? Did it create files? Did it change permissions on a folder? Log events like this should be forwarded to a tamper proof location using a suitable log forwarding solution.
To detect exploitation based on log collection, you will be most successful if you are focusing on known vulnerabilities where you can establish patterns that will be recognizable. For example, if you know you have vulnerable systems that cannot be patched for some reason, establishing specific detections for exploitation can be very very valuable. For tips on log forwarding for intrusion detection in Windows, Microsoft has issued specific policy recommendations here.
Detecting installation (persistence)
Detecting installation for persistence is usually quite easy using native audit logs. Whenever a new service is created, a scheduled task is created, or a cron job, an audit log entry should be made. Make sure this is configured across all assets. Other automated execution patterns should also be audited, for example autorun keys in the Windows registry, or programs set to start automatically when a user logs in.
Another important aspect is to check for new user accounts on the system. Account creation should thus also be logged.
On web servers, installation of web shells should be detected. Web shells can be hard to detect. Because of this, it is a good idea to monitor file integrity of the files on the server, so that a new or changed file would be detected. This can be done using endpoint protection systems.
How can we use these logs to stop attackers?
Detecting attackers will not help you unless you take action. You need to have an incident response plan with relevant playbooks for handling detections. This post is already long enough, but just like the attack, you can look at the incident response plan as a multi-phase activity. The plan should cover:
Preparations (such as setting up logs and making responsibilities clear)
Detection (how to detect)
Analysis and triage (how to classify detections into incidents, and to trigger a formal response, securing forensic evidence)
Containment (stop the spread, limit the blast radius)
Eradication (remove the infection)
Recovery (recover the systems, test the recovery)
Lessons learned (how to improve response capability for the next attack, who should we share it with)
You want to know how to deal with the data you have collected to decide whether this is a problem or not, and what to do next. Depending on the access you have on endpoints and whether production disturbances during incident response are acceptable, you can automate part of the response.
The most important takeaway is:
Set up enough sensors to detect attacks early. Plan what to do when attacks are detected, and document it. Perform training exercises on simulated attacks, even if it is only tabletop exercises. This will put you in a much better position to avoid disaster when the bad guys attack!