Cybersecurity requires everyone to contribute but that is hard to achieve. In this post we look at how security managers can think like marketers to engage the management team, create strategic alignment that makes sense to others, create alliances and mutual support with other business functions. To achieve great security results we need to value and build strong internal relationships.
A common problem
Do you run a cybersecurity program but it feels like you are the only one who cares about it? Than you are unfortunately in a tough position, and your probability of success will be very low. To succeed with securing an organization’s critical processes, everyone must contribute. In order for that to happen, everybody must care.
Why don’t people care about cybersecurity? People are generally busy, and there are a million good causes seeking attention. For someone tasked with cybersecurity as their primary area of concern will naturally see this as one of the most important topics, but in gaining traction among the rest of the staff you are competing with climate change, profitability, growth, talent development, innovation projects, any many more things. To get people on your side, you will need to make it important for them; as a cybersecurity manager you will need to engage in internal marketing! In this blog post I will try to explore reasons for not engaging in cybersecurity work for different employee categories, and suggest steps that can be taken to change attitudes.

Management is not interested in security
Whether you are a CISO not being invited to the C-Suite meetings where decisions are made, or an IT security responsible in the IT department, being left out of decisions and with lots of responsibility but few resources is unfortunately a common situation. In companies where this is the case, one or more of the following attitudes are common in the management team:
- Cyber incidents won’t happen if we use well-known IT brands
- Cybersecurity does not contribute to the company’s mission, therefore we also don’t need to spend time on it
- Cybersecurity is invisible, therefore there is nothing I can do about it
- It won’t disrupt us, we have talented people in the organization who can handle any situation
- Cybersecurity is only a compliance issue, if we do the minimum necessary to pass the audit we will be OK
When this is the case, you have a tough marketing job to do. Jumping to talking about solutions and investment needs will probably not do much good here.
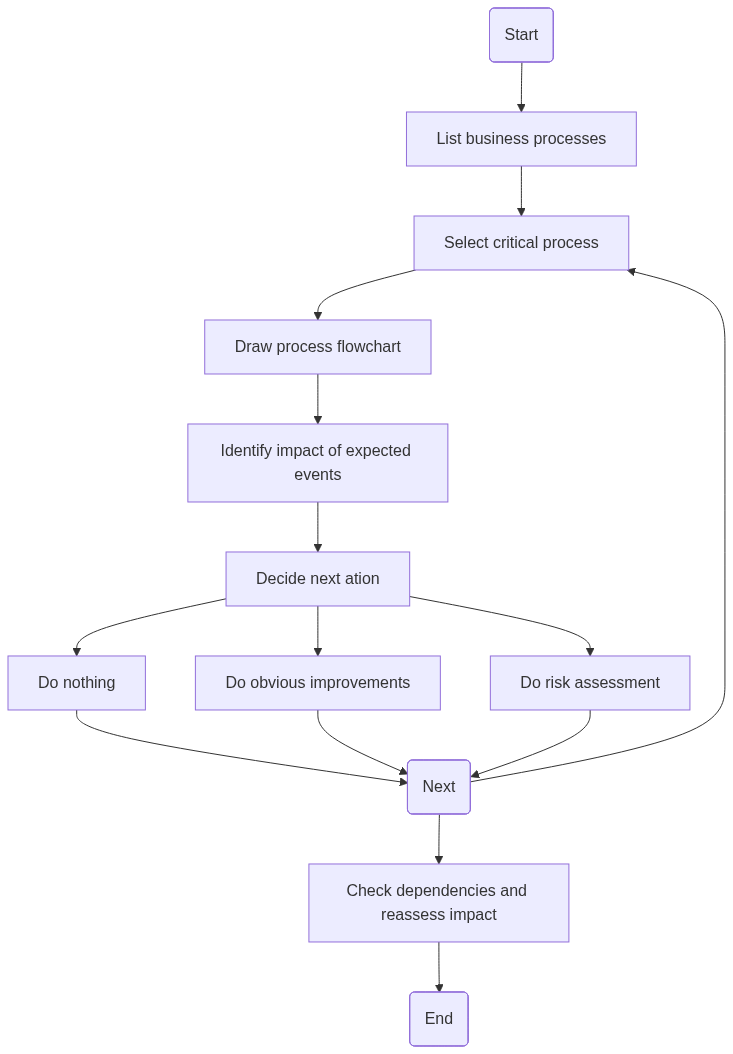
Homework: align security objectives with the company’s strategy
Before you can convince anyone else, you will need to know how security supports the strategy. Where is the company heading? What are the overall goals? How does digital fit into this? If you can’t answer this, it will be hard to talk to other management functions about priorities and what matters.
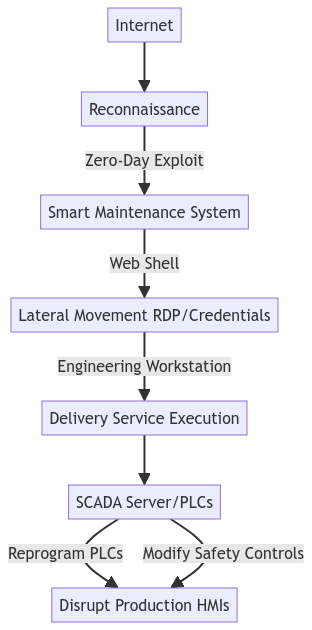
To get ahead with this work, a business impact assessment (BIA) is a very good tool. In a business impact assessment you will identify how disruptive events will impact your most important business processes, and also what to do about it. For example, if your company is betting on high growth through partnerships with retailers, investigate the impact of digital events to those partnerships. For how to do a digitally BIA, see this post: What is the true cost of a cyber attack?
Find allies and ambassadors in the management team
Not everybody cares equally about each topic. Some members of the management team you are trying to influence will be more receptive to your message. Getting one or two well-respected leaders on your side to help amplify your messaging can help immensely getting the message across. To recruit supporters, prioritize being helpful, spending time with them, and helping them get ahead with their own work. Here are some things you can do:
- When they communicate about something they care about, comment on it and make your support visible to them. Mention how cybersecurity is either helped by their initiative or how cybersecurity can help their initiative
- Ask them for advice on things you are working on, in the context they are working in.
- Provide them with easy to use talking points that they can bring up to support cybersecurity in rooms where you are not present. Avoid jargon, make it interesting and easy to talk about.
- Invite them for a coffee break, a walk, or a lunch. Build that relationship.
Engage in visual storytelling
Set up an internal marketing campaign. This can be monthly newsletters, short internal videos, or in-person meetings. Keep the storytelling short, jargon-free and to the point. Use structure and visuals to support your stories – and try to get a single point across each time instead of bombarding people with too much information to handle. Make sure the story fits the audience in terms of appeal, language, and ability to use the information for something.
Contrast for example the way bleepingcomputer.com (a tech website) describes the Crowdstrike faulty update last week that crashed millions of computers and disrupted many businesses globally, with how the same events are portrayed by general news media (for example CNN):


Bleepingcomputer: technical details, jargon, workarounds for IT people.
CNN: no jargon, explaining what Crowdstrike is, focus on impact, comments about risks for IT consolidation.
Be more like CNN than Bleepingcomputer when talking to non-experts, and put it into your organization’s context. For example, the Crowdstrike event, which people are likely to have read about in general news (more like CNN than Bleepingcomputer), could be used to increase attention to software supply-chain security.
Make benefits from security investments clear
Nobody is really interested in looking at security dashboards, but having a few metrics to show how security efforts are actually supporting the business and paying off is a good idea.
- Connect security posture to business impact and risk. Showcase how investments improve posture and reduce risk. Make it simple.
- Use metrics that capture the dynamics of people, processes and technology. Make it clear that success depends on the organization, not only buying technology from well-known brands.
- Distribute the results at the right time, and with relevant context.
- Suggest a regular reporting cycle to top management. Align reporting with regulatory compliance and corporate governance processes so it doesn’t show up as “a new cybersecurity report”, but as an integrated part of management reporting.
It is going to take time. Be patient, and prioritize getting people on board and building relationships before you add too many facts. Be consistent and to the point in messaging, and make yourself available for follow-ups. Make progress by making call-to-actions easy to agree to.
Other functional managers competing for attention are sabotaging cyber initiatives to further their own cause
You are living in internal competition with many other good causes, such as business growth, innovation, diversity initiatives, and efficiency boosting IT projects. People who own those processes may see cybersecurity as something causing friction for their own initiatives, as well as something that competes for attention from the management team. If internal functional managers are fighting each other, it is certainly not good for the company.

To avoid destructive conflict, help other functional managers succeed. Look for ways improvements in security can strengthen the goals of other functions. For example, a growth initiative depending a lot on digital technologies, will also be more vulnerable to disruption from cyber attacks. Engaging with the manager of the growth initiative on making it more robust, less vulnerable is likely to bring you new friends and allies, as well as actually contributing to improved security for the organization. This can also be a powerful story to tell, together, to the management team.
A primary concern for process owners is often friction caused by security controls. If your security controls are making it harder for others to succeed, they won’t support security. There are some important steps to avoiding this situation:
- Understand the impact of security controls on the business process
- Build understanding for why we need barriers against unwanted events, such as hacking
- Prioritize balance between performance and security when a trade-off is necessary. Try to find good, low-friction controls.
- Make sure the “why security is important here” is understood by everyone who works with the process
This is definitely not something you can win without good relationships with people. You need to the process owner on your side. Building good internal relationships is a critical activity to achieve good security. Hence, important tools for security improvement include:
- Coffee breaks
- Situational awareness
- Productivity vs. security trade-offs
You will probably benefit from approaching process owners in a similar way to senior managers, but perhaps with a more hands-on approach focusing on the particular process, initiative or function.
Dealing with the internal adversary
If you have other functional managers trying to compete with your for resources, and downplaying the importance of security, you need to take action. The opposition may be open, or it may be more covert. Typically sabotage will consist of a combination of some direct opposition, some microaggressions, and some your area when you are not around. If you suspect that you are meeting such opposition, make sure you understand the situation correctly before you take action against it.
The first step is thus to have a respectful but honest conversation with the person who sees you as their opponent. Try to find out what their actual goals are, if you have understood things correctly instead of escalating it to a more difficult situation. If you can find some common ground and agree to collaborate moving forward you may be able to defuse the situation already here.

If you cannot resolve the situation yourselves, try to agree to bring in someone else to help you sort things out. This can be your managers, or a trusted third party to mediate. Make sure you can agree to a path forward and focus on that.
If you see micro-agressions, general bad behavior meant to make you less influental, or outright bullying, you should take rapid action. If such behaviors are allowed to manifest, they can not only jeopordize your health and wellbeing, but can do so for others too, and will certainly not contribute to good results. Constructive conflict is good, bullying is not. This article from HBR explains the topic well, including strategies to stop the bad behavior: https://hbr.org/2022/11/how-bullying-manifests-at-work-and-how-to-stop-it. Dealing with bullying will require hard conversations and involving management early. The organization should work to put structures in place that don’t support such behaviors, as well as routines for handling transgressions when they move from acceptable conflict to unhealthy conflict.
Before jumping to the final thoughts, consider subscribing to the blog to avoid missing the next post!
Getting the organization on board with security
It is clear that relationships matter, also for security. It is also important to make the benefits of security investments visible, and ensure that a common situational awareness can be maintained, in order for everyone to pull in the same direction. When done right, there is not conflict between the goals of different functional areas, and the goals of security; you are contributing to the same strategic vision for your organization.
To succeed you need backing from top management. This may not come naturally, or for free. Think like a marketer and build demand for security in your organization. Be a security sales person and build relationships with key decision makers. Make sure you have allies in rooms where you are not present. This is easier said than done, and requires continued effort.
Underpinning all of this is situational awareness. Your job is really to create situational awareness to allow integrating security into corporate governance, business process design and daily operations. And to allow that to happen, you need to win over hearts and minds of your colleagues. Before people understand “why” security matters they won’t care about “how” security is achieved. To paraphrase Simon Sinek: start with the why.