Let’s set up a server to run Vulnerable Norris. An attacker discovers that the web application has a remote command injection vulnerability, and exploits it to gain a reverse shell. The attackers copy their own SSH public keys onto the device, and uses it as a foothold in the network. How can we detect and stop this from happening, even if we don’t know that the application itself has a vulnerability?
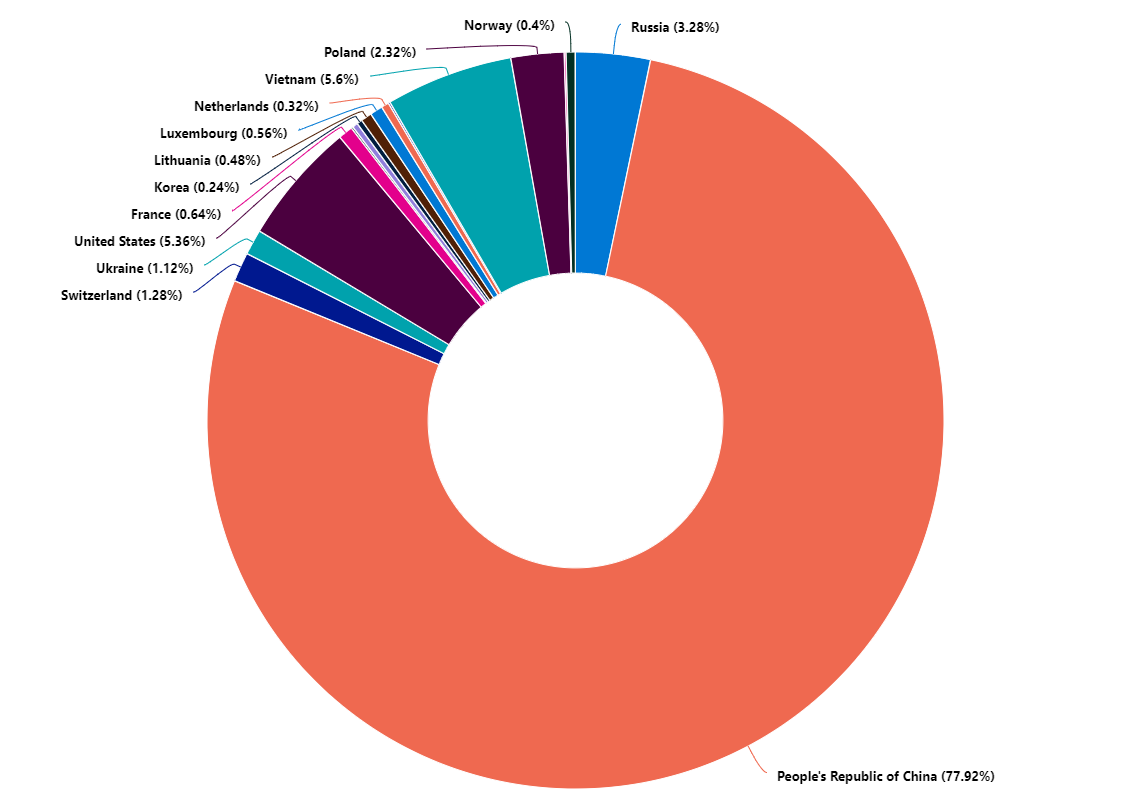
Here’s a summary of attack activities in different phases from the Lockheed-Martin kill-chain model. We will see that a lot of these opportunities for detection are not used out of the box in typical security tooling, and that an attacker can be relatively blunt in the choice of methods without creating alerts.
Phase
Attacker’s actions
Artifacts produced
Recon
Endpoint scanning, spidering, payload probing
Access logs Application logs
Weaponization
Plan reverse shell to use
Application logs
Delivery
Payload submitted through application’s injection point
Command line input
Exploitation
Command line input, create reverse shell
Network traffic Audit logs
Installation
Webshell injection Add SSH keys
Changed files on system
Command and control
Use access method established to perform actions
Network connections Audit logs
Actions on objective
Software installation Network reconnessaince Data exfiltration
Network connections Audit logs
Attack phases and expected artifacts generated
Deploying on an Azure Linux VM
We will deploy Vulnerable Norris on a Linux VM on Azure. Our detection strategy is to enable recommended security tooling in Azure, such as Microsoft Defender for Cloud, and to forward Syslog data to Sentinel. It is easy to think that an attack like the one above would light up with alerts relatively early, but as we will see this is not the case, at least not out of th box.
First we deploy a VM using the Azure CLI.
az vm create --name victimvm --group security-experiments --location norwayeast --image UbuntuLts --admin-username donkeyman --generate-ssh-keys
Now we have a standard VM with SSH access. By default it has port 22 open for SSH access. We will open another port for the application:
az vm open-port --name victimvm -g security-experiments --port 3000
We remote into the server with
ssh donkeyman@<ip-address-here>
Then we pull the Vulnerable Norris app in from Github and install it according to the README description. We need to install a few dependencies first:
OK, our server is up and running at <ip-address>:3000.
Turning on some security options
Let’s enable Defender for Cloud. According to the documentation, this should
Provide continuous assessment of security posture
Make recommendations for hardening – with a convenient “fix now” button
With the enhanced security features enabled, Defender for Cloud detects threats to your resources and workloads.
This sounds awesome – with the flick of a switch our Norris should be pretty secure, right?
Turns out there are more switches: you can turn on an EDR component called Defender for Server. That’s another switch to flick. It is not always clear when you have enabled enough features to be “safe enough”, and each new service enabled will add to the bill.
A very basic security measure that we have turned on, is to forward syslog to a SIEM. We are using Microsoft Sentinel for this. This allows us to create alerts based on log findings, as well as to search the logs through a simple interface, without logging on to the actual VM to do this. Alerts from Defender for Cloud are also set up to be forwarded to Sentinel, and an incident can be managed from both places and will synchronize.
The attack
The attacker comes from another planet – or at least another cloud. We are setting up a VM in Google Cloud. We will use this one to stage the attack by setting up a listener first to return a reverse shell from our VictimVM. Then we will generate SSH keys on the attacker’s server, and add the public key from here to VictimVM. Now we can log in over SSH from the GCP VM to VictimVM on Azure whenever we want. The key question is:
Does Defender for Cloud stop us?
Does it at least create an alert for us
We temporarily got the service up and running, exposing port 3000.
Vulnerable app running in an Azure VM.
Going to the app gives us a Chuck Norris fact from the Chuck Norris API. We have implemented a very poor implementation of this, calling the API using curl and using a system call from the web application, at the endpoint /dangerzone. This one has a parsing error that allows command injection.
Norris app with demo of remote command injection using “whoami”
The payload is
/dangerzone?category=fashion%26%26whoami
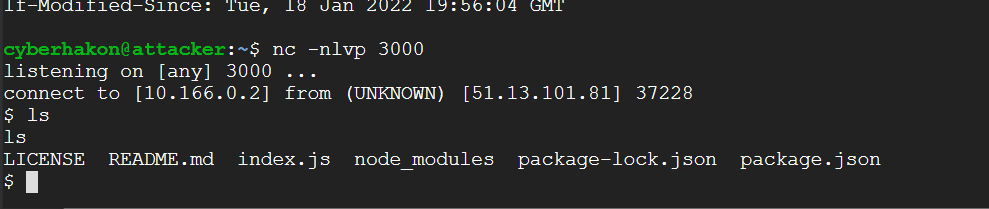
The output shows that we have command injection, and that the app is running as the user donkeyvictim. Now we can get a reverse shell to secure a bit more convenient access to the box. We have set up the VM to listen to port 3333, and use the following reverse shell payload generated by Online – Reverse Shell Generator (revshells.com):
Simple reverse shell received using netcat listener
Running ls shows that we are indeed in a reverse shell, but it is very crude. We can upgrade the shell using a neat Python trick from this page:
python3 -c 'import pty;pty.spawn("/bin/bash")'
The blog I took this from has a lot of tweaks you can do to get full autocomplete etc through the netcat listener, but this will do for a bit nicer experience.
What we now do on the attacker VM is to generate an SSH keypair. We then copy the public key to the authorized_keys file for user donkeyvictim on the VictimVM using our reverse shell. We now have established a persistent access channel.
Upgraded shell: the attacker’s console on GCP cloud shell, connected to VictimVM on Azure over SSH.
We obviously see that this activity was not stopped by Microsoft’s Defender for Cloud. But did it at least create some alerts for us? It seems the answer to that is “nope”.
If we turn to Microsoft Sentinel, there are also no incidents or alerts related to this activity.
Checking the logs
Can we then see it in the logs? We know at least that authentication events over SSH will create auth log entries. Since we have set up the Syslog connector in Sentinel, we get the logs into a tool that makes searching easier. The following search will reveal which IP addresses have authenticated with a publickey, and the username it has authenticated with.
Syslog
| where Computer == "victimvm"
| where SyslogMessage contains "Accepted publickey for"
| extend ip = extract("([0-9]+.[0-9]+.[0-9]+.[0-9]+)",1,SyslogMessage)
| extend username = extract("publickey for ([a-zA-Z0-9@!]+)",1,SyslogMessage)
| project TimeGenerated, username, ip
The output from this search is as follows:
Showing the same user logging in with ssh from two different ip addresses.
Here we see that the same user is logging in from two different IP addresses. Enriching it with geolocation data could make the suspicious login easier to detect, as the 212… Is in Norway, and the 34… Is a Google owned ip address in Finland.
In other words: it is possible to detect unusual login acticity by creating queries in Sentinel. At least it is something.
How could we have detected the attack?
But what about all the things leading up to the SSH login? We should definitly be able to stop this at an earlier point.
The payload sent to the application
The network egress when the reverse shell is generated
The change of the ~/.ssh/authorized_keys file
Because the application does not log messages anywhere but stdout, they are not captured anywhere. It would have been good if the application logged issues to a standard location that could be forwarded.
Detecting the attack when the reverse shell is generated is a good option. Here we can use the VMConnection data provided by the Defender for Cloud agent running on the VM.
VMConnection
| where Computer has "victimvm"
| where Direction == "outbound"
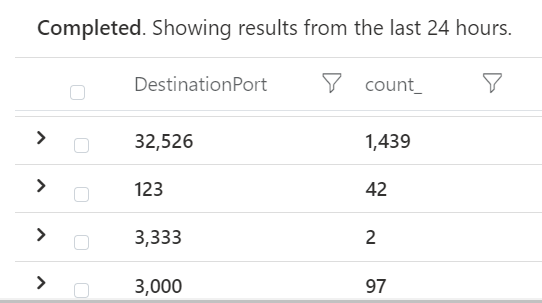
| summarize count() by DestinationPort
Here we look at which destination prots we see in egress traffic. Reverse shells will often use ports not requiring sudo rights, ie above 1000.
Count of outbound connections per destination port
We see we have outbound connections to port 3000. Looking into one of the log items we find some interesting information:
TimeGenerated [UTC]
2022-01-18T19:58:20.211Z
Computer
victimvm
Direction
outbound
ProcessName
python3
SourceIp
10.0.0.4
DestinationIp
34.88.132.129
DestinationPort
3000
Protocol
tcp
RemoteIp
34.88.132.129
RemoteLongitude
28.21
RemoteLatitude
61.03
RemoteCountry
Finland
We know that this is our reverse shell. We could then correlate the outbound connection to this IP address with later incoming SSH connection from this IP address. For relatively specific attack events we can in other words create detections. However, we don’t know in advance what persistence option the attacker would go for, or the port number used for the reverse shell.
A good idea would be to list the scenarios we would want to detect, and then build logging practices and correlations to help us create alerts for these incidents.
Can we throw more security at the VM to detect and stop attacks?
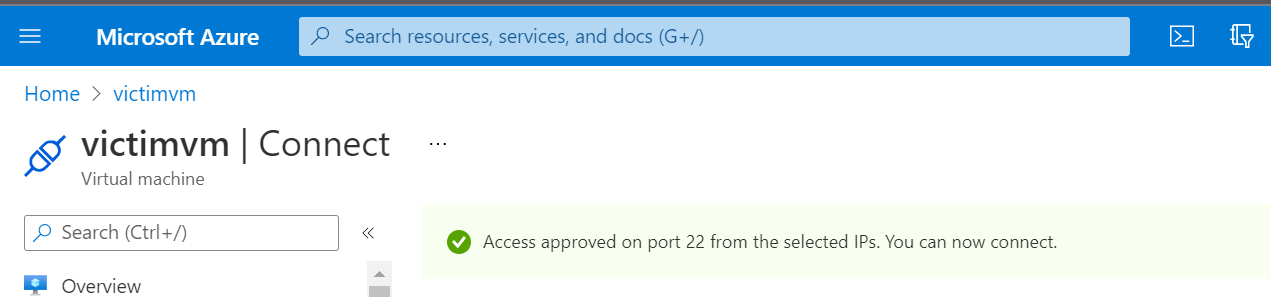
One thing Azure supports for VM’s if Defender for Cloud is enabled with “enhanced security” is “just-in-time access” for the VM. You need to pre-authorize access to open for inbound traffic to management ports through the network security group. The result of trying to connect with SSH after enabling it, is a timeout:
After enabling JIT access, our SSH connection times out without pre-approval.
We can now request access over SSH in Azure Portal by going to the VM’s overview page, and then selecting “connect”:
Pre-authorizing SSH access enables it for a defined period.
This will effectively stop an attacker’s persistence tactic but it will not take care of the remote command injection vulnerability.
For a web application we could also put a web application firewall in front of it to reduce the malicious payloads reaching the app. Even better is of course to only run code that has been developed with security in mind.
The key takeaways are:
Log forwarding is gold but you have to use it and set up your own alerts and correlations to make it help stop attacks
Enabling security solutions will help you but it will not take care of security for you. Setting up endpoint security won’t help you if the application code you are running is the problem.
Avoid exposing management ports directly on the internet if possible.
This weekend I decided to do a small experiment. Create two virtual machines in the cloud, one running Windows, and one running Linux. The Windows machine exposes RDP (port 3389) to the internet. The Linux machine exposes SSH (port 22). The Windows machines sees more than 10x the brute-force attempts of the Linux machine.
We capture logs, and watch the logon attempts. Here’s what I wanted to find out:
How many login attempts do we have in 24 hours?
What usernames are the bad guys trying with?
Where are the attacks coming from?
Is there a difference between the two virtual machines in terms of attack frequency?
The VM’s were set up in Azure, so it was easy to instrument them using Microsoft Sentinel. This makes it easy to query the logs and create some simple statistics.
Where are the bad bears coming from?
Let’s first have a look at the login attempts. Are all the hackers Russian bears, or are they coming from multiple places?
Windows
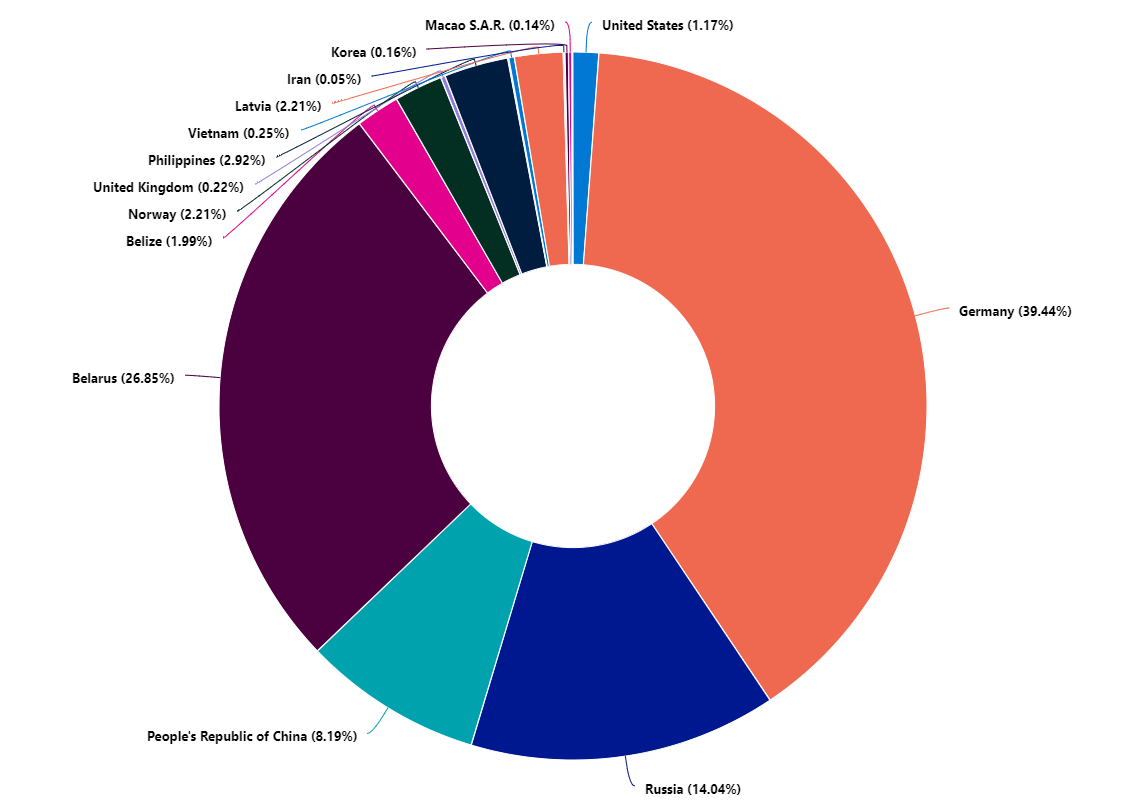
On Windows we observed more than 30.000 attempts over 24 hours. The distribution of attacks that the majority came from Germany, then Belarus, followed by Russia and China. We also see that there are some attempts from many countries, all around the globe.
Logon attempts on a Windows server over 24 hours
Linux
On Linux the situation is similar, although the Chinese bad guys are a lot more intense than the rest of them. We don’t see that massive amount of attacks from Germany on this VM. It is also less popular to attack the Linux VM: only 3000 attempts over 24 hours, about 10% of the number of login attempts observed on the Windows VM.
Logon attempts on a Linux server over 24 hours
What’s up with all those German hackers?
The German hackers are probably not German, or human hackers. These login attempts are coming from a number of IP addresses known to belong to a known botnet. That is; these are computers in Germany infected with a virus.
Usernames fancied by brute-force attackers
What are the usernames that attackers are trying to log in with?
Top 5 usernames on Linux:
Top 5 usernames on Windows:
We see that “admin” is a popular choice on both servers, which is perhaps not so surprising. On Linux the attackers seem to try a lot of typical service names, for example “ftp” as shown above. Here’s a collection of usernames seen in the logs:
zabbix
ftp
postgres
ansible
tomcat
git
dell
oracle1
redmine
samba
elasticsearch
apache
mysql
kafka
mongodb
sonar
Perhaps it is a good idea to avoid service names as account names, although the username itself is not a protection against unauthorized access.
There is a lot less of this in the Windows login attempts; here we primarily see variations of “administrator” and “user”.
Tips for avoiding brute-force attackers
The most obvious way to avoid brute-force attacks from the Internet, is clearly to not put your server on the Internet. There are many design patterns that allow you to avoid exposing RDP or SSH directly on the Internet. For example:
Only allow access to your server from the internal network, and set up a VPN solution with multi-factor authentication to get onto the local network remotely
Use a bastion host solution, where access to this host is strictly controlled
Use an access control solution that gives access through short-lived tokens, requiring multi-factor authentication for token access. Cloud providers have services of this type, such as just-in-time access on Azure or OS Login on GCP.
If you are using the Admin SDK on the server side, you have full access to everything by default. The Firestore security rules do not apply to the Admin SDK. One thing in particular we should be aware of is that the Firesbase admin SDK gives access to management plane functionality, making it possible to change security rules, for example. This is not apparent from the Firebase console or command line tools.
Running Firebase Cloud Functions using the Admin SDK with default permissions can quickly lead to a lot of firefighting. Better get those permissions under control!
In this blog post we dig into a Firebase project through the Google Cloud console and the gcloud command line tool, where we show how to improve the security of our capture-the-flag app by creating specific service accounts and role bindings for a cloud function. We also explore how to verify that a user is signed in using the Firebase Admin SDK.
A threat model for the flag checker
We have created a demo Firebase project with a simple web application at https://quizman-a9f1b.web.app/. This app has a simple CTF function, where a CTF challenge is presented, and players can verify if their identified flag is correct. The data exchange is primarily done using the JavaScript SDK, protected by security rules. For checking the flag, however, we are using a cloud function. If this cloud function has a vulnerability that allows an attacker to take control over it, that attacker could potentially overwrite the “correct flag”, or even change the security rules protecting the JavaScript SDK access.
Here’s a list of threats and potential consequences:
Vulnerability
Exploitation
Impact
RCE vulnerability in code
Attacker can take full control of the Firebase project environment through the admin SDK
Can read/write to private collection (cheat)Can create other resources (costs money)Can reconfigure security rules (data leaks or DoS)
Lack of brute-force protection
Attacker can try to guess flags by automating submission
User can cheatCosts money
Lack of authentication
An unauthenticated user can perform function calls
Costs money in spite of not being a real player of the CTF game
We need to make sure that attackers cannot exploit vulnerabilities to cheat in the program. We also want to protect against unavailability, and abuse that can drive up the cloud usage bill (after all this is a personal project). We will apply a defence-in-depth approach to our cloud function:
Execution of the function requires the caller to be authenticated. The purpose of this is to limit abuse, and to revoke access to users abusing the app.
The Firebase function shall only have read access to FIrestore, preferably only to the relevant collections. This will avoid the ability of an attacker with RCE to overwrite data, or to manage resources in the Firebase project.
For the following events we want to create logs and possibly alerts:
authenticated user verified token
unauthenticated user requested token verification
Requiring the user to be authenticated
First we need to make sure that the person requesting to verify a flag is authenticated. We can use a built-in method of the Firebase admin SDK to do this. This method checks that the ID token received is properly signed, and that it is not expired. The good thing about this approach is that it avoids making a call to the authentication backend.
But what if the token has been revoked? It is possible to check if a token is revoked using either security rules (recommended, cheap), or making an extra call to the authentication backend (expensive, not recommended). Since we are not actively revoking tokens in this app, unless a user changes his/her password, we will not bother with this functionality but if you need it, there is documentation how here: https://firebase.google.com/docs/auth/admin/manage-sessions#detect_id_token_revocation.
We need to update our “check flag workflow” from this:
send flag and challenge ID to cloud function
cloud function queries Firestore based on challenge ID and gets the “correct flag”
cloud function compares submitted flag with the correct flag, and returns {success: true/false} as appropriate
to this slightly more elaborate workflow:
send flag, challenge ID and user token to cloud function
cloud function verifies token ID
If invalid: return 403 (forbidden) // simplified to returning 200 with {success: false}
if valid:
cloud function queries Firestore based on challenge ID and gets the “correct flag”
cloud function compares submitted flag with the correct flag, and returns {success: true/false} as appropriate
The following code snippet shows how to perform the validation of the user’s token:
If the token is valid, we receive a decoded jwt back.
Restricting permissions using IAM roles
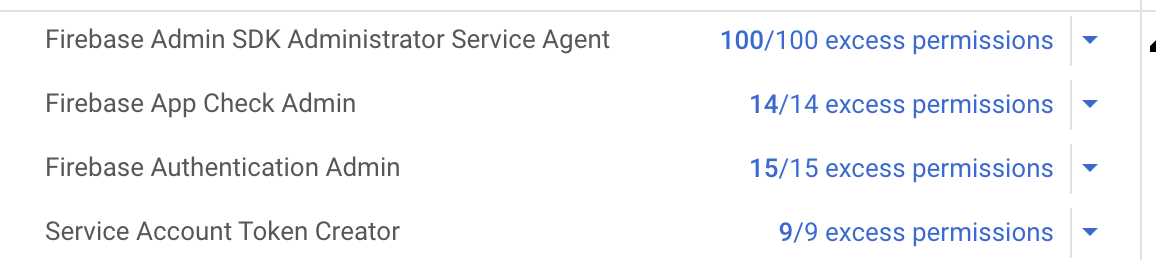
By default, a Firebase function initiated with the Firebase admin SDK has been assigned very powerful permissions. It gets automatically set up with a service account that is named as “firebase-adminsdk-random5chars@project-id.iam.gserviceaccount.com”. The service account itself does not have rights associated with it, but it has role bindings to roles that have permissions attached to it.
If you go into the Google Cloud Console, and navigate to “IAM” under your project, you can look up the roles assigned to a principal, such as your service account. For each role you automatically get an assessment of “excess permissions”; those are permissions available through the role bindings but that are not used in the project. Here’s the default configuration for the service account set up for the Admin SDK:
By default Firebase Cloud Functions run with excessive permissions!
Our Firebase cloud function does not need access to all those permissions. By creating roles that are fit for purpose we can limit the damage an attacker can do if the function is compromised. This is just the same principle in action as when your security awareness training tells you not to run your PC as admin for daily work.
Cloud resources have associated ready-made roles that one can bind a service account to. For Firestore objects the relevant IAM roles are listed here: https://cloud.google.com/firestore/docs/security/iam. We see that there is a viewer role that allows read access to all Firestore resources, called datastore.viewer. We will use this, but be aware it could read all Firestore data in the project, not only the intended objects. Still, we are protecting against deletion, overwriting data, and creation of new resources.
Note that it is possible to create more specific roles. We could create a role that only has permission to read from Firestore entities. We cannot in an IAM role describe exactly which Firestore collection to allow read operations from, but if we create the role flagchecker and assign it the permission datastore.entities.get and nothing else, it is as locked down as we can make it.
To implement this for our cloud function, we create a new service account. This can be done in the Console by going to IAM → Service Accounts → New Service Account. We create the account and assign it the role datastore.viewer.
Our new service account is called quizman-flag-checker.
Now we need to attach this service account to our Firebase function. It is not clear form the Firebase documentation how we can accomplish this, but opening the Google Cloud Console, or using the gcloud command line tool, we can attach our new service account with more restrictive permissions to the Firebase function.
To do this, we go into the Google Cloud console, choose the right project and Compute → Cloud functions. Select the right function, and then hit the “edit” button to change the function. Here you can choose the service account you want to attach to the function.
After changing the runtime service account, we need to deploy the function again. Now the service-to-service authentication is performed with a principal with more sensible permissions; attackers can no longer create their own resources or delete security rules.
Auditing the security configurations of a Firebase function using gcloud
Firebase is great for an easy set-up, but as we have seen it gives us too permissive roles by default. It can therefore be a good idea to audit the IAM roles used in your project.
Key questions to ask about the permissions of a cloud function are:
What is the service account this function is authenticating as?
What permissions do I have for this cloud function?
Do I have permissions that I do not need?
In addition to auditing the configuration, we want to audit changes to the configuration, in particular changes to service accounts, roles, and role bindings. This is easiest done using the log viewer tools in the Google Cloud console.
We’ll use the command line tool gcloud for the auditing, since this makes it possible to automate in scripts.
Service accounts and IAM roles for a Firebase function
Using the Google Cloud command line tool gcloud we can use the command
gcloud functions describe <functionName>
to get a lot of metadata about a function. To extract just the service account used you can pipe it into jq like this:
When we have the service account, we can next check which roles are bound to the account. This query is somewhat complex due to the nested data structure for role bindings on a project (for a good description of gcloud IAM queries, see fabianlee.org):
Running this gives us the following role (as expected): projects/quizman-a9f1b/roles/flagchecker.
Hence, we know this is the only role assigned to this service account. Now we finally need to list the permissions for this role. Here’s how we can do that:
cloud iam roles describe flagchecker --project=quizman-a9f1b --format="value(includedPermissions)”
The output (as expected) is a single permission: datastore.entities.get.
Do you like quizzes or capture the flag (CTF) exercises? Imagine we want to build a platform for creating a capture the flag exercise! We need the platform to present a challenge. When users solve the challenge, they find a “flag”, which can be a secret word or a random string. They should then be able to submit the flag in our CTF platform and check if it is correct or not.
Capture the flag can be fun: looking for a hidden flag whether physically or on a computer
To do this, we need a web server to host the CTF website, and we need a database to store challenges. We also need some functionality to check if we have found the right flag.
Firebase is a popular collection of serverless services from Google. It offers various easy to use solutions for quickly assembling applications for web or mobile, storing data, messaging, authentication, and so on. If you want to set up a basic web application with authentication and data storage without setting up backends, it is a good choice. Let’s create our CTF proof-of-concept on Firebase using Hosting + Firestore for data storage. Good for us, Google has created very readable documentation for how to add Firebase to web projects.
Firestore is a serverless NoSQL database solution that is part of Firebase. There are basically two ways of accessing the data in Firebase:
Directly from the frontend. The data is protected by Firestore security rules
Via an admin SDK meant for use on a server. By default the SDK has full access to everything in Firestore
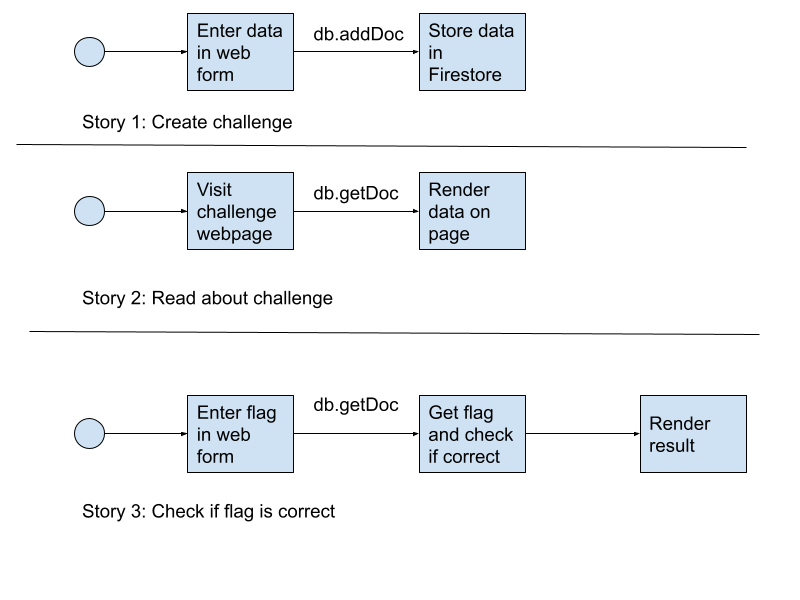
We don’t want to use a server, so we’ll work with the JavaScript SDK for the frontend. Here are the user stories we want to create:
As an organizer I want to create a CTF challenge in the platform and store it in Firebase so other users can find it and solve the challenge
As a player I want to view a challenge so that
As a player I want to create a form to submit a flag to check that it is correct
We want to avoid using a server, and we are simply using the JavaScript SDK. Diagrams for the user stories are shown below.
User stories for a simple CTF app example
What about security?
Let’s think about how attackers could abuse the functionalities we are trying to create.
Story 1: Create a challenge
For the first story, the primary concern is that nobody should be able to overwrite a challenge, including its flag.
Each challenge gets a unique ID. That part is taken care of by Firestore automatically, so an existing challenge will not be overwritten by coincidence. But the ID is exposed in the frontend, and so is the project metadata. Could an attacker modify an existing record, for example its flag, by sending a “PUT” request to the Firestore REST API?
Let’s say we have decided a user must be authenticated to create a challenge, and implemented this by the following Firebase security rule:
match /challenges/{challenges} {
allow read, write: if request.auth != null;
}
Hacking the challenge: overwriting data
This says nothing about overwriting existing data. It also has no restriction on what data the logged in user has access to – you can both read and write to challenges, as long as you are authenticated. Here’s how we can overwrite data in Firestore using set.
This challenge has the title “Fog” and description “on the water”. We want to hack this as another user directly in the Chrome dev tools to change the title to “Smoke”. Let’s first register a new user, cyberhakon+dummy@gmail.com and log in.
If we open devtools directly, we cannot find Firebase or similar objects in the console. That is because the implementation uses SDV v.9 with browser modules, making the JavaScript objects contained within the module. We therefore need to import the necessary modules ourselves. We’ll first open “view source” and copy the Firebase metadata.
We’ll simply paste this into the console while on our target challenge page. Next we need to import Firebase to interact with the data using the SDK. We could use SDK v.8 that is namespaced, but we can stick to v.9 using dynamic imports (works in Chrome although not yet a standard):
import('https://www.gstatic.com/firebasejs/9.6.1/firebase-app.js').then(m => firebase = m)
and
import('https://www.gstatic.com/firebasejs/9.6.1/firebase-firestore.js').then(m => firestore = m)
Now firestore and firebase are available in the console.
First, we initalize the app with var app = firebase.initializeApp(firebaseConfig), and the database with var db = firestore.getFirestore(). Next we pull information about the challenge we are looking at:
var mydoc = firestore.doc(db, "challenges", "wnhnbjrFFV0O5Bp93mUV");
var docdata = await firestore.getDoc(mydoc);
This works well. Here’s the data returned:
access: “open”
active: true
description: “on the water”
name: “Fog”
owner: “IEiW8lwwCpe5idCgmExLieYiLPq2”
score: 5
type: “ctf”
That is also as intended, as we want all users to be able to read about the challenges. But we can probably use setDoc as well as getDoc, right? Let’s try to hack the title back to “Smoke” instead of “Fog”. We use the following command in the console:
var output = await firestore.setDoc(mydoc, {name: “Smoke”},{merge: true})
Note the option “merge: true”. Without this, setDoc would overwrite the entire document. Refreshing the page now yields the intended result for the hacker!
Improving the security rules
Obviously this is not good security for a very serious capture-the-flag app. Let’s fix it with better security rules! Our current rules allows anyone who is authenticated to read data, but also to write data. Write here is shorthand for create, update, and delete! That means that anyone who is logged in can also delete a challenge. Let’s make sure that only owner can modify documents. We keep the rule for reading to any logged in user, but change the rule for writing to the following:
Safe rule against malicious overwrite:
allow write: if request.auth != null && request.auth.uid == resource.data.owner;
This means that authenticated users UID must match the “owner” field in the challenge.
Using the following security rules will allow anyone to create, update and delete data because the field “author_id” can be edited in the request directly. The comparison should be done as shown above, against the existing data for update using resource.data.<field_name>.
service cloud.firestore {
match /databases/{database}/documents {
// Allow only authenticated content owners access
match /some_collection/{document} {
allow read, write: if request.auth != null && request.auth.uid == request.resource.data.author_uid
}
}
}
// Example from link quoted above
There is, however, a problem with the rule marked “SAFE AGAINST MALICIOUS UPDATES” too; it will deny creation of new challenges! We thus need to split the write condition into two new rules, one for create (for any authenticated user), and another one for update and delete operations.
The final rules are thus:
allow read, create: if request.auth != null;
allow update, delete: if request.auth != null && request.auth.uid == resource.data.owner;
Story 2: Read the data for a challenge
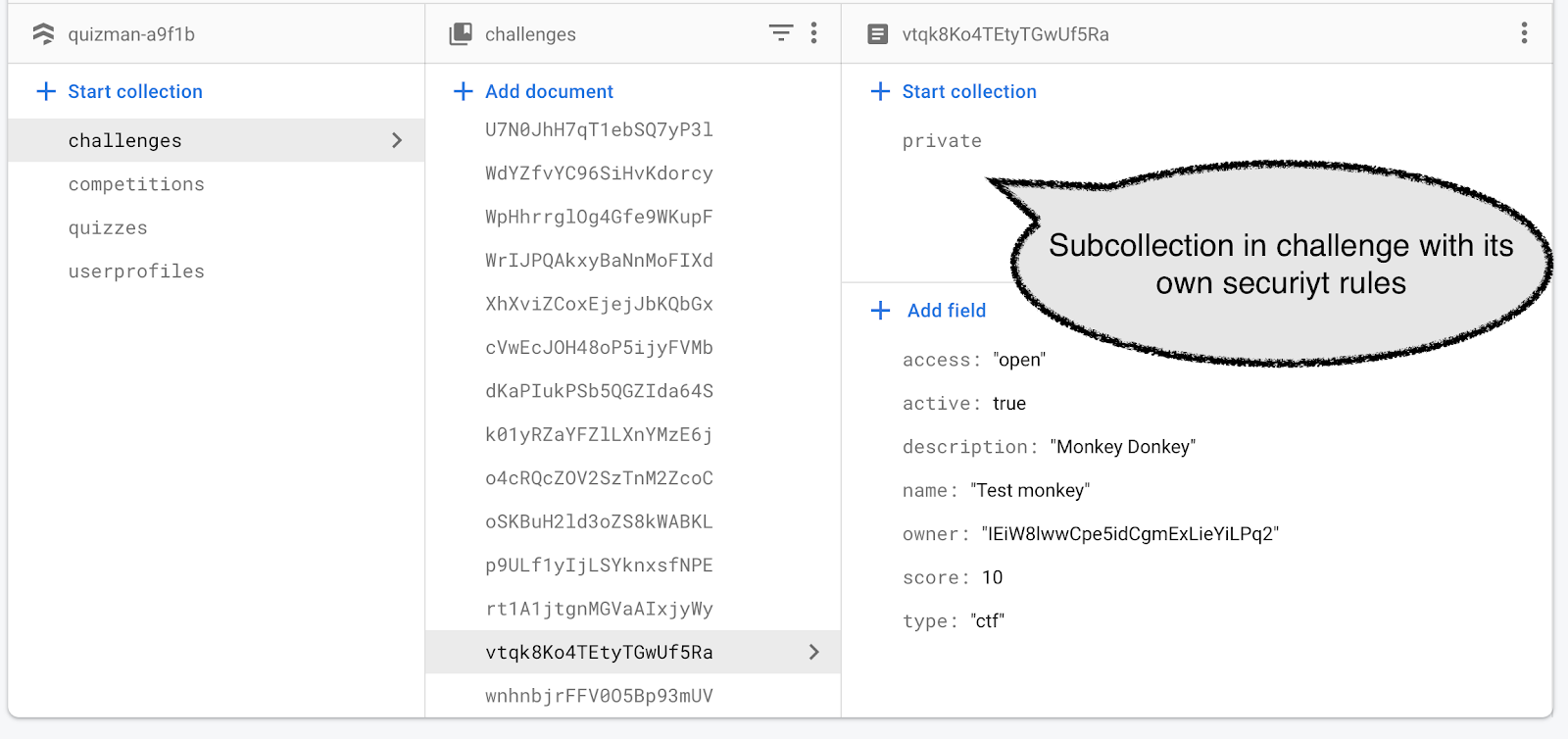
When reading data, the primary concern is to avoid that someone gets access to the flag, as that would make it possible for them to cheat in the challenge. Security rules apply to documents, not to fields in a document. This means that we cannot store a “secret” inside a document; access is an all or nothing decision. However, we can create a subcollection within a document, and apply separate rules to that subdocument. We have thus created a data structure like this:
Security rules are hierarchical, so we need to apply rules to /challenges/{challenge}/private/{document}/ to control access to “private”. Here we want the rules to allow only “create” a document under “private” but not to change it, and also not to read it. The purpose of blocking reading of the “private” documents is to avoid cheating.
But how can we then compare a player’s suggested flag with the stored one? We can’t in the frontend, and that is the point. We don’t want to expose the data in on the client side.
Story 3: Serverless functions to the rescue
Because we don’t want to expose the flag from the private subcollection in the frontend, we need a different pattern here. We will use Firebase cloud functions to do that. This is similar to AWS’ lambda functions, just running on GCP/Firebase instead. For our Firestore security, the important aspect is that a cloud function running in the same Firebase project has full access to everything in Firestore, and the security rules do not apply to the admin SDK used in functions. By default a cloud function is assigned an IAM role that gives it this access level. For improved security one can change the roles so that you allow only the access needed for each cloud function (here: read data from Firestore). We haven’t done that here, but this would allow us to improve security even further.
Serverless security engineering recap
Applications don’t magically secure themselves in the cloud, or by using serverless. With serverless computing, we are leaving all the infrastructure security to the cloud provider, but we still need to take care of our workload security.
In this post we looked at access control for the database part of a simple serverless web application. The authorization is implemented using security rules. These rules can be made very detailed, but it is important to test them thoroughly. Misconfigured security rules can suddenly allow an attacker to bypass your intended control.
Using Firebase, it is not obvious from the Firebase Console how to set up good application security monitoring and logging. Of course, that is equally important when using serverless as other types of infrastructure, both for detecting attacks, and for forensics after a successful breach. You can set up monitoring Google Cloud Monitoring for Firebase resources, including alerts for events you want to react to.
As always: basic security principles still hold with serverless computing!
The way we write, deploy and maintain software has changed greatly over the years, from waterfall to agile, from monoliths to microservices, from the basement server room to the cloud. Yet, many organizations haven’t changed their security engineering practices – leading to vulnerabilities, data breaches and lots of unpleasantness. This blog post is a summary of my thoughts on how security should be integrated from user story through coding and testing and up and away into the cyber clouds. I’ve developed my thinking around this as my work in the area has moved from industrial control systems and safety critical software to cloud native applications in the “internet economy”.
What is the source of a vulnerability?
At the outset of this discussion, let’s clarify two common terms, as they are used by me. In very unacademic terms:
Vulnerability: a flaw in the way a system is designed and operated, that allows an adversary to perform actions that are not intended to be available by the system owner.
A threat: actions performed on an asset in the system by an adversary in order to achieve an outcome that he or she is not supposed to be able to do.
The primary objective of security engineering is to stop adversaries from being able to achieve their evil deeds. Most often, evilness is possible because of system flaws. How these flaws end up in the system, is important to understand when we want to make life harder for the adversary. Vulnerabilities are flaws, but not all flaws are vulnerabilities. Fortunately, quality management helps reduce defects whether they can be exploited by evil hackers or not. Let’s look at three types of vulnerabilities we should work to abolish:
Bugs: coding errors, implementation flaws. The design and architecture is sound, but the implementation is not. A typical example of this is a SQL injection vulnerability in a web app.
Design flaws: errors in architecture and how the system is planned to work. A flawed plan that is implemented perfectly can be very vulnerable. A typical example of this is a broken authorization scheme.
Operational flaws: the system makes it hard for users to do things correctly, making it easier to trick privileged users to perform actions they should not. An example would be a confusing permission system, where an adversary uses social engineering of customer support to gain privilege escalation.
Security touchpoints in a DevOps lifecycle
Traditionally there has been a lot of discussion on a secure development lifecycle. But our concern is removing vulnerabilities from the system as a whole, so we should follow the system from infancy through operations. The following touchpoints do not make up a blueprint, it is an overview of security aspects in different system phases.
Dev and test environment:
Dev environment helpers
Pipeline security automation
CI/CD security configuration
Metrics and build acceptance
Rigor vs agility
User roles and stories
Rights management
Architecture: data flow diagram
Threat modeling
Mitigation planning
Validation requirements
Sprint planning
User story reviews
Threat model refinement
Security validation testing
Coding
Secure coding practices
Logging for detection
Abuse case injection
Pipeline security testing
Dependency checks
Static analysis
Mitigation testing
Unit and integration testing
Detectability
Dynamic analysis
Build configuration auditing
Security debt management
Vulnerability prioritization
Workload planning
Compatibility blockers
Runtime monitoring
Feedback from ops
Production vulnerability identification
Hot fixes are normal
Incident response feedback
Dev environment aspects
If an adversary takes control of the development environment, he or she can likely inject malicious code in a project. Securing that environment becomes important. The first principle should be: do not use production data, configurations or servers in development. Make sure those are properly separated.
The developer workstation should also be properly hardened, as should any cloud accounts used during development, such as Github, or a cloud based build pipeline. Two-factor auth, patching, no working on admin accounts, encrypt network traffic.
The CI/CD pipeline should be configured securely. No hard-coded secrets, limit who can access them. Control who can change the build config.
During early phases of a project it is tempting to be relaxed with testing, dependency vulnerabilities and so on. This can quickly turn into technical debt – first in one service, then in many, and at the end there is no way to refinance your security debt at lower interest rates. Technical debt compounds like credit card debt – so manage it carefully from the beginning. To help with this, create acceptable build thresholds, and a policy on lifetime of accepted poor metrics. Take metrics from testing tools and let them guide: complexity, code coverage, number of vulnerabilities with CVSS above X, etc. Don’t select too many KPI’s, but don’t allow the ones you track to slip.
One could argue that strict policies and acceptance criteria will hurt agility and slow a project down. Truth is that lack of rigor will come back to bite us, but at the same time too much will indeed slow us down or even turn our agility into a stale bureaucracy. Finding the right balance is important, and this should be informed by context. A system processing large amounts of sensitive personal information requires more formalism and governance than a system where a breach would have less severe consequences. One size does not fit all.
User roles and stories
Most systems have diffent types of users with different needs – and different access rights. Hackers love developers who don’t plan in terms of user roles and stories – the things each user would need to do with the system, because lack of planning often leads to much more liberal permissions “just in case”. User roles and stories should thus be a primary security tool. Consider a simple app for approval of travel expenses in a company. This app has two primary user types:
Travelling salesmen who need reimbursements
Bosses who will approve or reject reimbursement claims
In addition to this, someone must be able of adding and removing users, granting access to the right travelling salesmen for a given boss, etc. The system also needs an Administrator, with other words.
Let’s take the travelling salesman and look at “user stories” that this role would generate:
I need to enter my expenses into a report
I need to attach documentation such as receipts to this report
I need to be able of sending the report to the boss for approval
I want to see the approval status of my expense report
I need to recieve a notification if my report is not approved
I need to be able of correcting any mistakes based on the rejection
Based on this, it is clear that the permissions of the “travelling salesman” role only needs to give write access to some operations, for data relating to this specific user, and needs read rights on the status of the approval. This goes directly into our authorization concept for the app, and already here generates testable security annotations:
A travelling salesman should not be able to read the expense report of another travelling salesman
A travellign salesman should not be able of approving expense reports, including his own
These negative unit tests could already go into the design as “security annotations” for the user stories.
In addition to user stories, we have abusers and abuse stories. This is about the type of adversaries, and what they would like to do, that we don’t want them to be able of achieving. Let’s take as an example a hacker hired by a competitor to perform industrial espionage. We have the adversary role “industrial espionage”. Here are some abuse cases we can define that relate to motivation of a player rather than technical vulnerabilities:
I want to access all travel reports to map where the sales personnel of the firm are going to see clients
I want to see the financial data approved to gauge the size of their travel budget, which would give me information on the size of their operation
I’d like to find names of people from their clients they have taken out to dinner, so we know who they are talking to at potential client companies
I’d like to get user names and personal data that allow med to gauge if some of the employees could be recurited as insiders or poached to come work for us instead
How is this hypothetical information useful for someone designing an app to use for expense reporting? By knowing the motivations of the adversaries we can better gauge the credibility that a certain type of vulnerability will be attempted exploited. Remember: Vulnerabilities are not the same as threats – and we have limited resources, so the vulnerabilities that would help attackers achieve their goals are more important to remove than those that cannot easily help the adversary.
Vulnerabilities are not the same as threats – and we have limited resources, so the vulnerabilities that would help attackers achieve their goals are more important to remove than those that cannot easily help the adversary.
Coming back to the sources of vulnerabilities, we want to avoid vulnerabilities of three kinds; software bugs, software design flaws, and flaws in operating procedures. Bugs are implementation errors, and the way we try to avoid them is by managing competence, workload and stress level, and by use of automated security testing such as static analysis and similar tools. Experience from software reliability engineering shows that about 50% of software flaws are implementation erorrs – the rest would then be design flaws. These are designs and architectures that do not implement the intentions of the designer. Static analysis cannot help us here, because there may be no coding errors such as lack of exception handling or lack of input validation – it is just the concept that is wrong; for example giving a user role too many privileges, or allowing a component to talk to a component it shouldn’t have access to. A good tool for identificaiton of such design flaws is threat modeling based on a data flow diagram. Make a diagram of the software data flow, break it down into components on a reasonable level, and consider how an adversary could attack each component and what could be the impact of this. By going through an excercise like this, you will likely identify potential vulnerabilities and weaknesses that you need to handle. The mitigations you introduce may be various security controls – such as blocking internet access for a server that only needs to be available on the internal network. The next question then is – how do you validate that your controls work? Do you order a penetration test form a consulting company? That could work, but it doesn’t scale very well, you want this to work in your pipeline. The primary tools to turn to is unit and integration testing.
We will not discuss the techniques for threat modeling in this post, but there are different techniques that can be applied. Keep it practical, don’t dive too deep into the details – it is better to start with a higher level view on things, and rather refine it as the design is matured. Here are some methods that can be applied in software threat modeling:
Often a STRIDE-like approach is a good start, and for the worst case scenarios it can be worthwhile diving into more detail with attack trees. An attack tree is a fault tree applied to adversarial modeling.
After the key threats have been identified, it is time to plan how to deal with that risk. We should apply the defense-in-depth principle, and remeber that a single security control is usually not enough to stop all attacks – because we do not know what all possible attack patterns are. When we have come up with mitigations for the threats we worry about, we need to validate that they actually work. This validation should happen at the lowest possible level – unit tests, integration tests. It is a good idea for the developer to run his or her own tests, but these validations definitely must live in the build pipeline.
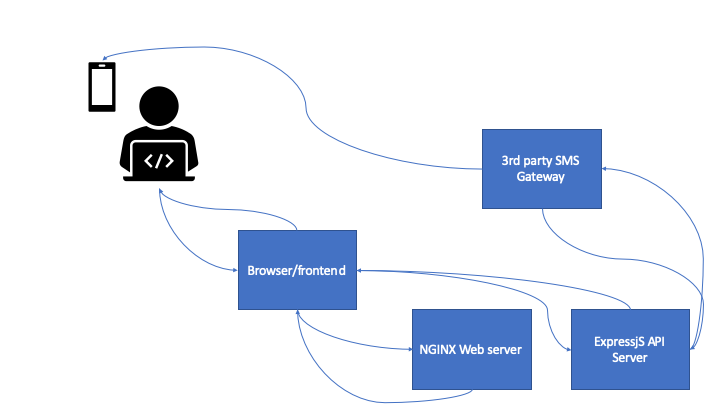
Let’s consider a two-factor authentication flow using SMS-based two-factor authentication. This is the authentication for an application used by politicians, and there are skilled threat actors who would like to gain access to individual accounts.
A simple data flow diagram for a 2FA flow
Here’s how the authentication process work:
User connects to the domain and gets an single-page application loaded in the browser with a login form with username and password
The user enters credentials, that are sent as a post request to the API server, which validates it with stored credentials (hashed in a safe way) in a database. The API server only accepts requests from the right domain, and the DB server is not internet accessible.
When the correct credentials have been added, the SPA updates with a 2fa challenge, and the API server sends a post request to a third-party SMS gateway, which sends the token to the user’s cell phone.
The user enters the code, and if valid, is authenticated. A JWT is returned to the browser and stored in localstorage.
Let’s put on the dark hat and consider how we can take over this process.
SIM card swapping combined wiht a phishing email to capture the credentials
SIM card swapping combined with keylogger malware for password capture
Phishing capturing both password and the second factor from a spoofed login page, and reusing credentials immediately
Create an evil browser extension and trick the user to install it using social engineering. Use the browser extension to steal the token.
Compromise a dependency used by the application’s frontend, to allow man-in-the-browser attacks that can steal the JWT after login.
Compromise a dependency used in the API to give direct access to the API server and the database
Compromise the 3rd party SMS gateway to capture credentials, use password captured with phishing or some other technique
Exploit a vulnerability in the API to bypass authentication, either in a dependency or in the code itself.
As we see, the threat is the adversary getting access to a user account. There are many attack patterns that could be used, and only one of them involves only the code written in the application. If we are going to start planning mitigations here, we could first get rid of the two first problems by not using SMS for two-factor authenticaiton but rather relying on an authenticator app, like Google Authenticator. Test: no requests to the SMS gateway.
Phishing: avoid direct post requests from a phishing domain to the API server by only allowing CORS requests from our own domain. Send a verification email when a login is detected from an unknown machine. Tests: check that CORS from other domains fail, and check that an email is sent when a new login occurs.
Browser extensions: capture metadata/fingerprint data and detect token reuse across multiple machines. Test: same token in different browsers/machines should lead to detection and logout.
Compromised dependencies is a particularly difficult attack vector to deal with as the vulnerability is typically unknown. This is in practice a zero-day. For token theft, the mitigation of using meta-data is valid. In addition it is good practice to have a process for acceptance of third-party libraries beyond checking for “known vulnerabilities”. Compromise of the third-party SMS gateway is also difficult to deal with in the software project, but should be part of a supply chain risk management program – but this problem is solved by removing the third-party.
Exploit a vulnerability in the app’s API: perform static analysis and dependency analysis to minimize known vulnerabilities. Test: no high-risk vulnerabilities detected with static analysis or dependency checks.
We see that in spite of having many risk reduction controls in place, we do not cover everything that we know, and there are guaranteed to be attack vectors in use that we do not know about.
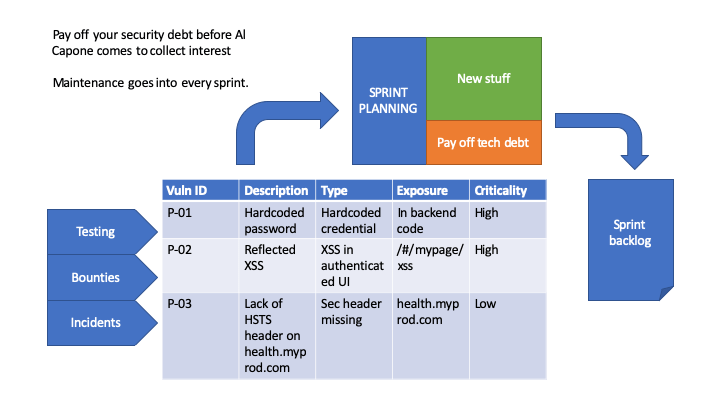
Sprint planning – keeping the threat model alive
Sometimes “secure development” methodologies receive criticims for “being slow”. Too much analysis, the sprint stops, productivity drops. This is obviously not good, so the question is rather “how can we make security a natural part of the sprint”? One answer to that, at least a partial one, is to have a threat model based on the overall architecture. When it is time for sprint planning, there are three essential pieces that should be revisited:
The user stories or story points we are addressing; do they introduce threats or points of attack not already accounted for?
Is the threat model we created still representative for what we are planning to implement? Take a look at the data flow diagram and see if anything has changed – if it has, evaluate if the threat model needs to be updated too.
Finally: for the threats relevant to the issues in the sprint backlog, do we have validation for the planned security controls?
Simply discussing these three issues would often be enough to see if there are more “known uknowns” that we need to take care of, and will allow us to update the backlog and test plan with the appropriate annotations and issues.
Coding: the mother of bugs after the design flaws have been agreed upon
The threat modeling as discussed above has as its main purpose to uncover “design flaws”. While writing code, it is perfectly possible to implement a flawed plan in a flawless manner. That is why we should really invest a lot of effort in creating a plan that makes sense. The other half of vulnerabilities are bugs – coding errors. As long as people are still writing code, and not some very smart AI, errors in code will be related to human factors – or human error, as it is popularly called. This often points the finger of blame at a single individual (the developer), but since none of us are working in vacuum, there are many factors that influence these bugs. Let us try to classify these errors (leaning heavily on human factors research) – broadly there are 3 classes of human error:
Slips: errors made due to lack of attention, a mishap. Think of this like a typo; you know how to spell a word but you make a small mistake, perhaps because your mind is elsewhere or because the keyboard you are typing on is unfamiliar.
Competence gaps: you don’t really know how to do the thing you are trying to do, and this lack of knowledge and practice leads you to make the wrong choice. Think of an inexperienced vehicle driver on a slippery road in the dark of the night.
Malicious error injection: an insider writes bad code on purpose to hurt the company – for example because he or she is being blackmailed.
Let’s leave the evil programmer aside and focus on how to minimize bugs that are created due to other factors. Starting with “slips” – which factors would influence us to make such errors? Here are some:
Not enough practice to make the action to take “natural”
High levels of stress
Lack of sleep
Task overload: too many things going on at once
Outside disturbances (noise, people talking to you about other things)
It is not obvious that the typical open office plan favored by IT firms is the optimal layout for programmers. Workload management, work-life balance and physical working environment are important factors for avoiding such “random bugs” – and therefore also important for the security of your software.
These are mostly “trying to do the right thing but doing it wrong” type of errors. Let’s now turn to the lack of competence side of the equation. Developers have often been trained in complex problem solving – but not necessarily in protecting software from abuse. Secure coding practices, such as how to avoid SQL injection, why you need output escaping and similar types of practical application secuity knowledge, is often not gained by studying computer science. It is also likely that a more self-taught individual would have skipped over such challenges, as the natural focus is on “solving the problem at hand”. This is why a secure coding practice must deliberately be created within an organization, and training and resources provided to teams to make it work. A good baseline should include:
How to protect aginst OWASP Top 10 type vulnerabilities
Secrets management: how to protect secrets in development and production
Detectability of cyber threats: application logging practices
An organization with a plan for this and appropriate training to make sure everyone’s on the same page, will stand a much better chance of avoiding the “competence gap” type errors.
Security testing in the build pipeline
OK, so you have planned your software, created a threat model, commited code. The CI/CD build pipeline triggers. What’s there to stop bad code from reaching your production environment? Let’s consider the potential locations of exploitable bugs in our product:
My code
The libraries used in that code
The environment where my software runs (typically a container in today’s world)
Obviously, if we are trying to push something with known critical errors in either of those locations to production, our pipeline should not accept that. Starting with our own code, a standard test that can uncover many bugs is “static analysis”. Depending on the rules you use, this can be a very good security control but it has limitations. Typically it will find a hardcoded password written as
var password = 'very_secret_password";
but it may not find this password if it isn’t a little bit smart:
var tempstring = 'something_that_may_be_just_a_string";
and yet it may throw an alert on
var password = getsecret();
just because the word “password” is in there. So using the right rules, and tuning them, is important to make this work. Static analysis should be a minimum test to always include.
The next part is our dependencies. Using libraries with known vulnerabilities is a common problem that makes life easy for the adversary. This is why you should always scan the code for external libraries and check if there are known vulnerabilitie sin them. Commercial vendors of such tools often refer to it as “software component analysis”. The primary function is to list all dependencies, check them against databases of known vulnerabilities, and create alerts accordingly. And break the build process based on threshold limits.
Also the enviornment we run on should be secure. When building a container image, make sure it does not contain known vulnerabilities. Using a scanner tool for this is also a good idea.
While static analysis is primarily a build step, testing for known vulnerabilities whether in code libraries or in the environment, should be done regulary to avoid vulnerabilities discovered after the code is deployed from remaining in production over time. Testing the inventory of dependencies against a database of known vulnerabiltiies regulary would be an effective control for this type of risk.
If a library or a dependency in the environment has been injected with malicious code in the supply chain, a simple scan will not identify it. Supply chain risk management is required to keep this type of threat under control, and there are no known trustworthy methods of automatically identifying maliciously injected code in third-party dependencies in the pipeline. One principle that should be followed with respect to this type of threat, however, is minimization of the attack surface. Avoid very deep dependency trees – like an NPM project 25000 dependencies made by 21000 different contributors. Trusting 21000 strangers in your project can be a hard sell.
Another test that should preferably be part of the pipeline, is dynamic testing where actual payloads are tested against injection points. This will typically uncover other vulnerabilities than static analysis will and is thus a good addition. Note that active scanning can take down infrastructure or cause unforeseen errors, so it is a good idea to test against a staging/test environment, and not against production infrastructure.
Finally – we have the tests that will validate the mitigations identified during threat modeling. Unit tests and integration tests for securtiy controls should be added to the pipeline.
Modern environments are usually defined in YAML files (or other types of config files), not by technicians drawing cables. The benefit of this, is that the configuration can be easily tested. It is therefore a good idea to create acceptance tests for your Dockerfiles, Helm charts and other configuration files, to avoid an insider from altering it, or by mistake setting things up to be vulnerable.
Security debt has a high interest rate
Technical debt is a curious beast: if you fail to address it it will compound and likely ruin your project. The worst kind is security debt: whereas not fixing performance issues, removing dead code and so on compunds like a credit card from your bank, leaving vulnerabilities in the code compunds like interest on money you lent from Raymond Reddington. Manage your debt, or you will go out of business based on a ransomware compaign followed by a GDPR fine and some interesting media coverage…
You need to plan for time to pay off your technical debt, in particular your securiyt debt.
Say you want to plan using a certain percentage of your time in a sprint on fixing technical debt, how do you choose which issues to take? I suggest you create a simple prioritization system:
Exposed before internal
Easy to exploit before hard
High impact before low impact
But no matter what method you use to prioritize, the most important thing is that you work on getting rid of known vulnerbilities as part of “business-as-usual”. To avoid going bankrupt due to overwhelming technical debt. Or being hacked.
Sometimes the action you need to take to get rid of a security hole can create other problems. Like installing an update that is not compatible with your code. When this is the case, you may need to spend more resources on it than a “normal” vulnerability because you need to do code rewrites – and that refactoring may also need you to update your threat model and risk mitigations.
Operations: your code on the battle field
In production your code is exposed to its users, and in part it may also be exposed to the internet as a whole. Dealing with feedback from this jungle should be seen as a key part of your vulnerability management program.
First of all, you will get access to logs and feedback from operations, whether it is performance related, bug detections or security incidents. It is important that you feed this into your issue management system and deal with it throughout sprints. Sometimes you may even have a critical situation requiring you to push a “hotfix” – a change to the code as fast as possible. The good thing about a good pipeline is that your hotfix will still go through basic security testing. Hopefully, your agile security process and your CI/CD pipeline is now working so well in symbiosis that it doesn’t slow your hotfix down. In other words: the “hotfix” you are pushing is just a code commit like all others – you are pushing to production several times a day, so how would this be any different?
Another aspect is feedback from incident response. There are two levels of incident response feedback that we should consider:
Incident containment/eradication leading to hotfixes.
Security improvements from the lessons learned stage of incident response
The first part we have already considered. The second part could be improvements to detections, better logging, etc. These should go into the product backlog and be handled during the normal sprints. Don’t let lessons learned end up as a PowerPoint given to a manager – a real lesson learned ends up as a change in your code, your environment, your documentation, or in the incident response procedures themselves.
Key takeaways
This was a long post, here are the key practices to take away from it!
Remember that vulnerabilities come from poor operational practices, flaws in design/architecture, and from bugs (implementation errors). Linting only helps with bugs.
Use threat modeling to identity operational and design weaknesses
All errors are human errors. A good working environment helps reduce vulnerabilities (see performance shaping factors).
Validate mitigations using unit tests and integration tests.
This has been the first week back at work after 3 weeks of vacation. Vacation was mostly spent playing with the kids, relaxing on the beach and building a garden fence. Then Monday morning came and reality came back, demanding a solid dose of coffee.
Wave of phishing attacks. One of those led to a lightweight investigation finding the phishing site set up for credential capture on a hacked WordPress site (as usual). This time the hacked site was a Malaysian site set up to sell testosteron and doping products… and digging around on that site, a colleague of mine found the hackers’ uploaded webshell. A gem with lots of hacking batteries included.
Next task: due diligence of a SaaS vendor, testing password reset. Found out they are using Base64 encoded userID’s as “random tokens” for password reset – meaning it is possible to reset the password for any user. The vendor has been notified (they are hopefully working on it).
Surfing Facebook, there’s an ad for a productivity tool. Curious as I am I create an account, and by habit I try to set a very weak password (12345). The app accepts this. Logging in to a fancy app, I can then by forced browsing look at the data from all users. No authorization checks. And btw, there is no way to change your password, or reset it if you forget. This is a commercial product. Don’t forget to do some due diligence, people.
Phishing for credentials?
Phishing is a hacker’s workhorse, and for compromising an enterprise it is by far the most effective tool, especially if those firms are not using two-factor authentication. Phishing campaigns tend to come in bursts, and this needs to be handled by helpdesk or some other IT team. And with all the spam filters in the world, and regular awareness training, you can reduce the number of compromised accounts, but it is still going to succeed every single time. This is why the right solution to this is not to think that you can stop every malicious email or train every user to always be vigilant – the solution is primarily: multifactor authentication. Sure, it is possible to bypass many forms of it, but it is far more difficult to do than to just steal a username and a password.
Another good idea is to use a password manager. It will not offer to fill in passwords on sites that aren’t actually on the domain they pretend to be.
To secure against phishing, don’t rely on awareness training and spam filters only. Turn on 2FA and use a password manager for all passwords. #infosec
The password reset thing was interesting. First on this app I registered an account with a Mailinator email account and the password “passw0rd”. Promising.. Then trying the “I forgot” on login to see if the password recovery flow was broken – and it really was in a very obvious way. Password reset links are typically sent by email. Here’s how it should work:
You are sent a one-time link to recover your password. The link should contain an unguessable token and should be disabled once clicked. The link should also expire after a certain time, for example one hour.
This one sent a link, that did not expire, and that would work several times in a row. And the unguessable token? Looked something like this: “MTAxMjM0”. Hm… that’s too short to really be a random sequence worth anything at all. Trying to identify if this is a hash or something encoded, the first thing we try is to decode from Base64 – and behold – we can a 6-digit number (101234 in this case, not the userID from this app). Creating a new account, and then doing the same reveals we get the next number (like 101235). In other words, using the reset link of the type /password/iforgot/token/MTAxMjM0, we can simply Base64 encode a sequence of numbers and reset the passwords for every user.
Was this a hobbyist app made by a hobbyist developer? No, it is an enterprise app used by big firms. Does it contain personal data? Oh, yes. They have been notified, and I’m waiting for feedback from them on how soon they will have deployed a fix.
Broken access control
The case with the non-random random reset token is an example of broken authentication. But before the week is over we also need an example of broken access control. Another web app, another dumpster fire. This was a post shared on social media that looked like an interesting product. I created an account. Password this time: 12345. It worked. Of course it did…
This time there is no password reset function to test, but I suspect if there had been one it wouldn’t have been better than the one just described above.
This app had a forced browsing vulnerability. It was a project tracking app. Logging in, and creating a project, I got an URL of the following kind: /project/52/dashboard. I changed 52 to 25 – and found the project goals of somebody planning an event in Brazil. With budgets and all. The developer has been notified.
Always check the security of the apps you would like to use. And always turn on maximum security on authentication (use a password manager, use 2FA everywhere). Don’t get pwnd. #infosec
Insecure direct object reference (IDOR) is a common type of vulnerability online. Normally we think of this as a vulnerable parameter in a URL or a form that allows forced browsing, but file downloads can also be an issue here. For a general background on IDOR and how to secure against it, see this cheatsheet from OWASP.
Our case is a bit different. Consider storing files in a cloud storage bucket (Google Cloud Storage, Amazon S3, etc). This may be for a file sharing site for example, where users are allowed to upload documents that are then stored in a bucket. We only want the users with the right authorisation to have access to these files. What are our options?
Use cloud identity management and bucket security rules to manage access. This may be impractical as we don’t necessarily want to give app users IAM users in the cloud environment, but where applicable it is a direct solution to our little security problem.
Allow full access to the bucket from the app and manage user permissions in the app.
Make the object public but use non-descriptive and random filenames so unauthorised users cannot easily guess the right path. Maintain the link to contextual data in the backend code to not expose it publicly.
Same as 3 but with a signed URL – a temporary ‘secret’ URL where permissions can be controlled without creating specific IAM users.
Google has made a list of best practices for cloud storage here. In our use case we want the shared object to have permanent permissions. Let us consider how to achieve acceptable security using option 2.
A simple architecture for sharing files securely
For this set-up there are a few things we need to take care of:
For uploaded files do not expose the actual bucket meta data or file names to the user in the frontend. Create a reference in the database that maps to the object name in the bucket
Manage access to objects through the database references, for example by adding a “shared with” key containing user ID’s for all users who are going to have read access to the object.
Do not make the object publicly accessible. Instead use a service account IAM user for the application and allow the permissions you need. Download content to the app, and relay this to the frontend using the mapping described above to avoid exposing the actual object name.
What are the threat vectors to this method for securing shared files?
This is a relatively simple setup that avoids making a bucket, or objects in that bucket, publicly available. It is still possible to exploit to gain unauthorised access but this is no longer as easy as finding an unsecured bucket.
Identity spoofing: a hacker can take on the identity of a user of the application, and thus get access to the files this user has access to. To avoid this, make sure to follow good practices for authentication (strong passwords, two-factor authentication). Also keep identity secrets on the client side hard to get at by securing the frontend against cross-site scripting (XSS), turning on security headers and setting parameters on cookies to avoid easy exposure.
Database server: A hacker may try to guess the database credentials directly, either using a connection string or through the management plane of a cloud provider. Make sure to use multiple layers of defence. If using a cloud accessible database, make sure the management plane is sufficiently secured. Use IP whitelisting or cloud security groups to limit access to the database, and use a strong authentication secret.
Bucket security: Hackers will look for publicly available buckets. Make sure the bucket is not accessible from the internet. limit accessibility to the relevant cloud security group, or from whitelisted IP addresses if accessed from outside the cloud.
Monitoring: turn on monitoring of file access in the application, and consider also logging access on database and bucket level. Regularly review logs to look for unauthorised access or unusual behaviour.
Information governance is the management practices we introduce to enusre that data and information complies with organizational policies, standards and strategy, including regulatory, contractual and business objectives.
There are several aspects of cloud storage of data that has implications for information governance.
Public cloud deployments are multi-tenant. That means that there will be other organizations also storing their information in the same datacenter, on the same hardware. The security features for account separation will thus be an important part of achieving information compliance in most cases.
As data is shared across cloud infrastructure, so is the responsibility for securing the data. To define a working governance structure it is important to define data ownership and who the data custodian is. The difference between the two, is that the former is who actually owns the data (and is accountable for its governance), and the latter who manages the data (and is responsible for ensuring compliance in practice).
When we host third-party data in the cloud, we are introducing a third-party into the governance model. This third-party is the cloud provider; the information governance now depends on the provider’s management practices and technologies offered by the cloud provider. This complicates the regulatory compliance considerations we need to make and should be taken into account when designing a project’s regulatory compliance matrix. First, legal requirements may change because the cloud stores, or makes data available, in more geographical regions that would otherwise be the case. Compliance, regulations, and in particular privacy, should be carefully reviewed with regard to how governance is managed in the cloud for customer data. Further, one should ensure that customer requirements to deletion (destruction) of data is possible to satisfy given the technical offerings from the cloud provider.
Moving data to the cloud provides a welcome opportunity to review and perhaps redesign information architectures. In many organizations information architectures have evolved over a long time, perhaps with little planning, and may have resulted in a fractured model where it is hard to manage compliance.
Cloud information governance domains
Cloud computing can have an effect on multiple aspects of data governance. The following list defined issues the CSA has described as affected by cloud artifacts:
Information classification. Often tied to storage and handling requirements, that may include limitations on access, location. Storing information in an S3 bucket will require a different method for access control than using a file share on the local network.
Information management practices. How data is managed based on classification. This should include different cloud deployment models (or SPI tiers: SaaS, PaaS, IaaS). You need to decide what can be allowed where in the cloud, with which products and services and with which security requirements.
Location and jurisdiction policies. You need to comply with regulations and contractual obligations with respect to data storage, data access. Make sure you understand how data is processed and stored, and the contractual instruments in place to manage regulatory compliance. One primary example here is personal data under the GDPR, and how data processing agreements with cross-border transfer clauses can be used to manage foreign jurisdictions.
Authorizations. Cloud computing does not typically require much changes to authorizations but the data security lifecycle will most likely be impacted. The way authorization controls are implemented may also change (e.g. IAM practices of the cloud vendor for account level authorization).
Ownership. The organization owns its data and this is not changed when moving to cloud. One should be careful with reviewing the terms and conditions of cloud providers here, in particular SaaS products (especially those targeting the consumer market).
Custodianship. The cloud provider may fully or partially become the custodian, depending on the deployment model. Encrypted data stored in a cloud bucket is still under custody of the cloud provider.
Privacy. Privacy needs to be handled in accordance with relevant regulations, and the necessary contractual instruments such as data processing agreements must be put in place.
Contractual controls. Contractual controls when moving data and workloads to control will be different from controls you employ in an on-premise infrastructure. There will often be limited access to contract clause negotiations in public cloud environments.
Security controls. Security controls are different in cloud environments than in on-premise environments. Main concepts are security groups and access control lists.
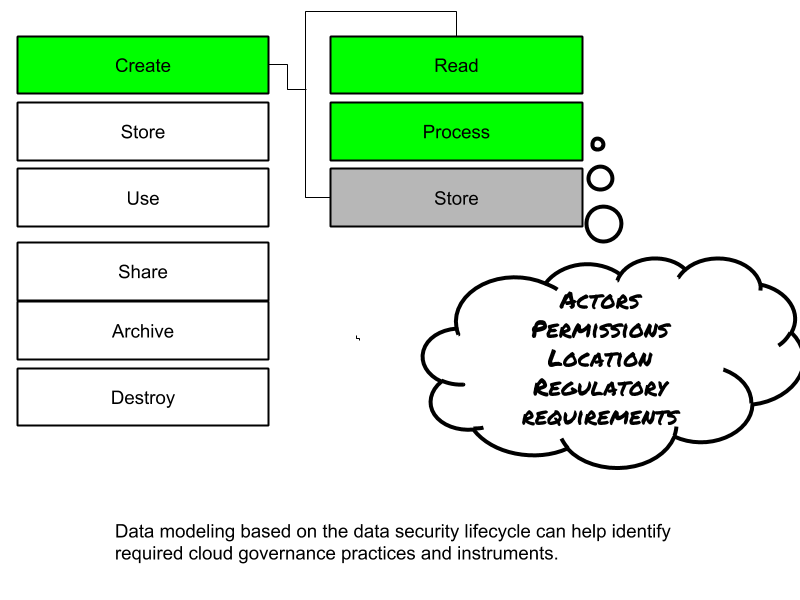
Data Security Lifecycle
A data security lifecycle is typically different from information lifecycle. A data security lifecycle has 6 phases:
Create: generation of new digital content, or modification of existing content
Store: committing digital data to storage, typically happens in direct sequence with creation.
Use: data is viewed, processed or otherwise used in some activity that does not include modification.
Share: Information is made accessible to others, such as between users, to customers, and to partners or other stakeholders.
Archive: data leaves active use and enters long-term storage. This type of storage will typically have much longer retrieval times than data in active storage.
Destroy. Data is permanently destroyed by physical or digital means (cryptoshredding)
The data security lifecycle is a description of phases the data passes through, without regard for location or how it is accessed. The data typically goes through “mini lifecycles” in different environments as part of these phases. Understanding the physical and logical locations of data is an important part of regulatory compliance.
In addition to where data lives and how it is transferred, it is important to keep control of entitlements; who accesses the data, and how can they access it (device, channels)? Both devices and channels may have different security properties that may need to be taken into account in a data governance plan.
Functions, actors and controls
The next step in assessing the data security lifecycle is to review what functions can be performed with the data, by a given actor (personal or system account) and a particular location.
There are three primary functions:
Read the data: including creating, copying, transferring.
Process: perform transactions or changes to the data, use it for further processing and decision making, etc.
Store: hold the data (database, filestore, blob store, etc)
The different functions are applicable to different degrees in different phases.
An actor (a person or a system/process – not a device) can perform a function in a location. A control restricts the possible actions to allowed actions. The key question is:
What function can which actor perform in which location on a given data object?
An example of data modeling connecting actions to data security lifecycle stages.
CSA Recommendations
The CSA has created a list of recommendations for information governance in the cloud:
Determine your governance requirements before planning a transition to cloud
Ensure information governance policies and practices extent to the cloud. This is done with both contractual and security controls.
When needed, use the data security lifecycle to model data handling and controls.
Do not lift and shift existing information architectures to the cloud. First, review and redesign the information architecture to support the current governance needs, and take anticipated future requirements into account.
This section on the CCSK domains is about compliance management and audits. This section goes through in some detail aspects one should think about for a compliance program when running services in the cloud. The key issues to pay attention to are:
Regulatory implications when selecting a cloud supplier with respect to cross-border legal issues
Assignment of compliance responsibilities
Provider capabilities for demonstrating compliance
Pay special attention to:
The role of provider audits and how they affect customer audit scope
Understand what services are within which compliance scope with the cloud provider. This can be challenging, especially with the pace of innovation. As an example, AWS is adding several new features every day.
Compliance
The key change to compliance when moving from an on-prem environement to the cloud is the introduction of a shared responsibility model. Cloud consumers must typically rely more on third-party auudit reports to understand compliance arrangement and gaps than they would in a traditional IT governance case.
Many cloud providers certify for a variety of standards and compliance frameworks to satisfy customer demand in various industries. Typical audit reports that may be available include:
PCI DSS
SOC1, SOC2
HIPAA
CSA CCM
GDPR
ISO 27001
Provider audits need to be understood within their limitations:
They certify that the provider is compliant, not any service running on infrastructure provided by that provider.
The provider’s infrastructure and operations is then outside of the customer’s audit scope, relying on pass-through audits.
To prove compliance in a servicec built on cloud infrastructure it is necessary that the internal parts of the application/service comply with the regulations, and that no non-compliant cloud services or components are used. This means paying attention to audit scopes is important when designing cloud architectures.
There are also issues related to jurisdictions involved. A cloud service typically will let you store and process data across a global infrastructure. Where you are allowed to do this depends on the compliance framework, and you as cloud consumer have to make the right choices in the management plane.
Audit Management
The scope of audits and audit management for information security is related to the fulfillment of defined information security practices. The goal is to evaluate the effectiveness of security management and controls. This extends to cloud environments.
Attestations are legal statements from a third party, which can be used as a statement of audit findings. This is a key tool when working with cloud providers.
Changes to audit management in cloud environments
On-premise audits on multi-tenant environments are seen as a security risk and typically not permitted. Instead consumers will have to rely on attestations and pass-through audits.
Cloud providers should assist consumers in achieving their compliance goals. Because of this they should publish certifications and attestations to consumers for use in audit management. Providers should also be clear about the scope of the various audit reports and attestations they can share.
Some types of customer technical assessments, such as vulnerability scans, can be liimted in contracts and require up-front approval. This is a change to audit management from on-prem infrastructures, although it seems most major cloud providers allow certain penetration testing activities without prior approval today. As an example, AWS has published a vulenrability anpenetration testing policy for customers here: https://aws.amazon.com/security/penetration-testing/.
In addition to audit reports, artifacts such as logs and documentation are needed for compliance proof. The consumer will in most cases need to set up the right logging detail herself in order to collect the right kind of evidence. This typically includes audit logs, activity reporting, system configuration details and change management details.
CSA Recommendations for compliance and audit management in the cloud
Compliance, audit and assurance should be continuous. They should not be seen as point-in-time activities but show that compliance is maintained over time.
Cloud providers should communicate audit results, certifications and attestations including details on scope, features covered in various locations and jurisdictions, give guidance to customers for how to build compliant services in their cloud, and be clear about specific customer responsibilities.
Cloud customer should work to understand their own compliance requirements before making choices about cloud providers, services and architectures. They should also make sure to understand the scope of compliance proof from the cloud vendor, and ensure they understand what artifacts can be produced to support the management of compliance in the cloud. The consumer should also keep a register of cloud providers and services used. CSA recommends the Cloud control matrix is used to support this activity (CCM).
Third-party access to documents stored in the cloud (e-discovery)
3.1 Overview
3.1.1 Legal frameworks governing data protection and privacy
Conflicting requirements in different jurisdictions, and
sometimes within the same jurisdiction. Legal requirements may vary according
to
Location of cloud provider
Location of cloud consumer
Location of data subject
Location of servers/datacenters
Legal jurisdiction of contract between the
parties, which may be different than the locations of those parties
Any international treaties between the locations
where the parties are located
3.1.1.1 Common themes
Omnibus laws: same law applicable across all sectors
Sectoral laws
3.1.1.2 Required security measures
Legal requirements may include prescriptive or risk based
security measures.
3.1.1.3 Restrictions to cross-border data transfer
Transfer of data across borders can be prohibited. The most
common situation is a based on transferring personal data to countries that do
not have “adequate data protection laws”. This is a common theme in the GDPR.
Other examples are data covered by national security legislation.
For personal data, transfers to inadequate locations may
require specific legal instruments to be put in place in order for this to be
considered compliant with the stricter region’s legal requirements.
3.1.1.4 Regional examples
Australia
Privacy act of 1988
Australian consumer law (ACL)
The privacy act has 13 Australian privacy principles (APP’s)
that apply to all sectors including non-profit organizations that have an
annual turnover of more than 3 million Australian dollars.
In 2017 the Australian privacy act was amended to require
companies to notify affected Australian residents and the Australian
Information Commissioner of breaches that can cause serious harm. A security
breach must be reported if:
There is unauthorized access or disclosure of
personal information that can cause serious harm
Personal information is lost in circumstances
where disclosure is likely and could cause serious harm
The ACL protects consumers from fraudulent contracts and
poor conduct from service providers, such as failed breach notifications. The
Australian Privacy Act can apply to Australian customers/consumers even if the
cloud provider is based elsewhere or other laws are stated in the service
agreement.
China
China has introduced new legislation governing information
systems over the last few years.
2017: Cyber security law: applies to critical
information infrastructure operators
May 2017: Proposed measures on the security of
cross-border transfers of personal information and important data. Under
evaluation for implementation at the time of issue of CCSP guidance v. 4.
The 2017 cybersecurity law puts requirements on
infrastructure operators to design systems with security in mind, put in place
emergency response plans and give access and assistance to investigating
authorities, for both national security purposes and criminal investigations.
The Chinese security law also requires companies to inform
users about known security defects, and also report defects to the authorities.
Regarding privacy the cybersecurity law requires that
personal information about Chinese citizens is stored inside mainland China.
The draft regulations on cross-border data transfer issued
in 2017 go further than the cybersecurity law.
New security assessment requirements for
companies that want to send data out of China
Expanding data localization requirements (the
types of data that can only be stored inside China)
Japan
The relevant Japanese legislation is found in “Act on the
Protection of Personal Information (APPI). There are also multiple sector
specific laws.
Beginning in 2017, amendments to the APPI require consent of
the data subject for transfer of personal data to a third party. Consent is not
required if the receiving party operates in a location with data protection
laws considered adequate by the Personal Information Protection Commission.
ePrivacy specifically covers electronic
communications. It is evolved from the 2002 ePrivacy directive that focused
primarily on email and sms, whereas the new version will cover electronic communications
in general, including data communication with IoT devices and the use of social
media platforms. The ePrivacy directive will also cover metadata about private
communications.
ePrivacy includes non-personal data. The focus is
on confidentiality of communications, that may also contain non-personal data
and data related to a legal person.
The have different legal precedents. GDPR is
based on Article 8 in the European Charter of Human Rights, whereas the ePrivacy
directive is based on Article 16 and Article 114 of the Treaty on the
Functioning of the European Union – but also Article 7 of the Charter of
Fundamental Rights: “Everyone has the right to respect for his or her private
and family life, home and communications.”
The CSA guidance gives a summary of GDPR requirements:
Data processors must keep records of processing
Data subject rights: data subjects have a right
to information on how their data is being processed, the right to object to
certain uses of their personal data, the right to have data corrected or
deleted, to be compensated for damages suffered as a result of unlawful
processing, and the right to data portability. These rights significantly affect
cloud relationships and contracts.
Security breaches: breaches must be reported to authorities
within 72 hours and data subjects must be notified if there is a risk of serious
harm to the data subjects
There are country specific variations in some
interpretations. For example, Germany required that an organization has a data
protection officer if the company has more than 9 employees.
Sanctions: authorities can use fines up to 4% of
global annual revenue, or 20 million EUR for serious violations, whichever
amount is higher.
EU: Network information security directive
The NIS directive is enforced since May 2018. The directive
introduces a framework for ensuring confidentiality, integrity and availability
of networks and information systems. The directive applies to critical infrastructure
and essential societal and financial functions. The requirements include:
Take technical and organizational measures to
secure networks and information systems
Take measures to prevent and minimize impact of
incidents, and to facilitate business continuity during severe incidents
Notify without delay relevant authorities
Provide information necessary to assess the
security of their networks and information systems
Provide evidence of effective implementation of
security policies, such as a policy audit
The NIS directive requires member states to impose security
requirements on online marketplaces, cloud computing service providers and
online search engines. Digital service providers based outside the EU but that
supply services within the EU are under scope of the directive.
Note: parts of these requirements, in particular for
critical infrastructure, are covered by various national security laws. The
scope of the NIS directive is broader than national security and typically
requires the introduction of new legislation. This work is not yet complete
across the EU/EEC area. Digital Europe has an implementation tracker site set
up here: https://www.digitaleurope.org/resources/nis-implementation-tracker/.
Central and South America
Data protection laws are coming into force in Central and
South American countries. They include security requirements and the need for a
data custodian.
North America: United States
The US has a sectoral approach to legislation with hundreds
of federal, state and local regulations. Organizations doing business in the
United States or that collect or process data on US residents or often subject
to multiple laws, and identification of the regulatory matrix can be challenging
for both cloud consumers and providers.
Federal law
The Gramm-Leach-Bliley Act (GLBA)
The Health Insurance Portability and
Accountability Act, 1996 (known as HIPAA)
The Children’s Online Privacy Protection Act of
1998 (COPPA)
Most of these laws require companies to take precautions
when hiring subcontractors and service providers. They may also hold organizations
responsible for the acts of subcontractors.
US State Law
In addition to federal regulations, most US states have laws
relating to data privacy and security. These laws apply to any entity that collect
or process information on residents of that state, regardless of where the data
is stored (the CSA guidance says regardless of where within the United States,
but it is likely that they would apply to international storage as well in this
case).
Security breach disclosure requirements
Breach disclosure requirements are found in multiple regulations.
Most require informing data subjects.
Knowledge of these laws is important for both cloud
consumers and providers, especially to regulate the risk of class action lawsuits.
In addition to the state laws and regulations, there is the “common
law of privacy and security”, a nickname given to a body of consent orders
published by federal and state government agencies based on investigations into
security incidents.
Especially the FTC (Federal Trade Commission) has for almost
20 years the power to conduct enforcement actions against companies whose
privacy and security practices are inconsistent with claims made in public
disclosures, making their practices “unfair and deceptive”. For cloud computing
this means that when a certain way of working changes, the public documentation
of the system needs to be updated to make sure actions are not in breach of
Section 4 of the FTC Act.
1.3.2 Contracts and Provider Selection
In addition to legal requirements, cloud consumers may have
contractual obligations to protect the personal data of their own clients,
contacts or employees, such as securing the data and avoiding other processing
that what has been agreed. Key documents are typically Terms and Conditions and
Privacy Policy documents posted on websites of companies.
When data or operations are transferred to a cloud, the
responsibility for the data typically remains with the collector. There may be
sharing of responsibilities when the cloud provider is performing some of the operations.
This also depends on the service model of the cloud provider. In any case a
data processing agreement or similar contractual instrument should be put in
place to regulate activities, uses and responsibilities.
3.1.2.1 Internal due diligence
Prior to using a cloud service both parties (cloud provider
and consumer) should identify legal requirements and compliance barriers.
Cloud consumers should investigate whether it has entered
into any confidentiality agreements or data use agreements that could limit the
use of a cloud service. In such cases consent from the client needs to be in
place before transferring data to a cloud environment.
3.1.2.3 External due diligence
Before entering into a contract, a review of the other party’s
operations should be done. For evaluating a cloud service, this will typically
include a look at the applicable service level, end-user and legal agreements,
security policies, security disclosures and compliance proof (typically an
audit report).
3.1.2.4 Contract negotiations
Cloud contracts are often standardized. An important aspect
is the regulation of shared responsibilities. Contracts should be reviewed
carefully also when they are presented as “not up for negotiation”. When certain
contractual requirements cannot be included the customer should evaluate if
other risk mitigation techniques can be used.
3.1.2.5 Reliance on third-party audits and attestations
Audit reports could and should be used in security
assessments. The scope of the audit should be considered when used in place of
a direct audit.
There have been many examples of litigants having deleted or
lost evidence that caused them to lose the case and be sentenced to pay damages
to the party not causing the data destruction. Because of this it is necessary
that cloud providers and consumers plan for how to identify and extract all relevant
documents relevant to a case.
3.1.3.1 Possession, custody and control
In most US jurisdictions, the obligation to produce relevant
information to court is limited to data within its possession, custody or
control. Using a cloud provider for storage does not remove this obligation.
Some data may not be under the control of the consumer (disaster recovery,
metadata), and such data can be relevant to a litigation. The responsibility of
a cloud provider to provide such data remains unclear, especially in
cross-border/international cases.
Recent cases of interest:
Norwegian police against Tidal regarding
streaming fraud
FBI against Microsoft (Ireland Onedrive case)
3.1.3.2 Relevant cloud applications and environment
In some cases, a cloud application or environment itself
could be relevant to resolving a dispute. In such circumstances the artefact is
likely to be outside the control of the client and require a discovery process
to served on the cloud provider directly, where such action is enforceable.
3.1.3.3 Searchability and e-discovery tools
Discovery may not be possible using the same tools as in traditional
IT environments. Cloud providers do sometimes provide search functionality, or
require such access through a negotiated cloud agreement.
3.1.3.4 Preservation
Preservation is the avoidance of destruction of data relevant
to a litigation, or that is likely to be relevant to a litigation in the
future. There are similar laws on this in the US, Europe, Japan, South Korea
and Singapore.
3.1.3.5 Data retention laws and record keeping obligations
Data retention requirements exist for various types of data.
Privacy laws put restrictions on retention. In the case of conflicting requirements
on the same data, this should be resolved through guidance and case law. Storage
requirements should be weighed against SLA requirements and costs when using
cloud storage.
Scope of preservation: a requesting party
is only entitled to data hosted in the cloud that contains data relevant to the
legal issue at hand. Lack of granular identifiability can lead to a requirement
to over-preserve and over-share data.
Dynamic and shared storage: the burden of
preserving data in the cloud can be relevant if the client has space to hold it
in place, if the data is static and the people with access is limited. Because
of the elastic nature of cloud environments this is seldom the case in practice
and it may be necessary to work with the cloud provider on a plan for data
preservation.
Reasonable
integrity: when subject to a discovery process, reasonable steps should be
taken to secure the integrity of data collection (complete, accurate)
Limits
to accessibility: if a cloud customer cannot access all relevant data in
the cloud. The cloud consumer and provider may have to review the relevance of
the request before taking further steps to acquire the data.
3.1.3.7 Direct access
Outside cloud environments it is not common to give the
requesting party direct access to an IT environment. Direct hardware access in
cloud environments if often not possible or desirable.
3.1.3,8 Native production
Cloud providers often store data in proprietary systems that
the clients do not control. Evidence is typically expected to be delivered in
the form of PDF files, etc. Export from the cloud environment may be the only
option, which may be challenging with respect to the chain of custody.
3.1.3.9 Authentication
Forensic authentication of data admitted into evidence. The
question here is whether the document is what it seems to be. Giving guarantees
on data authenticity can be hard, an a document should not inherently be considered
more or less admissible due to storage in the cloud.
3.1.3.10 Cooperation between provider and client in e-discovery
e-Discovery cooperation should preferably be regulated in
contracts and be taken into account in service level agreements.
3.1.3.11 Response to a subpoena or search warrant
The cloud agreement should include provisions for
notification of a subpoena to the client, and give the client time to try to
fight the order.
3.2 Recommendations
The CSA guidance makes the following recommendations
Cloud customers should understand relevant legal
and regulatory frameworks, as well as contractual requirements and restrictions
that apply to handling of their data, and the conduct of their operations in
the cloud.
Cloud providers should clearly disclose
policies, requirements and capabilities, including its terms and conditions
that apply to the services they provide.
Cloud customers should perform due diligence
prior to cloud vendror selection
Cloud customers should understand the legal
implications of the location of physical operations and storage of the cloud
provider
Cloud customers should select reasonable
locations for data storage to make sure they comply with their own legal requirements
Cloud customers should evaluate and take e-discovery
requests into account
Cloud customers should understand that click-through
legal agreements to use a cloud service do not negate requirements for a
provider to perform due diligence