
Failure rates for critical components are difficult to trust. Basically, if we look at public sources for data, such as the OREDA handbook, we observe that typical components have very wide confidence intervals for estimated failure rates, in spite of 30 years of collecting these data. If we look at the data supplied by vendors, they simply avoid saying anything about the spread or uncertainty in their data. Common practice today is to measure SIL compliance based on vendor supplied data, after a sanity check by the analyst. The sanity check usually consists of comparing with other data sources, and basically looking for completely ridiculous reliability claims. When coming to the operational phase it then becomes interesting to compare actual performance with the promised performance of the vendor. Typically, the actual performance is 10 to 100 times worse than promised. Because these components provide important parts of the barriers against terrible accidents, operators are also interested in measuring the actual integrity of these barriers. One possible method for doing this is given in the SINTEF report A8788, called “Guidelines for follow-up of safety instrumented systems (SIS) in operations”. For details, you should read that report but here’s the basics of what the report recommends for updating failure rates:
- If you have more than 3 million operating hours for a particular type of item, you can calculate the expected failure rate as “failures observed divided by number of hours of operation” and give a confidence interval based on the chi-square-distribution
- If you have less than 3 million operating hours but you have observed dangerous undetected failures (most likely during testing) you can combine the a priori design failure rate with an operational knowledge.
Let’s look at how to combine failure rates: first, you have to give some conservative estimate of the “true failure rate” as a basis for the combination. This is used to say something about the uncertainty in the original estimate. From OREDA one can observe that the upper 90% confidence bound is often around 2 times the failure rate value, so if no better estimate is available, use this. For very low reliability claims, use 5 x 10-7 (lower than that seems too optimistic in most cases). Then calculate the following parameters:

where λDU-CE is the conservative estimate and λDU is the design failure rate. Then, the combined failure rate can be estimated as
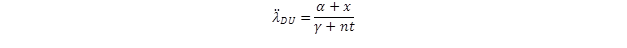
where is the number of similar items and is the number operational hours.
The SINTEF method does not give formulas for a confidence bound for the combined rate, but we may assume this will be between zero and the conservative estimate (which does not tell us too much, really). For the rate based on pure operational data we can use standard formulas for this. Consider now a case with about 75 transmitters with a design failure rate of 5 x 10-7 failures per hour. Over a 30-year simulated operational period we would expect approximately 10 failures. Injecting 10 failures at random intervals yields interesting results in a simulated case:

Note that up to 3 million operational hours we have assumed the design rate (PDS value) is governing uncertainty. Note also for infrequent failures, the confidence bands and the failure rate estimated is heavily influenced by each failure observation. We should thus be very careful with updating operational practices directly based on a few failure observations.










